This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace continues to deliver on its commitment to keeping your data secure in the cloud. Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. This has resulted in visibility gaps, siloed data, and negative effects on cross-team collaboration. At the same time, the number of individual observability and security tools has grown.
Azure observability and Azuredata analytics are critical requirements amid the deluge of data in Azure cloud computing environments. Dynatrace recently announced the availability of its latest core innovations for customers running the Dynatrace® platform on Microsoft Azure, including Grail.
This extension provides fully app-centric Cassandra performance monitoring for Azure Managed Instance for Apache Cassandra. Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. x runtime versions of Azure Functions running in an Azure App Service plan. Azure Functions in a nutshell. Azure Functions is the serverless computing offering from Microsoft Azure.
As organizations adopt microservices architecture with cloud-native technologies such as Microsoft Azure , many quickly notice an increase in operational complexity. To guide organizations through their cloud migrations, Microsoft developed the Azure Well-Architected Framework. What is the Azure Well-Architected Framework?
Some time ago, we announced monitoring coverage for all Azure Monitor services , as well as the ability to purchase the Dynatrace Software Intelligence Platform through the Microsoft Azure Marketplace. Now, Dynatrace and Microsoft have further deepened their partnership by making Dynatrace for Azure generally available.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
What is Azure Functions? Similar to AWS Lambda , Azure Functions is a serverless compute service by Microsoft that can run code in response to predetermined events or conditions (triggers), such as an order arriving on an IoT system, or a specific queue receiving a new message. The growth of Azure cloud computing.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. x runtime versions of Azure Functions running in an Azure App Service plan. Azure Functions in a nutshell. Azure Functions is the serverless computing offering from Microsoft Azure.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
As adoption rates for Microsoft Azure continue to skyrocket, Dynatrace is developing a deeper integration with the platform to provide even more value to organizations that run their businesses on Azure or use it as a part of their multi-cloud strategy. Azure Batch. Azure DB for MariaDB. Azure DB for MySQL.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Easy to leverage API interfaces connect services with core functionality, allowing applications to communicate and share data. Microservices benefits.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Easy to leverage API interfaces connect services with core functionality, allowing applications to communicate and share data. Microservices benefits.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse?
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. Let me start with the end-user impact.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
Modern IT organizations are generating more data from more tools and technologies than ever. Data is proliferating in separate silos from containers and Kubernetes to open source APIs and software to serverless compute services, such as AWS and Azure. However, they had numerous custom applications with separate APIs.
To drive better outcomes using hybrid cloud architectures, it helps to understand their benefits—and how to orchestrate them seamlessly. What is hybrid cloud architecture? Hybrid cloud architecture is a computing environment that shares data and applications on a combination of public clouds and on-premises private clouds.
Grail: Enterprise-ready data lakehouse Grail, the Dynatrace causational data lakehouse, was explicitly designed for observability and security data, with artificial intelligence integrated into its foundation. Tables are a physical data model, essentially the type of observability data that you can store.
Leveraging cloud-native technologies like Kubernetes or Red Hat OpenShift in multicloud ecosystems across Amazon Web Services (AWS) , Microsoft Azure, and Google Cloud Platform (GCP) for faster digital transformation introduces a whole host of challenges. Collecting data requires massive and ongoing configuration efforts.
VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines. Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud.
Lifting and shifting applications from the data center to the cloud delivers only marginal benefits. To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly?
A single indicator is defined as a query against a data source such as a monitoring, testing, security or code quality tool. Queries the results through the defined data sources (Prometheus & Dynatrace). Pitometer in Action: Queries data from different data sources, grades each and calculates an overall deployment score.
The key to success is making data in this complex ecosystem actionable, as many types of syslog producers exist. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. As teams begin collecting and working with observability data, they are also realizing its benefits to the business, not just IT. Dynatrace news.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes.
Data confirms Aggarwal’s conclusions. According to Forrester Research, the COVID-19 pandemic fueled investment in “hyperscaler public clouds”—Amazon Web Services (AWS), Google Cloud Platform and Microsoft Azure. The research estimated a 35% increase in public cloud usage in 2021 alone. Why modern observability is different.
The new Dynatrace Logs app, fully powered by Grail™ data lakehouse, significantly enhances the experience for novice and seasoned users. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new Logs app.
This blog post explores how AI observability enables organizations to predict and control costs, performance, and data reliability. It also shows how data observability relates to business outcomes as organizations embrace generative AI. GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues.
The rapidly evolving digital landscape is one important factor in the acceleration of such transformations – microservices architectures, service mesh, Kubernetes, Functions as a Service (FaaS), and other technologies now enable teams to innovate much faster. New cloud-native technologies make observability more important than ever….
With all the data readily accessible via the CI/CD tool vendor’s APIs, it’s easy to conclude that building a custom solution from scratch is straightforward. Additionally, security requirements such as data encryption both in transit and at rest need to be implemented. Normalization of data on ingest.
Existing siloed tools lead to inefficient workflows, fragmented data, and increased troubleshooting times. Rather than relying on disparate tools for each environment and team, Dynatrace integrates all data into one cohesive platform. As a result, dedicated data pipeline tools are unnecessary for preprocessing data before ingestion.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Big data : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
Hyperscale is the ability of an architecture to scale appropriately as increased demand is added to the system. That’s why it’s important to find ways to automate the influx of data hyperscalers bring. But what does that look like? What is hyperscale? Automatic and intelligent observability for hyperscale.
Architecture. from a client it performs two parallel operations: i) persisting the action in the data store ii) publish the action in a streaming data store for a pub-sub model. User Feed Service, Media Counter Service) read the actions from the streaming data store and performs their specific tasks. High Level Design.
Thanks to its event-driven architecture, Keptn can pull SLIs (=metrics) from different data sources and validate them against the SLOs. Currently supported data sources are Prometheus , Dynatrace , Neoload with others in the works, e.g. Wavefront.
Especially in dynamic microservices architectures, distributed tracing is an essential component of efficient monitoring, application optimization, debugging, and troubleshooting. The value of Davis, the Dynatrace AI causation engine, is built upon the quality of the data we collect. Dynatrace news. What is distributed tracing?
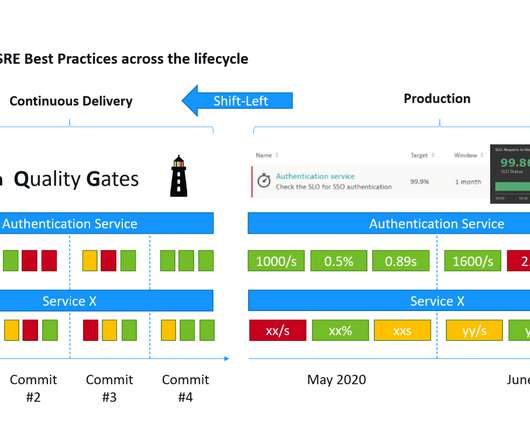
Example 1: Architecture boundaries. Due to the massive amount of data, no one knew what action to take if a number went red. First, they took a big step back and looked at their end-to-end architecture (Figure 2). SLO dashboard defined by architectural boundary. The dashboards are green, so why are users complaining?
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. These rapid changes — as well as the increasing volume and variety of data created — require a new approach to observability. How observability works in a traditional environment.
The growing challenge in modern IT environments is the exponential increase in log telemetry data, driven by the expansion of cloud-native, geographically distributed, container- and microservice-based architectures. Organizations need a more proactive approach to log management to tame this proliferation of cloud data.
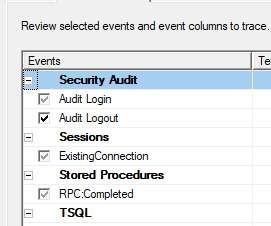
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Unfortunately, my excitement was short lived for a couple of reasons.
Popular examples include AWS Lambda and Microsoft Azure Functions , but new providers are constantly emerging as this model becomes more mainstream. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. Architectural complexity. Reduced latency. Difficult to monitor.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content