This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog will demonstrate how to set up and benchmark the end-to-end performance of the training process. Architecture. The typical process of using Alluxio to accelerate machine learning and deep learning training includes the following three steps:
Recently there has been some discussions around service mesh benchmark tests. In a microservice architecture, this feature is more important than ever before. We are evaluating Netifi RSocket broker, and I think it would be nice to get a sense on the performance of RSocket broker using the same Istio setup.
Architecturally, the Istio Ambient mesh is a great design that improves performance. Since there are many promotions about Ambient mesh being production-ready, many of our prospects and enterprises are generally eager to try or migrate to Ambient mesh. But whether it performs quickly is still a question.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. Instead, they can ensure that services comport with the pre-established benchmarks. SLOs improve software quality.
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Migration is time-consuming and involved. create a microservice; 2.
According to IBM , application modernization takes existing legacy applications and modernizes their platform infrastructure, internal architecture, or features. Document and benchmark existing applications, processes, and services. Why should organizations modernize applications? However, each modernization effort is different.
I believe that all optimizing C/C++ compilers know how to pull this trick and it is generally beneficial irrespective of the processor’s architecture. We also published our benchmarks for research purposes. I make my benchmarking code available. The idea is not novel and goes back to at least 1973 (Jacobsohn).
ScaleGrid for PostgreSQL is architectured to leverage-high performance SSD disks on DigitalOcean, and is finely tuned and optimized to achieve the best performance on DigitalOcean infrastructure. PostgreSQL Benchmark Setup. Benchmark Tool. PostgreSQL Version. Scaling Factor. Query Mode. Number of Clients. Number of Threads.
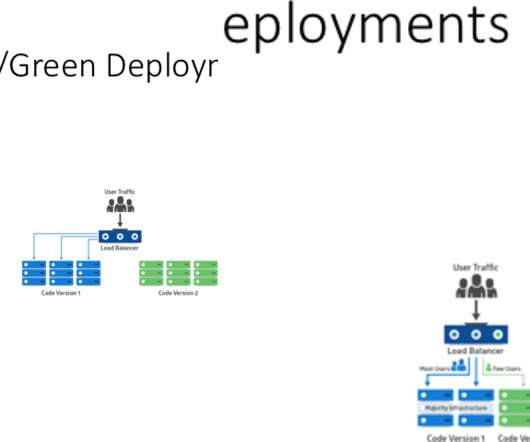
In the past, monolith architectures could only be implemented with big bang deployments which result in a slow pace of innovation and significant downtime. Using the Davis assistant for comparison and benchmarking. From big bang to progressive deployments. My session will cover various options, such as: Tagging different deployments.
This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language. One, by researching on the Internet; Two, by developing small programs and benchmarking. Most of us, as we spend years in our jobs — tend to be proficient in at least one of these.
Additionally, teams should perform continuous audits to evaluate data against benchmarks and implement best practices for ensuring data quality. Modern, cloud-native architectures have many moving parts, and identifying them all is a daunting task with human effort alone.
In the second approach, we show that a relatively simple, supervised sequential model (bidirectional LSTM or GRU) that uses rich, pretrained shot-level embeddings can outperform the current state-of-the-art baselines on our internal benchmarks. Figure 1: a scene consists of a sequence of shots.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. See more fault recovery experiments and insights in our full paper.
While this may work for monolithic applications or environments with infrequent releases, this simply does not scale for today’s modern cloud-native environments that are based on microservices-based architectures where new releases occur more frequently from days to hours to minutes. Automating release validation.
Spiraling cloud architecture and application costs have driven the need for new approaches to cloud spend. Additionally, include benchmarks for stakeholders and best practices that support the anticipated growth of the organization as a whole. Further, a Flexera report found that small to medium-sized businesses spend approximately $1.2
Five-nines availability: The ultimate benchmark of system availability. They also need a way to track all the services running on their distributed architectures, from multicloud environments to the edge. But is five nines availability attainable? Each decimal point closer to 100 equals higher uptime. What is always-on infrastructure?
For more information, read our guide on how data lakehouse architectures store data insights in context. Additionally, software analytics enhances the digital customer experience by enabling faster service for high-quality offerings. The post What is software automation?
AI-assistance: Use AI to detect anomalies and benchmark your system. Cloud-native architectures: Support for containers and serverless, including open standard like OpenTelementary, Prometheus, StatsD and Telegraf. This will allow your IT team to focus on what matters – proactive action, innovation, and business results.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. In summary, this model was a tightly-coupled application-to-data architecture, where machine learning algos were mixed with the backend and UI/UX software code stack.
To evaluate and benchmark our dataset, we manually labeled 20 audio tracks from various TV shows which do not overlap with our training data. We adapted the SOTA convolutional recurrent neural network ( CRNN ) architecture to accommodate our requirements for input/output dimensionality and model complexity.
Choosing a cloud DBMS: architectures and tradeoffs Tan et al., use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. in the TPC-H Benchmark Standard for details of the queries). VLDB’19. System initialisation time.
So, a well architected Lambda architecture can save a lot of costs. These served as our benchmark when creating our Lambda monitoring extension. On top of this, Lambda functions are billed strictly on a consumption basis. This means that there are zero costs incurred while a Lambda function isn’t running.
So, a well-architected Lambda architecture can save a lot of costs. These served as our benchmark when creating our Lambda monitoring extension. On top of this, Lambda functions are billed strictly on a consumption basis. This means that there are zero costs incurred while a Lambda function isn’t running.
Martin Sústrik : Philosophers, by and large, tend to be architecture astronauts. Programmers' insight is that architecture astronauts fail. JavaScript benchmark. And the sense that you have to be here or you can’t play is going to start diminishing. It's the fastest device I've ever tested. How does Apple do it?!
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Distributing accounts across the infrastructure is an architectural decision, as a given account often has similar usage patterns, languages, and sizes for their Lambda functions. When we set out to create the new Lambda extension, we benchmarked other dedicated Lambda monitoring solutions that were already on the market.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. Next generation architectures will use CXL3.0 petaflops, which is 0.8% of peak capacity.
More than half (51%) of SREs say they dedicate significant time to influencing architectural design decisions to improve reliability. SREs must be free to challenge accepted norms and set new benchmarks for innovation-led design and engineering practices. A shift to SRE-driven engineering takes hold.
In this article, we’ll briefly outline the use-case for a library like Donkey and present our benchmarks. Donkey is the product of the quest for a highly performant Clojure HTTP stack aimed to scale at the rapid pace of growth we have been experiencing at AppsFlyer, and save us computing costs. By Yaron Elyashiv.
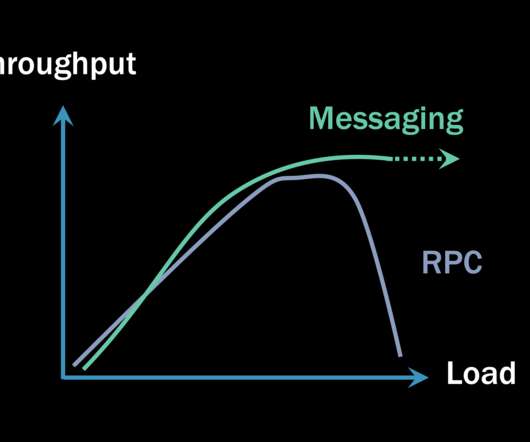
Why RPC is “faster” It’s tempting to simply write a micro-benchmark test where we issue 1000 requests to a server over HTTP and then repeat the same test with asynchronous messages. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
When planning your database HA architecture, the size of your company is a great place to start to assess your needs. This base architecture keeps the database available for your applications in case the primary node goes down, whether that involves automatic failover in case of a disaster or planned switchover during a maintenance window.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. However, Redis, with its single-threaded architecture, may encounter bottlenecks with large numbers of concurrent connections.
Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench. The illustrations below are taken from Percona Monitoring and Management (PMM) while running this benchmark. Analyzing read/write workload by counts.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 on CentOS 7, both of them spec’d with four vCPUs but with the second one (server B) having a tad over twice as much memory than the reference one (server A).
This includes all architectures, all compilers, all operating systems, and all system configurations. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. Experiment with different neural network architectures.
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers. Stateful JavaScript Apps. Generous free tier.
This guide to HammerDB concepts and architectures is aimed at helping you understand how HammerDB is built and how it can be extended and modified. It should now be clear that HammerDB is a simple and modular application yet extremely powerful and high performance because of the multi-threaded architecture and design.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content