This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs). By automating OneAgent deployment at the image creation stage, organizations can immediately equip every EC2 instance with real-time monitoring and AI-powered analytics. group of companies.
Dynatrace automatically puts logs into context Dynatrace Log Management and Analytics directly addresses these challenges. Open a host, cluster, cloud service, or database view in one of these apps, and you immediately see logs alongside other relevant metrics, processes, SLOs, events, vulnerabilities, and data offered by the app.
Understanding Teradata Data Distribution and Performance Optimization Teradata performance optimization and database tuning are crucial for modern enterprise data warehouses.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Logs can include data about user inputs, system processes, and hardware states. What is log analytics? Log monitoring vs log analytics.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
The goal is to turn more data into insights so the whole organization can make data-driven decisions and automate processes. Grail data lakehouse delivers massively parallel processing for answers at scale Modern cloud-native computing is constantly upping the ante on data volume, variety, and velocity.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. This allows developers to easily access and process the file without handling the upload mechanics directly. Complete mitigation is only guaranteed in Struts version 7.0.0
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
PurePath unlocks precise and actionable analytics across the software lifecycle in heterogenous cloud-native environments. Dynatrace provides information on every request, through every single microservice or serverless function, seamlessly integrating OpenTelemetry, with powerful analytics, including: Out-of-the-box service hotspot analysis.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the cloud network infrastructure to address the identified problems. After several iterations of the architecture and some tuning, the solution has proven to be able to scale. What is BPF?
At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. Adding AIOps to automation processes makes the volume of data that applications and multicloud environments generate much less overwhelming.
The Dynatrace platform automatically integrates OpenTelemetry data, thereby providing the highest possible scalability, enterprise manageability, seamless processing of data, and, most importantly the best analytics through Davis (our AI-driven analytics engine), and automation support available. What Dynatrace will contribute.
We estimate that Dynatrace can automate the majority of repetitive tasks and additional compliance burdens introduced by DORA technical requirements using analytics and automation based on observability and security data. Financial institutions face an increased compliance burden with DORA.
Open-source metric sources automatically map to our Smartscape model for AI analytics. Stay tuned for an upcoming blog series where we’ll give you a more hands-on walkthrough of how to ingest any kind of data from StatsD, Telegraf, Prometheus, scripting languages, or our integrated REST API. Stay tuned. Seeing is believing.
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. Business leaders can decide which logs they want to use and tune storage to their data needs.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace.
The Dynatrace platform automatically integrates OpenTelemetry data, thereby providing the highest possible scalability, enterprise manageability, seamless processing of data, and, most importantly the best analytics through Davis (our AI-driven analytics engine), and automation support available. Seeing is believing.
We hear from our customers how important it is to have a centralized, quick, and powerful access point to analyze these logs; hence we’re making it easier to ingest AWS S3 logs and leverage Dynatrace Log Management and Analytics powered by Grail.
Johnson also shared how his team is using AI to automate certain talent management processes, such as expediting applicant-job matching and aligning training and certification offerings with workforce skill gaps. Additionally, as the program gathers more data, it will enable predictive analytics to forecast future talent and skill deficits.
Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes. Some solutions that use logs for troubleshooting only provide manual analytics to search for the root causes of issues. What’s next.
Tracking changes to automated processes, including auditing impacts to the system, and reverting to the previous environment states seamlessly. The ultimate goal of each of these reviews is to identify gaps, quantify risk, and develop recommendations for improving the team, processes, and architecture with each of the five pillars.
Historically, I’d maybe look at Google Analytics—or a RUM solution if the client had one already—but this is only useful for showing me particular outliers, and not necessarily any patterns across the whole project. For now, I’m usually sat with a coffee, some tunes on, and an old-school pen and paper making notes. See entry 6.
Dynatrace is fully committed to the OpenTelemetry community and to the seamless integration of OpenTelemetry data , including ingestion of custom metrics , into the Dynatrace open analytics platform. Use topological details related to the service at hand to drill down to the process or host running the service for root cause analysis.
Recently, the Parliament of India released the Digital Personal Data Protection Act 2023 , which regulates the processing of digital personal data in India and recognizes the right of individuals to protect their data in India. Obligations to end users while moving to SaaS.
This gives us unified analytics views of node resources together with pod-level metrics such as container CPU throttling by node, which makes problem correlation much easier to analyze. From here we jump directly into Dynatrace Distributed traces view, shown below, to understand code-level contributions to total processing time.
IAI can enhance the processes that nurture employee experiences and a healthy and motivated workforce. From performance reviews to goal setting, AI’s analytical prowess significantly streamlines growth and development processes. Artificial intelligence is now set to power individualized employee growth and development.
T o get performance insights into applications and efficiently troubleshoot and optimize them, you need precise and actionable analytics across the entire software life cycle. If you’re interested in learning more about OpenTelemetry or joining the community, a good place to start is the OpenTelemetry GitHub repository. What’s next.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. To address this, we use a static limit for the initial queries to the backing store, query with this limit, and process the results.
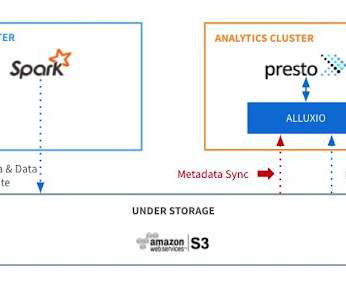
Meanwhile, understanding the internal process is important in order to tune the performance. Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storage systems, thus making it simple for users to reason the data retrieved from Alluxio.
Web application security is the process of protecting web applications against various types of threats that are designed to exploit vulnerabilities in an application’s code. Positive filters are highly effective at blocking attacks but require constant tuning. Whether the process is exposed to the Internet.
Containerd monitoring support now includes: Automatic monitoring of processes in containerd containers. Rule-based control of automated process monitoring in containerd containers. The real-time dependency model of your whole environment drives the core of Davis—the Dynatrace full-stack root-cause analytics engine.
Modern infrastructure needs to be elastic and GitOps approaches are used to automate the provisioning of infrastructure and applications using Git, an open-source control system that provides the change processes including reviews and approvals. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The processed data is typically stored as data warehouse tables in AWS S3. Personalized articles in Netflix Help Center powered by Bulldozer.
We have now moved to a more systematic approach where unknown errors are fed into a Machine Learning process that performs clustering to propose new regular expressions for commonly occurring errors. In the future, we are looking to automate this process. Expand Pensive with Machine Learning classifiers.
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. CDC and data source Change data capture or CDC , is a semantic for processing changes in a source for the purpose of replicating those changes to a sink.
When a web application or mobile app process doesn’t respond quickly, users may repeatedly click the affected UI control in helpless frustration. Usability analytics with rage clicks will be publicly available towards the end of June, 2019. These analytics capabilities can be used with or without enabling Session Replay.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. We’re further extending the support of extensions for additional protocols and technologies, and improving the process of creating extensions, so be sure to stay tuned.
Clark Wright, Staff Analytics Engineer at Airbnb, talked about the concept of Data Quality Score at Airbnb. Creating new development environments is cumbersome: Populating them with data is compute-intensive, and the deployment process is error-prone, leading to higher costs, slower iteration, and unreliable data. Until next time!
As more organizations respond to the pressure to release better software faster, there is an increasing need to build quality gates into every stage of BizDevOps processes , from early development to deployment. Automating quality gates creates reliable checks and balances and speeds up the process by avoiding manual intervention.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content