This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We introduced Digital Business Analytics in part one as a way for our customers to tie business metrics to application performance and user experience, delivering unified insights into how these metrics influence business milestones and KPIs. A sample Digital Business Analytics dashboard. Dynatrace news.
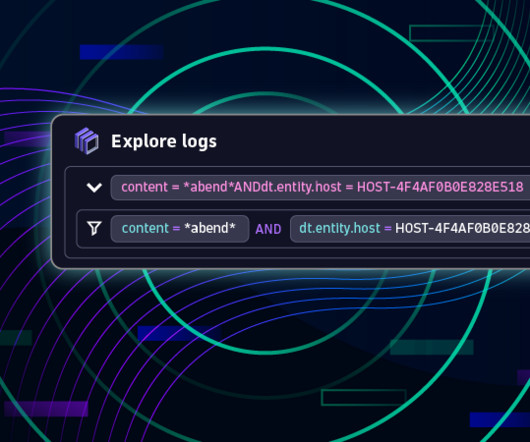
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operatingsystem, computing environment, application, server, or network device.
As user experiences become increasingly important to bottom-line growth, organizations are turning to behavior analytics tools to understand the user experience across their digital properties. Here’s what these analytics are, how they work, and the benefits your organization can realize from using them.
Unlike rsyslog, which requires minimal configuration for centralization, Journald’s approach, using systems-based operatingsystems, necessitates more advanced configurations and additional components. It provides unified observability by automatically correlating logs and placing them in the context of traces and metrics.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
With 99% of organizations using multicloud environments , effectively monitoring cloud operations with AI-driven analytics and automation is critical. IT operationsanalytics (ITOA) with artificial intelligence (AI) capabilities supports faster cloud deployment of digital products and services and trusted business insights.
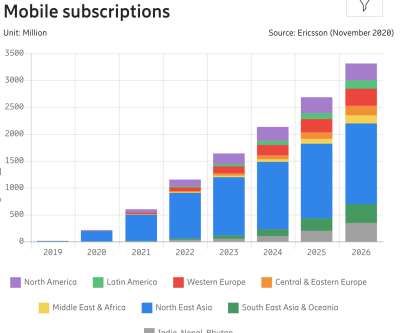
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
When operating an application, it’s helpful to have deeper insights that show you what’s really going on. To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. OneAgent and its Operator .
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operatingsystems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Metrics, logs , and traces make up three vital prongs of modern observability. Event logging and software tracing help application developers and operations teams understand what’s happening throughout their application flow and system. Comparing log monitoring, log analytics, and log management.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x).
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. DEM can give organizations business observability—insight into the effects of user experience on the bottom line. What is digital experience monitoring?
IBM i, formerly known as iSeries, is an operatingsystem developed by IBM for its line of IBM i Power Systems servers. It is based on the IBM AS/400 system and is known for its reliability, scalability, and security features. Nothing is installed on your IBM i systems. What is IBM i? It’s all monitored remotely !
With the availability of Linux on IBM Z and LinuxONE, the IBM Z platform brings a familiar host operatingsystem and sustainability that could yield up to 75% energy reduction compared to x86 servers. Deploying your critical applications on additional host operatingsystems increases the dependencies for observability.
When operating an application, it ’ s helpful to have deeper insights that show you what’s really going on. Metrics to find out how the behavior of a system has changed over time . Traces help find the flow of a request through a distributed system . OneAgent and its Operator . Digital Business Analytics.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operatingsystem and infrastructure. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. Observability.
This growth was spurred by mobile ecosystems with Android and iOS operatingsystems, where ARM has a unique advantage in energy efficiency while offering high performance. Even if some part of your codebase can be instrumented to collect observability data, having all three signal types (metrics, traces, and logs) is crucial.
The variables that can impact the performance of an application vary; from coding errors or ‘bugs’ in the software, database slowdowns, hosting and network performance, to operatingsystem and device type support. User Experience and Business Analytics ery user journey and maximize business KPIs. Advanced Cloud Observability.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
This makes developing, operating, and securing modern applications and the environments they run on practically impossible without AI. CloudOps: Applying AIOps to multicloud operations. The deviating metric is response time. Let’s say, for example, an application is experiencing a slowdown in receiving its search requests.
Include metrics, event logs, distributed traces, metadata, user experience data, and telemetry data from open source technologies and cloud platforms. A key requirement for teams operatingsystems under peak load is detecting root-cause issues in real time. Automate IT operations.
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
This is particularly true in hybrid cloud architectures, where system complexity, security, and performance are difficult to manage across cloud providers and the IBM Z mainframe platform. A prerequisite for a successful hybrid cloud is maintaining observability, including all telemetry signals: logs, metrics, and traces.
The variables that can impact the performance of an application vary; from coding errors or ‘bugs’ in the software, database slowdowns, hosting and network performance, to operatingsystem and device type support. User Experience and Business Analytics ery user journey and maximize business KPIs. Advanced Cloud Observability.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Dynatrace news. Performance monitoring.
WiredTiger is a good all-purpose engine while In-Memory is better for specific use cases such as real-time analytics. Compaction operation defragments data files & indexes. However, keep in ming that it does not release space to the operatingsystem. The compact process releases the free space to the operatingsystem.
After all, when we look at our analytics, we will hardly find any customers browsing our sites or apps with a mid-range device on a flaky 3G connection. However, there are quite a few high-profile case studies exploring the impact of mobile optimization on key business metrics. Driving Business Metrics.
But do you know how Lighthouse calculates performance metrics like First Contentful Paint (FCP), Total Blocking Time (TBT), and Cumulative Layout Shift (CLS)? Still, there’s nothing in there to tell us about the data Lighthouse is using to evaluate metrics. But it comes with caveats. So why use lab data at all?
Docker, as well as other containerization solutions, makes it possible to package and run applications in a variety of environments, without having to consider factors like operatingsystem or other specific system configurations. Monitoring & Analytics. Nomad is another container orchestration platform.
The key metric for measuring the sustainability of a digital product is its energy usage. An obvious metric here is CPU usage, but memory usage and other forms of data storage also play their part. Note : There are plenty of other tools that provide us with a metric for data transfer including the much revered WebPagetest.
Weirdly, they report as a range of browsers in our analytics including the Android WebView, Chrome and Safari (despite it’s not supporting this!). Using signals like Save Data allows you to help those users that need help the most, compared to traditional analytics of looking at all users or even segmenting by device type. “.
HammerDB has graphical and command line interfaces for the Windows and Linux operatingsystems. The TPC designed benchmarks for transaction processing (OLTP) and analytics (OLAP) and anyone can run these benchmarks, have them audited by the TPC and published on the official benchmark rankings. The NOPM Metric.
Concurrency refers to the system’s ability to carry out multiple tasks in parallel and manage the access and usage of shared resources. A distributed system comprises of a variety of hardware and software components with different operatingsystems and technologies, meaning the processors are separate and independent of each other.
Docker, as well as other containerization solutions, makes it possible to package and run applications in a variety of environments, without having to consider factors like operatingsystem or other specific system configurations. Monitoring & Analytics. Nomad is another container orchestration platform.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
Support a wide variety of devices and application types –The platform should be optimized to support multiple devices, implementations, and OperatingSystems. This allows users to validate and simulate diverse types of traffic for defense systems and services while concurrently simulating normal system loads.
Cloud-based tools also provide detailed metrics with graphs to understand and analyze the performance. reporting mechanisms (reporting and analytics tools), physical system connections etc. For applications running natively on the platform, you can choose multiple devices running on various operatingsystems.
It is of note that we have not discussed the operatingsystem yet, that is because the source code and the code included with the pre-packaged versions is identical whether it is running on Linux or Windows on x86-64 architecture (or any other platform). BLT graphical package extension for metrics for both Linux and Windows.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Setting Realistic Goals. Defining The Environment.
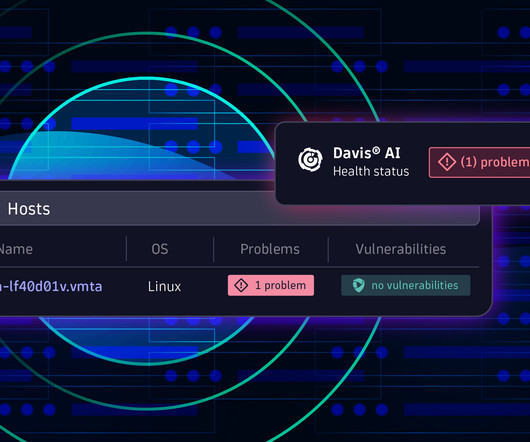
Dynatrace introduced numerous powerful features to its Infrastructure & Operations app, addressing the emerging requirement for enhanced end-to-end infrastructure observability. These enhancements are designed to empower IT operations and SRE teams with more comprehensive visibility and increased efficiency at any time.
What operatingsystems do you use? We also generate quite a bit of internal application metrics using a home grown framework. We use Grafana/Nagios/Kibana, internal tools and other tools to monitor performance for other parts of the system. Do you implement web analytics? Load Balancers / Reverse Proxy. Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content