This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing. This article explores the concepts of Medallion Architecture and demonstrates how to implement batch and stream processing pipelines using Azure Databricks and Delta Lake.
Cloud platforms (AWS, Azure, GCP, etc.) Integrations: Can work across multi-cloud and hybrid-cloud environments, such as AWS, Azure, and Google Cloud Platform, and provide unified visibility and management. If you’re using native Kubernetes, or K8s in AWS EKS, Azure AKS, Google GKE, or on-prem (e.g.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
As adoption rates for Azure continue to skyrocket, Dynatrace is developing a deeper integration with the Azure platform to provide even more value to organizations that run their businesses on Microsoft Azure or have Microsoft as a part of their multi-cloud strategy. Dynatrace news. Deeper visibility and more precise answers.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. AI-powered automation and deep, broad observability for serverless architectures. Dynatrace news. New to Dynatrace?
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. FaaS vs. monolithic architectures. Monolithic architectures were commonplace with legacy, on-premises software solutions. But how does FaaS fit in?
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Architecture. Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Sending and receiving messages from other users.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Unlike data warehouses, however, data is not transformed before landing in storage.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new Logs app.
.” Once data reaches an organization’s secure tenant in the software as a service (SaaS) cluster, teams can “also can exclude certain types of data with ease of configuration and strong defaults at storage in Grail [the Dynatrace data lakehouse that houses data],” added Ferguson. Why perform exclusion at two points?
DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks. There is no need to think about schema and indexes, re-hydration, or hot/cold storage.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes.
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. In contrast to modern software architecture, which uses distributed microservices, organizations historically structured their applications in a pattern known as “monolithic.”
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. For such workloads, shared-nothing architectures beget high cost, inflexibility, poor performance, and inefficiency, which hurts production applications and cluster deployments. joins) during query processing. Disaggregation (or not).
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Cloud-hosted Kubernetes clusters are on par to overtake on-premises deployments in 2023.
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
Problems include provisioning and deployment; load balancing; securing interactions between containers; configuration and allocation of resources such as networking and storage; and deprovisioning containers that are no longer needed. How does container orchestration work? The post What is container orchestration?
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
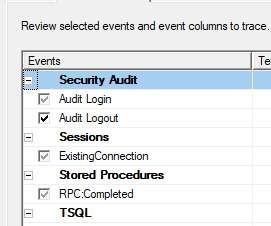
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Unfortunately, my excitement was short lived for a couple of reasons.
Microsoft has recently unveiled several new features for Azure Cosmos DB to enhance cost efficiency, boost performance, and increase elasticity. These features are burst capacity, hierarchical partition keys, serverless container storage of 1 TB, and priority-based execution. By Steef-Jan Wiggers
” In recent years, cloud service providers such as Amazon Web Services, Microsoft Azure, IBM, and Google began offering Kubernetes as part of their managed services. Without having to worry about underlying infrastructure concerns, such as storage, security, and lifecycle management, developers can focus on writing code.
Across the cloud operations lifecycle, especially in organizations operating at enterprise scale, the sheer volume of cloud-native services and dynamic architectures generate a massive amount of data. In general, generative AI can empower AWS users to further accelerate and optimize their cloud journeys.
Azure SQL Database is Microsoft's database-as-a-service offering that provides a tremendous amount of flexibility. Microsoft is continually working on improving their products and Azure SQL Database is no different. Microsoft is continually working on improving their products and Azure SQL Database is no different. GB per vCore.
PostgreSQL & Elastic for data storage. MaaSS for Cloud Architects: Deployment and Architecture Validations. Validate correct architecture, configuration and deployment by looking at Service Flow! Their technology stack looks like this: Spring Boot-based Microservices. NGINX as an API Gateway. REDIS for caching.
AWS is far and away the cloud leader, followed by Azure (at more than half of share) and Google Cloud. But most Azure and GCP users also use AWS; the reverse isn’t necessarily true. However, close to half (~48%) use Microsoft Azure, and close to one-third (~32%) use Google Cloud Platform (GCP).
JoeEmison : Another thing that serverless architectures change: how do you software development. The end of Dennard Scaling and Moore's Law means architecture is where we have to innovate to improve performance, cost, and energy. Domain Specific Architectures are getting 20x and 40x improvements, not just 5-10%.
The architecture usually integrates several private, public, and on-premises infrastructures. Key Components of Hybrid Cloud Infrastructure A hybrid cloud architecture usually merges a public Infrastructure-as-a-Service (IaaS) platform with private computing assets and incorporates tools to manage these combined environments.
The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes. Acting as a switchboard for incoming and outgoing messages, Azure IoT Hub forms the core of these capabilities.
Self-hosted Kubernetes installations or services — such as Amazon EKS, Azure Kubernetes Service, or the Google Kubernetes Engine — make it possible for enterprises to select and implement best-fit functions. Microservices architecture combines loosely-coupled functions to create high-performing applications.
There are several popular cloud-based platforms for web development and deployment, such as AWS , Azure , and Google Cloud Platform. Each of these platforms offers a wide range of services and tools for web application development and deployment, including storage, databases, and serverless computing.
Like ScaleGrid’s offerings for multi-cloud architecture compatibility, its solutions are well-suited for use within a single cloud provider or a hybrid cloud setup as well. Firstly, let’s take a look at Spotify’s implementation of the multi-cloud approach before exploring Netflix’s adoption of a hybrid cloud architecture.
Architecture Operator SDK is now used to build and package the Operator. In addition to that: Run up to four pgBackrest repositories Bootstrap the cluster from the existing backup through Custom Resource Azure Blob Storage support Operations Deploying complex topologies in Kubernetes is not possible without affinity and anti-affinity rules.
Release highlights include: Docker images are now available for x86_64 architectures. Download Percona Distribution for PostgreSQL 16.1 Percona Distribution for PostgreSQL 15.5 Percona Distribution for PostgreSQL 15.5 was released on November 30, 2023. This release of Percona Distribution for PostgreSQL is based on PostgreSQL 15.5.
For the inaugural O’Reilly survey on serverless architecture adoption, we were pleasantly surprised at the high level of response: more than 1,500 respondents from a wide range of locations, companies, and industries participated. The high response rate tells us that serverless is garnering significant mindshare in the community.
AI algorithms embedded in cloud architecture automate repetitive processes, streamlining workloads and reducing the chance of human error. With a multi-cloud architecture, Scalegrid offers the flexibility and competitive edge necessary for AI applications in the rapidly evolving tech environment.
Self-managed databases come with their own set of expenses that must be factored in – managing a database requires time and effort which often includes backup storage, patching software upgrades as well as other typical administration tasks. Advantages of DBaaS Database management with DBaaS is like being on a luxury cruise.
At ScaleGrid, we offer highly available hosting for MySQL on AWS and MySQL on Azure that is implemented based on the concepts explained in this blog series. This concludes our 3-part blog series on the MySQL High Availability (HA) framework using semisynchronous replication and the Corosync plus Pacemaker stack.
Today’s streaming analytics architectures are not equipped to make sense of this rapidly changing information and react to it as it arrives. Incoming data is saved into data storage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention.
Disk-level encryption is a security measure that encrypts all data stored on a disk or storage device. Disk-level encryption is a security measure that encrypts all data stored on a disk or storage device. Cluster-level encryption is a security measure that encrypts data stored in a cluster of servers or storage devices. .
We’ll also discuss the costs and benefits of CDNs and dedicated file storage solutions. Small projects benefit from simple architecture. First, you’ll need to install the libraries boto3 and django-storages. Instead, use django-storages with the AWS CLI to configure the keys, as described here. Option 1: Default Django.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content