This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Grafana Loki is a horizontally scalable, highly available log aggregation system. It is designed for simplicity and cost-efficiency. Created by Grafana Labs in 2018, Loki has rapidly emerged as a compelling alternative to traditional logging systems, particularly for cloud-native and Kubernetes environments.
This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation. The rapid evolution of cloud technology continues to shape how businesses operate and compete. This solution aligns to the AWS Well-Architected Framework.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The response schema for the observability endpoint.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x). Dynatrace is designed to scale easily across the entire Kubernetes stack.
We designed Auth0 from the beginning so that it could run anywhere: on our cloud, on your cloud, or even on your own private infrastructure. com and the strategies we use to keep it up and running with high availability. com and the strategies we use to keep it up and running with high availability.
Building the dream package Observability for Developers, the newly introduced offering from Dynatrace, is designed to cater to developers’ specific needs and challenges. Additionally, Dynatrace integrates relevant trace data, providing full visibility into complex, microservices-based architectures.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le).
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
In today's rapidly evolving technology landscape, it's common for applications to migrate to the cloud to embrace the microservice architecture. While this architectural approach offers scalability, reusability, and adaptability, it also presents a unique challenge: effectively managing communication between these microservices.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Load balancing is a critical component in cloud architectures for various reasons. What Is Load Balancing?
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. Spring Boot's default codes and annotation setup lessen the time it takes to design an application.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later.
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architecturaldesign. It’s based on cloud-native architecture and built for the cloud. But what does that mean?
Making Google’s CalDAV and CardDAV APIs available for everyone ( Google Developers Blog). Pandora launches new HTML5 site for TVs and gaming consoles, available now on PS3 and Xbox 360 ( The Next Web). Simpler UI Testing with CasperJS ( Architects Zone – ArchitecturalDesign Patterns & Best Practices). Hacker News).
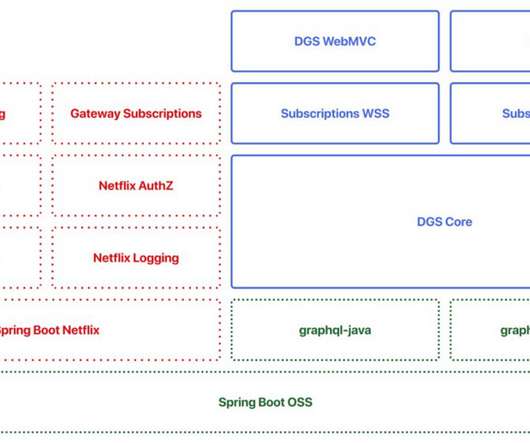
Our colleagues wrote a Netflix Tech Blog post describing the details of this architecture. The transition to the new federated architecture meant that many of our backend teams needed to adopt GraphQL in our Java ecosystem. Backward compatibility is even more critical when working in a Federated GraphQL architecture.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience. First, we must provide the content that will bring them joy.
FaaS vs. monolithic architectures. Monolithic architectures were commonplace with legacy, on-premises software solutions. Increased availability. Because FaaS is a cloud-native approach, it makes great use of multisite cloud architecture to improve availability and reliability. Increased testing complexity.
Performance testing does not essentially display imperfections with an app, yet it needs to ensure that the app function as expected despite the bandwidth availability, network fluctuations, or traffic overload. Therefore, designing and implementing such tests are crucial to ensure the stability of the website.
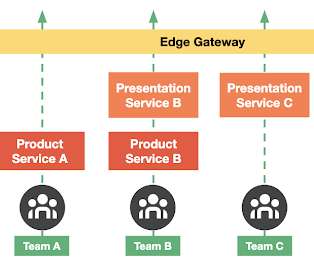
The making of Edge Gateway, the highly-available and scalable self-serve gateway to configure, manage, and monitor APIs of every business domain at Uber. In October 2014, Uber had started its journey of scale in what … The post Designing Edge Gateway, Uber’s API Lifecycle Management Platform appeared first on Uber Engineering Blog.
Introducing Metrics on Grail Despite their many advantages, modern cloud-native architectures can result in scalability and fragmentation challenges. For more complex cloud-native architectures, adding more services and applications leads to a massive increase in the volume of collected traces.
These are hard problems, and solving them requires breaking away from old-guard relational database architectures. Aurora's design preserves the core transactional consistency strengths of relational databases. Customers love this because Aurora provides the performance and availability of commercial grade databases at 1/10th the cost.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. The architects and developers who create the software must design it to be observed. Dynatrace news. Benefits of observability.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Unfortunately, using certain open source database software as part of an HA architecture can present significant challenges.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Options at each level offer significant potential benefits, especially when complemented by practices that influence the design and purchase decisions made by IT leaders and individual contributors.
These are hard problems, and solving them requires breaking away from old-guard relational database architectures. Aurora's design preserves the core transactional consistency strengths of relational databases. Since Aurora's original release, it has been the fastest-growing service in the history of AWS.
You are designing a learning system to forecast Service Level Agreement (SLA) violations and would want to factor in all upstream dependencies and corresponding historical states. Design a flexible data model ? —?Represent Therefore, the ingestion approach for data lineage is designed to work with many disparate data sources.
APIs are everywhere these days—from internal APIs that are used within your microservice architecture, third-party APIs that your software relies on, to external APIs that you offer to your customers. With the new page design, you can: Instantly understand the scope of problems with aggregated availability.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
As organizations adopt microservices architecture with cloud-native technologies such as Microsoft Azure , many quickly notice an increase in operational complexity. The Azure Well-Architected Framework is a set of guiding tenets organizations can use to evaluate architecture and implement designs that will scale over time.
Microsoft initially designed the OS for internal use to develop and manage Azure services. Today, it’s a generally available container host for AKS and AKS-HCI. Microsoft designed the kernel and other aspects of the OS with an emphasis on security due to its focused role in executing container workloads.
FThis article describes a pattern we have observed and applied in multi-team-scope architecture modernization initiatives, the Architecture Modernization Enabling Team (AMET). An AMET is a type of architecture enabling team that coordinates and upskills all teams and stakeholders in the modernization initiative.
Dynatrace recently announced the availability of its latest core innovations for customers running the Dynatrace® platform on Microsoft Azure, including Grail. Learn more about the latest product enhancements on Microsoft Azure as well as availability timing in the latest Dynatrace press release.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content