This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
As a result, organizations are implementing security analytics to manage risk and improve DevSecOps efficiency. Fortunately, CISOs can use security analytics to improve visibility of complex environments and enable proactive protection. What is security analytics? Why is security analytics important? Here’s how.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This decoupling simplifies system architecture and supports scalability in distributed environments.
By putting data in context, OpenPipeline enables the Dynatrace platform to deliver AI-driven insights, analytics, and automation for customers across observability, security, software lifecycle, and business domains. This “data in context” feeds Davis® AI, the Dynatrace hypermodal AI , and enables schema-less and index-free analytics.
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. Unlike data warehouses, however, data is not transformed before landing in storage. These include application programming interfaces, streaming, and more. Support diverse analytics workloads.
These items are a combination of tech business news, development news and programming tools and techniques. Email Reveals Google App Engine Search API About Ready For Preview Release, Charges Planned For Storage, Operations ( TechCrunch). These items are the fruits of those ideas, the items I deemed worthy from my Google Reader feeds.
Dynatrace, operated from Tokyo, addresses the data residency needs of the Japanese market Dynatrace operates its AI-powered unified platform for observability, security, and business analytics as a SaaS solution in 19 worldwide regions on three hyperscalers (AWS, Azure, and GCP). Government cloud services must use Japanese data centers.
Enterprise data stores grow with the promise of analytics and the use of data to enable behavioral security solutions, cognitive analytics, and monitoring and supervision. ” This data is excluded from storage, but teams can still gain value from data enrichment beforehand. Why perform exclusion at two points? Encryption.
Additionally, service meshes — such as those offered by Istio, Linkerd, and Consul Connect — help to manage internetwork communication at the platform layer using purpose-built application programming interfaces. Traditional storage solutions were not created to address these requirements, which are common among modern deployments.
Collect data automatically and pre-processed from a range of sources: application programming interfaces, integrations, agents, and OpenTelemetry. Historically, IT infrastructure performance, IT security, data architecture, and data analytics, have been managed in disparate, unconnected silos deep within IT organizational structures.
Major cloud providers such as AWS offer certification programs to help technology professionals develop and mature their cloud skills. AWS Certified Data Analytics – Specialty: Highly knowledgeable data analytics pros who have already worked with AWS for some time should consider getting this certification. Data analytics.
Dynatrace has developed the purpose-built data lakehouse, Grail , eliminating the need for separate management of indexes and storage. All data is readily accessible without storage tiers, such as costly solid-state drives (SSDs). No storage tiers, no archiving or retrieval from archives, and no indexing or reindexing.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Dynatrace makes it radically simple to ingest all the monitoring data you need by integrating with a wide variety of platforms, applications, programming languages, and data formats.
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Improved analytic context. While data analysis tools such as Google Analytics provide statistics based on user experiences, they lack details about what the user is doing and experiencing.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. And finally, we have an Apache Iceberg layer which stores assets in a denormalized fashion to help answer heavy queries for analytics use cases. It is also responsible for asset discovery, validation, sharing, and for triggering workflows.
In this blog, we share three log ingestion strategies from the field that demonstrate how building up efficient log collection can be environment-agnostic by using our generic log ingestion application programming interface (API). In the “Storage and Logging” section, select “ awsfirelens ” as the log driver.
According to the survey, the key challenges CIOs face in unlocking greater value from observability data include the unavailability of data for analytics on demand (56%), inability to keep the data that is deemed critical in hot storage due to the cost (40%), and centralizing log management because it is difficult and time-consuming (35%). .
The supported programming languages for PostgreSQL include.Net, C, C++, Delphi, Java, JavaScript (Node.js), Perl, PHP, Python and Tcl, but PostgreSQL can support many server-side procedural languages through its available extensions. We found that Java is the most popular programming language for PostgreSQL, being leveraged by 31.1%
GoSquared provides various analytics services that web and mobile companies can use to understand their customers' behaviors. At re:Invent 2016 , AWS announced Greengrass (in limited preview), a new service designed to extend the AWS programming model to small, simple, field-based devices. Fraud.net is a good example of this.
Additionally, its modern architecture delivers cost-effective storage and compute. As a result, teams benefit from low-cost cloud storage that provides access to all data and doesn’t require data rehydration. Teams can visualize an application’s vital signs, including its security posture. Site Reliability Guardian.
With these release candidate APIs available, instrumentation for web frameworks, storage clients, and much more can be built. For instance, we are working on OpenTelemetry metrics exporters for popular programming languages which will automatically tap into metrics exposed via OpenTelemetry instrumentation.
Expanding the Cloud - Amazon S3 Reduced Redundancy Storage. Today a new storage option for Amazon S3 has been launched: Amazon S3 Reduced Redundancy Storage (RRS). This new storage option enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy. Comments ().
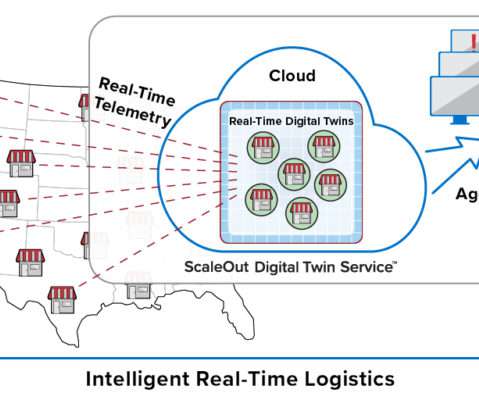
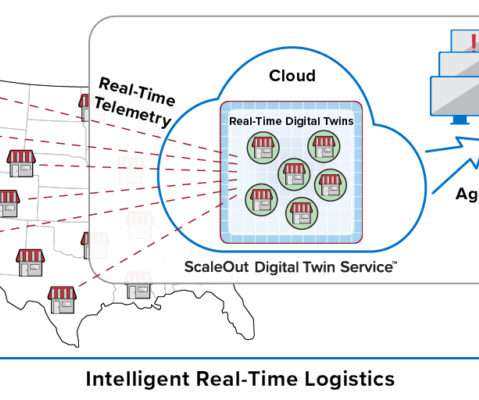
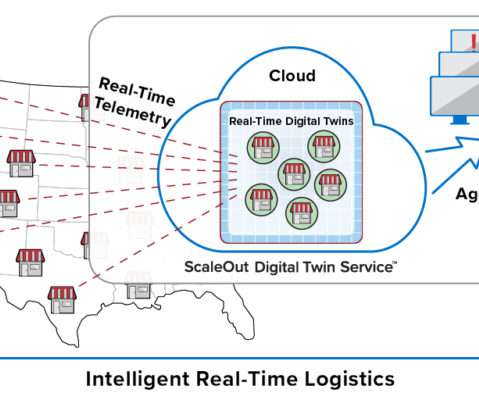
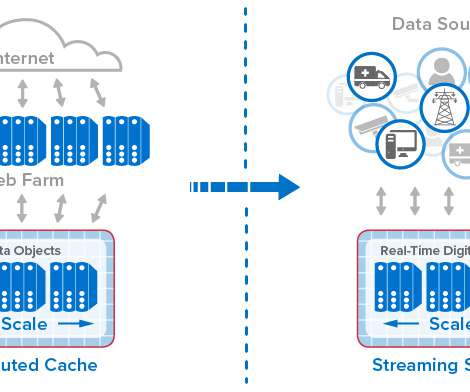
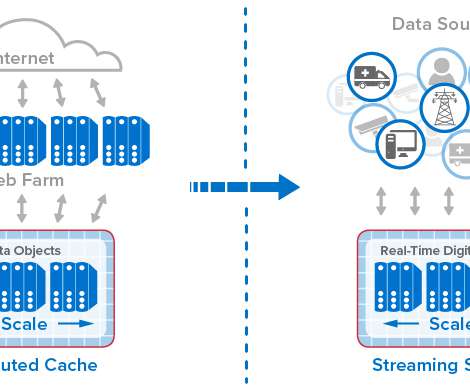
This model organizes key information about each data source (for example, an IoT device, e-commerce shopper, or medical patient) in a software component that tracks the data source’s evolving state and encapsulates algorithms, such as predictive analytics, for interpreting that state and generating real-time feedback.
We believe that making these GPU resources available for everyone to use at low cost will drive new innovation in the application of highly parallel programming models. General Purpose GPU programming. But with the third generation interfaces, the true power of General Purpose GPU programming was unlocked. From CPU to GPU.
Storage is a critical aspect to consider when working with cloud workloads. High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it. What is an example of a workload?
Shell leverages AWS for big data analytics to help achieve these goals. Unilever – Unilever R&D program intended to accelerate the company’s scientific progress through improved access to global information. Shell''s scientists, especially the geophysicists and drilling engineers, frequently use cloud computing to run models.
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. It uses a hash table to manage these pairs, divided into fixed-size buckets with linked lists for key-value storage. Redis Database Management with ScaleGrid ScaleGrid.io
Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
Flexibility is one of the key principles of Amazon Web Services - developers can select any programming language and software package, any operating system, any middleware and any database to build systems and applications that meet their requirements. Driving Storage Costs Down for AWS Customers. Comments (). At werner.ly Syndication.
ScaleGrid’s comprehensive solutions provide automated efficiency and cost reduction while offering tailored features such as predictive analytics for businesses of all sizes. All the tedious tasks such as storage, backups, and configuration are managed by an attentive crew so that you can concentrate on making your vacation special.
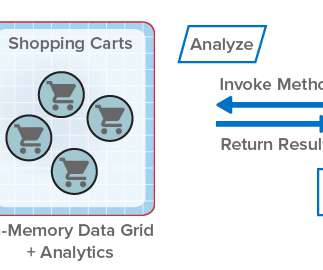
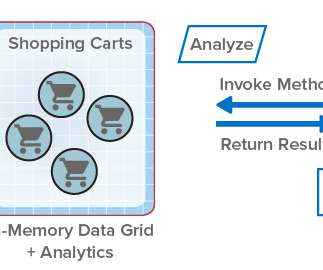
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . Because IMDGs have highly scalable storage capacity, they can easily return large numbers of matching objects to the client application, and this leads to network bottlenecks transferring large amounts of data from the IMDG back to the client.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . Because IMDGs have highly scalable storage capacity, they can easily return large numbers of matching objects to the client application, and this leads to network bottlenecks transferring large amounts of data from the IMDG back to the client.
Real-Time Device Tracking with In-Memory Computing Can Fill an Important Gap in Today’s Streaming Analytics Platforms. The Limitations of Today’s Streaming Analytics. How are we managing the torrent of telemetry that flows into analytics systems from these devices? The list goes on.
There are several problems efficient test scheduling could help us solve: Quickly detect a regression in the integration of the Netflix SDK on a consumer electronic or MVPD (multichannel video programming distributor) device. The data can be truncated after each execution and offloaded to a long-term storage for further analysis.
Further, open source databases can be modified in infinite ways, enabling institutions to meet their specific needs for data storage, retrieval, and processing. Non-relational databases: Instead of tables, non-relational (NoSQL) databases use document-based data storage, column-oriented storage, and graph databases.
This model organizes key information about each data source (for example, an IoT device, e-commerce shopper, or medical patient) in a software component that tracks the data source’s evolving state and encapsulates algorithms, such as predictive analytics, for interpreting that state and generating real-time feedback.
The TNW team is doing a great job in getting an excellent program together that draws an audience from around the world, not just Europe, and there is an interesting mix of startups, enterprises, investors and media attending. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway.
Traditional platforms for streaming analytics don’t offer the combination of granular data tracking and real-time aggregate analysis that logistics applications in operational environments such as these require. With the real-time digital twin model, the next generation of streaming analytics has arrived.
Traditional platforms for streaming analytics don’t offer the combination of granular data tracking and real-time aggregate analysis that logistics applications in operational environments such as these require. With the real-time digital twin model, the next generation of streaming analytics has arrived.
Traditional platforms for streaming analytics don’t offer the combination of granular data tracking and real-time aggregate analysis that logistics applications such as these require. With the real-time digital twin model, the next generation of streaming analytics has arrived.
The TPC designed benchmarks for transaction processing (OLTP) and analytics (OLAP) and anyone can run these benchmarks, have them audited by the TPC and published on the official benchmark rankings. What programming languages does HammerDB use and why does it matter? Adoption by the TPC. Derived Workloads.
Using real-time streaming data and analytics, manufacturers can optimize workflows in the moment, reducing bottlenecks and minimizing downtime. Using predictive analytics, manufacturers can anticipate potential quality issues before they occur, allowing for proactive adjustments.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content