This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
This is explained in detail in our blog post, Unlock log analytics: Seamless insights without writing queries. There is no need to think about schema and indexes, re-hydration, or hot/cold storage. Using patent-pending high ingest stream-processing technologies, OpenPipeline currently optimizes data for Dynatrace analytics and AI at 0.5
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This decoupling simplifies system architecture and supports scalability in distributed environments.
Information related to user experience, transaction parameters, and business process parameters has been an unretrieved treasure, now accessible through new and unique AI-powered contextual analytics in Dynatrace. Executives drive business growth through strategic decisions, relying on data analytics for crucial insights.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. It also serves as central configuration of access patterns such as consistency or latency targets.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. Factors like read and write speed, latency, and data distribution methods are essential. In a detailed article, we've discussed how to align a NoSQL database with specific business needs.
Realizing that executives from other organizations are in a similar situation to my own, I want to outline three key objectives that Dynatrace’s powerful analytics can help you deliver, featuring nine use cases that you might not have thought possible. Change is my only constant. This is inefficient and creates avoidable risks.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. Unlike data warehouses, however, data is not transformed before landing in storage. A data lakehouse provides a cost-effective storage layer for both structured and unstructured data. Query language.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
This includes how quickly the application loads, how much load it is putting on the device, how much storage is being used, and how frequently it crashes. By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The data warehouse is not designed to serve point requests from microservices with low latency.
Without distributed tracing, pinpointing the cause of increased latency could take hours or even days. There is no need to think about schema and indexes, re-hydration, or hot/cold storage. Interact with data intuitively and easily and benefit from immediate, AI-supported insights. The same is true when it comes to log ingestion.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage.
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. This approach often leads to heavyweight high-latencyanalytical processes and poor applicability to realtime use cases.
Power business analytics with Dynatrace Banks that can deploy vertically integrated risk management solutions will deliver unprecedented agility, precision, and control for risk management functions. Maximize performance for high-frequency and low-latency trading strategies. Automated issue resolution. Break down data silos.
This proximity reduces latency and enables real-time decision-making. The Need for Real-Time Analytics and Automation With increasing complexity in manufacturing operations, real-time decision-making is essential. Assess factors like network latency, cloud dependency, and data sensitivity.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon Kinesis Data Analytics. Amazon Simple Storage Service (S3). The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Dynatrace news.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). One use case for STM is to model the behavior of a customer in the form of a flow of transactions along the buyer’s journey.
This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
million” – Gartner Data observability is a practice that helps organizations understand the full lifecycle of data, from ingestion to storage and usage, to ensure data health and reliability. Data observability is crucial to analytics and automation, as business decisions and actions depend on data quality.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. The primary goal of ITOps is to provide a high-performing, consistent IT environment.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon Kinesis Data Analytics. Amazon Simple Storage Service (S3). The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Dynatrace news.
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Amazon DynamoDB offers low, predictable latencies at any scale. In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. s read latency, particularly as dataset sizes grow. The growth of Amazonâ??s
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Because these IoT devices are powered by microprocessors or microcontrollers that have limited processing power and memory, they often rely heavily on AWS and the cloud for processing, analytics, storage, and machine learning. Sometimes an internet connection is weak or not available at all, as is often the case in remote locations.
This new Region has been highly requested by companies worldwide, and it provides low-latency access to AWS services for those who target customers in South America. The new Sao Paulo Region provides better latency to South America, which enables AWS customers to deliver higher performance services to their South American end-users.
Number of slow queries recorded Select types, sorts, locks, and total questions against a database Command counters and handlers used by queries give an overall traffic summary Along with this, PMM also comes with Query Analytics giving much detailed information about queries getting executed.
The partnership between AI and cloud computing brings about transformative trends like enhanced security through intelligent threat detection, real-time analytics, personalization, and the implementation of edge computing for quicker on-site decision-making. Key among these trends is the emphasis on security and intelligent analytics.
Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
Japanese companies and consumers have become used to low latency and high-speed networking available between their businesses, residences, and mobile devices. The advanced Asia Pacific network infrastructure also makes the AWS Tokyo Region a viable low-latency option for customers from South Korea. At werner.ly Syndication.
For example, the most fundamental abstraction trade-off has always been latency versus throughput. Modern CPUs strongly favor lower latency of operations with clock cycles in the nanoseconds and we have built general purpose software architectures that can exploit these low latencies very well. Where to go from here?
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. It uses a hash table to manage these pairs, divided into fixed-size buckets with linked lists for key-value storage. Redis Database Management with ScaleGrid ScaleGrid.io
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. This allows for faster failover times while minimizing latency. Building upon Redis. Redis and Fast Data.
Some applications – medical equipment, industrial machinery, and building automation are just a few – can't rely exclusively on the cloud for control, and require some form of local storage and execution. Some applications may also rely on timely decisions: when maneuvering heavy machinery, an absolute minimum of latency is critical.
Storage is a critical aspect to consider when working with cloud workloads. High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it.
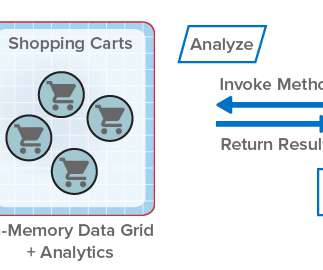
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content