This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Dynatrace unified analytics capabilities for observability are top-of-the-class ( Gartner Magic Quadrant 2024 ), enabling you to query and analyze all your observability data across your enterprise. Have a look at them on our Dynatrace Playground. Infrastructure health: A honeycomb chart is often used to visualize infrastructure health.
This is where observability analytics can help. What is observability analytics? Observability analytics enables users to gain new insights into traditional telemetry data such as logs, metrics, and traces by allowing users to dynamically query any data captured and to deliver actionable insights. Put simply, context is king.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Its architecture supports stream transformations, joins, and filtering, making it a powerful tool for real-time analytics. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). About YCSB.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. It also serves as central configuration of access patterns such as consistency or latency targets.
High latency or lack of responses. API manager monitoring from the application server perspective, which is what Dynatrace delivers with the WSO2 API Manager monitoring extension, can save you hours of bug hunting time. This increase is clearly correlated with the increased response latencies. Read on to see how it works.
Dynatrace provides a centralized approach for establishing, instrumenting, and implementing SLOs that uses full-stack observability , topology mapping, and AI-driven analytics. In this example, “Reverse proxy” and “Front-end server” are clearly in the critical path. Latency is the time that it takes a request to be served.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. Improve business decisions with precision analytics.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. The difference is the owner of the Lambda function does not have to worry about provisioning and managing servers. Return larger payload sizes.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy.
When the server receives a request for an action (post, like etc.) When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds.
Determining the root cause of these issues can be difficult when the underlying “hardware” is a virtualization software stack rather than a bare-metal server. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.
The roles and responsibilities of ITOps team members include the following: A system administrator configures servers, installs applications, monitors the health of the system, and fixes and upgrades hardware. This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. Performance.
However, serverless applications have unique characteristics that make observability more difficult than in traditional server-based applications. Serverless applications have several benefits over server-based applications: Eliminate the need to provision, manage and maintain servers or containers.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). PC, smartphone, server) or virtual (virtual machines, cloud gateways). Endpoints can be physical (i.e.,
Edge computing involves processing data locally, near the source of data generation, rather than relying on centralized cloud servers. This proximity reduces latency and enables real-time decision-making. Assess factors like network latency, cloud dependency, and data sensitivity.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. million AI server units annually by 2027, consuming 75.4+ Estimates show that NVIDIA, a semiconductor manufacturer, could release 1.5
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
The next level of observability: OneAgent In the first two parts of our series, we used OpenTelemetry to manually instrument our application and send the telemetry data straight to the Dynatrace analytics back end. Let’s click “Apache Web Server apache” now. Yet, we have two entries for these two services in our list.
When a server experiences an outage, the system promptly triggers an alert and initiates actions like restarting a server or redirecting traffic to a redundant server. Using advanced causal AI and context-aware decision-making, it identifies the root cause behind server failures.
The Azure MySQL dashboard serves as a comprehensive overview of your MySQL servers and database services. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics. Get full observability into your Azure MySQL database. Get a comprehensive view of your batch jobs.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Amazon DynamoDB offers low, predictable latencies at any scale. s read latency, particularly as dataset sizes grow. Consistency. SimpleDBâ??s
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Monitoring and observability represent a continuum from basic telemetry of single servers to deep insights about complete applications and dependencies.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems.
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. However, simply deploying a monitoring tool is not enough; you need to know which Key Performance Indicators (KPIs) to monitor to gain insights into your MySQL server’s health and performance.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
The partnership between AI and cloud computing brings about transformative trends like enhanced security through intelligent threat detection, real-time analytics, personalization, and the implementation of edge computing for quicker on-site decision-making. Key among these trends is the emphasis on security and intelligent analytics.
The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. JUMO uses a broad range of behavioral and payments' data, near real-time analytics and predictive modeling, to create financial identities for people who were previously beyond the reach of banks.
WiredTiger is a good all-purpose engine while In-Memory is better for specific use cases such as real-time analytics. However, it is limited by the available free memory amount, and all data is lost when the server stops. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. These storage nodes collaborate to manage and disseminate the data across numerous servers spanning multiple data centers.
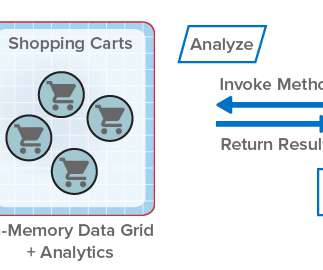
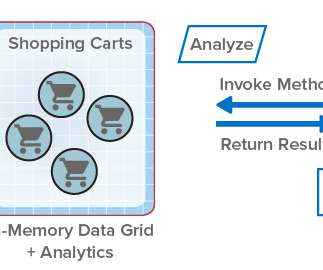
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
The naming system that we are all most familiar with in the internet is the Domain Name System (DNS) that manages the naming of the many different entities in our global network; its most common use is to map a name to an IP address, but it also provides facilities for aliases, finding mail servers, managing security keys, and much more.
Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
This new Region has been highly requested by companies worldwide, and it provides low-latency access to AWS services for those who target customers in South America. The new Sao Paulo Region provides better latency to South America, which enables AWS customers to deliver higher performance services to their South American end-users.
Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load. Redis Revealed: An Overview Redis, a renowned open-source, in-memory remote dictionary server, stands out for its diverse data structures and advanced features. Data transfer technology.
Japanese companies and consumers have become used to low latency and high-speed networking available between their businesses, residences, and mobile devices. The advanced Asia Pacific network infrastructure also makes the AWS Tokyo Region a viable low-latency option for customers from South Korea. Spot Instances - Increased Control.
For example, the most fundamental abstraction trade-off has always been latency versus throughput. Modern CPUs strongly favor lower latency of operations with clock cycles in the nanoseconds and we have built general purpose software architectures that can exploit these low latencies very well. Where to go from here?
Over those years, we have seen the technology stack evolve from server-rendered pages with some minor JavaScript and CSS to full-blown JavaScript applications. Although mixing the concepts of a server web framework like ASP.NET with a client-side web framework like React made things more complicated, we were quite happy with the solution.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content