This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace. This solution aligns to the AWS Well-Architected Framework. group of companies.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The response schema for the observability endpoint.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention. Thus, all data in one region is processed by the Flink job deployed within thatregion.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Host-performance measures.
OpenTelemetry Astronomy Shop demo application architecture diagram. All the needed components are available out of the box in the OpenTelemetry collector contrib distribution, which is included in the demo application. Next, select one of the log lines to view the available attributes. Courtesy of the OpenTelemetry authors.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
Both categories share common requirements, such as high throughput and high availability. Eventually Consistent Global Counter While some users may accept the limitations of a Best-Effort counter, others opt for precise counts, durability and global availability.
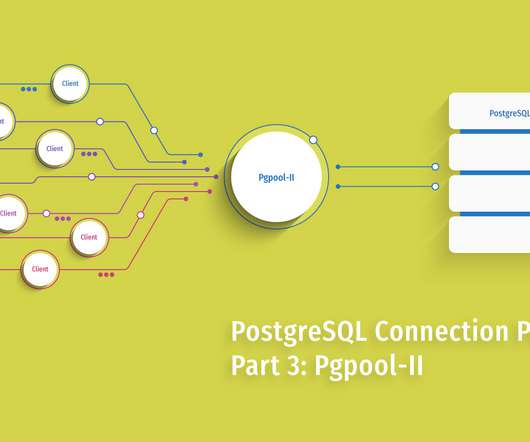
It supports high-availability, provides automated load balancing, and has the intelligence to balance load between masters and slaves so write loads are always directed at masters, while read loads are directed to slaves. Check out the Pgpool-II architecture that supports all of its features, and learn how the connection pooler works.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring. Dynatrace news.
With the availability of Linux on IBM Z and LinuxONE, the IBM Z platform brings a familiar host operating system and sustainability that could yield up to 75% energy reduction compared to x86 servers. You can now install OneAgent on Linux with s390 architecture. Next, set up log ingest.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. Recovery time of the latency p90. However, we noticed that GPT 3.5
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
The digital experiences that enable IT teams to do their best work — the experiences that are smooth, available, and fast — stem from the application development level. Want to learn more about how zero trust architecture can improve government user experiences? Tune in to the full episode to hear more from Gross on UX Ops.
However, setting the right parameters for Kubernetes clusters to ensure application availability, performance, and resilience while avoiding overspending isn’t a walk in the park. Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The Akamas approach. Additional resources.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience. First, we must provide the content that will bring them joy.
AI-powered automation and deep, broad observability for serverless architectures. This, in turn, helps DevOps teams to pinpoint common problem patterns in their serverless functions rather than in an event-driven architecture. Stay tuned for updates. 2 Automatic detected queues anomaly by AI engine Davis. New to Dynatrace?
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Dynatrace is thrilled to announce the General Availability of support for both the 2.x It allows for the breaking up of heavy monolithic architectures into multiple serverless “functions.” So stay tuned!
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Heterogeneous cloud-native microservice architectures can lead to visibility gaps in distributed traces. Dynatrace news. What’s next?
Also, these modern, cloud-native architectures produce an immense volume, velocity, and variety of data. Explore your logs in multicloud environments and analyze them in the context of your architecture. All Dynatrace enhancements mentioned in this blog post will be available to all Dynatrace customers within the next 90 days.
Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently. Every time the trigger executes, the function runs on an available resource.
The rapidly evolving digital landscape is one important factor in the acceleration of such transformations – microservices architectures, service mesh, Kubernetes, Functions as a Service (FaaS), and other technologies now enable teams to innovate much faster. Highest availability and security out-of-the-box.
I wanted to understand how I could tune Dynatrace’s problem detection, but to do that I needed to understand the situation first. For this visualization I used the same backend architecture as for the real-time visualization I presented previously. The raw event data is available via API just like the problem data as well.
On the application overview page you have an error overview available that shows you the errors of a particular web application over time, split by type, occurrence context, and origin. Stay tuned for Part 2. How to fix HTTP errors in 3 easy steps with Dynatrace. Step 1: Quantify the errors.
You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. Intelligent Monitoring Every service operator knows the difficulty of alert tuning. By Andrei U., A metric crossed a threshold.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. We anticipate massive growth in the popularity of this architecture in the coming quarters, driven additionally by companies’ push for cost reductions. Stay tuned for more details.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Dynatrace is thrilled to announce the General Availability of support for both the 2.x It allows for the breaking up of heavy monolithic architectures into multiple serverless “functions.” So stay tuned!
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Data Model At its core, the KV abstraction is built around a two-level map architecture.
In fact, we’ve found for our services and architecture that there is no such trade off. Operational simplicity Service owners often reach out to us with questions about excessive pause times and for help with tuning. No explicit tuning has been required to achieve these results.
Observability is a topic at the top of mind for all architects, Site Reliability Engineers (SREs), and more – each wanting to use observability to proactively detect issues and guarantee the best experience and availability to users. Metric 2 (Number of requests in error): It’s already available in the Dynatrace built-in metric.
High level playback architecture with priority throttling and chaos testing Building a request taxonomy We decided to focus on three dimensions in order to categorize request traffic: throughput, functionality, and criticality. The computation is done as a first step so that it is available for the rest of the request lifecycle.
This context switching makes it hard for teams to effectively connect the dots when it comes to integrating the service-specific insights with surrounding architecture components such as service-mesh data. A unified platform approach also makes OpenTelemetry data available to more teams across the organization for more diversified analysis.
The performance characteristics of the application are determined by its architecture and design. No amount of code fine-tuning can disguise the performance implications resulting from bad architecture or design decisions. Applications must be architected and designed with sound principles and best practices.
As organizations adopt microservices-based architecture , service-level objectives (SLOs) have become a vital way for teams to set specific, measurable targets that ensure users are receiving agreed-upon service levels. availability of a website over a year, your error budget is.05%. Dynatrace news. What are error budgets?
Now, that same full-spectrum value is available at the massive scale of the Dynatrace Grail data lakehouse. You’re getting all the architectural benefits of Grail—the petabytes, the cardinality—with this implementation,” including the three pillars of observability: logs, metrics, and traces in context. .
This article was co-authored by Eduardo da Silva and Nick Tune based on our individual and collective experiences. FThis article describes a pattern we have observed and applied in multi-team-scope architecture modernization initiatives, the Architecture Modernization Enabling Team (AMET).
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Log analysis can reveal potential bottlenecks and inefficient configurations so teams can fine-tune system performance. Dynatrace news. What are logs?
With the self-service features and an everything-as-code architecture, labor requirements will significantly decrease and SRE best practices will emerge. Design, implement, and tune effective SLOs. By removing physical dependencies, automation can help perform SRE at scale. Automate as much as possible.
The catalog of available DB connectors is growing (CockroachDB, Cassandra for example) More Processing patterns such as filter, projection, union, join, etc. Overall Architecture The Data Mesh system can be divided into the control plane (Data Mesh Controller) and the data plane (Data Mesh Pipeline). Please stay tuned!
Sample GraphQL Schema Once entities like the above are available in the graph, it’s very common for folks to want to query for a particular entity based on attributes of related entities, e.g. give me all movies that are currently in photography with Ryan Reynolds as an actor. Data Mesh streams are schematized with Avro.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content