This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka achieves scalability by distributing topics across multiple partitions and replicating them among brokers.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency.
Delay is Not an Option: Low Latency Routing in Space , Murat ). Waqas Dhillon : The goal of in-database machine learning is to bring popular machine learning algorithms and advanced analytical functions directly to the data, where it most commonly resides – either in a data warehouse or a data lake. Please support me on Patreon.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. Author & founder of BangDB.
Realizing that executives from other organizations are in a similar situation to my own, I want to outline three key objectives that Dynatrace’s powerful analytics can help you deliver, featuring nine use cases that you might not have thought possible. Change is my only constant. This is inefficient and creates avoidable risks.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. FUN FACT : In this talk , Dikang Gu, a software engineer at Instagram core infra team has mentioned about how they use Cassandra to serve critical usecases, high scalability requirements, and some pain points.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications. What is a Lambda serverless function?
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
This proximity reduces latency and enables real-time decision-making. The Need for Real-Time Analytics and Automation With increasing complexity in manufacturing operations, real-time decision-making is essential. Assess factors like network latency, cloud dependency, and data sensitivity.
As such, the observability platform used to monitor Hyper-V should ideally fulfill requirements for holistic visibility, correlation and causation analysis, AI-powered analytics, scalability, and security. Dynatrace is a platform that satisfies all these criteria. Learn more about the pillars of modern observability in this e-book.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively.
Business analytics : Organizations can combine business context with full stack application analytics and performance to understand real-time business impact, improve conversion optimization, ensure that software releases meet expected business goals, and confirm that the organization is adhering to internal and external SLAs.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. This allows for faster failover times while minimizing latency. Building upon Redis. Redis and Fast Data.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The data warehouse is not designed to serve point requests from microservices with low latency. Moving data with Bulldozer at Netflix.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. The next challenge was to stream large amounts of traces via a scalable data processing platform.
You can use these services in combinations that are tailored to help your business move faster, lower IT costs, and support scalability. Amazon Kinesis Data Analytics. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Amazon Elastic File System (EFS). Amazon EMR. Amazon Redshift.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Predictive analytics, powered by AI, enhance business processes and optimize resource allocation according to workload demands.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. DevOps practitioners struggle to maintain highly available and scalable applications. Experienced database administrators learn to spot patterns that can lead to common problems.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
You can use these services in combinations that are tailored to help your business move faster, lower IT costs, and support scalability. Amazon Kinesis Data Analytics. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Amazon Elastic File System (EFS). Amazon EMR. Amazon Redshift.
Scalability : Message queues can handle multiple requests and messages simultaneously, making it easier to scale an application to meet increasing demands. This scalability is essential for applications that experience fluctuating workloads. This reliability is crucial for maintaining data integrity and consistency across the system.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
The next level of observability: OneAgent In the first two parts of our series, we used OpenTelemetry to manually instrument our application and send the telemetry data straight to the Dynatrace analytics back end. This allows us to quickly tell whether the network link may be saturated or the processor is running at its limit.
A more scalable option is to decouple these systems and build a pipe that connects these engines and feeds all change records from the source database to the data warehouse (e.g., Also, you can choose to program post-commit actions, such as running aggregate analytical functions or updating other dependent tables.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. They can also see how the change can affect critical objectives like SLOs and golden signals, such as traffic, latency, saturation, and error rate. DevOps teams need automation that goes beyond passive observations.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
Werner Vogels weblog on building scalable and robust distributed systems. This new Region has been highly requested by companies worldwide, and it provides low-latency access to AWS services for those who target customers in South America. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications.
MongoDB is a dynamic database system continually evolving to deliver optimized performance, robust security, and limitless scalability. Sharded time-series collections for improved scalability and performance. Introduction of clustered collections for optimized analytical queries. Ready to supercharge your MongoDB experience?
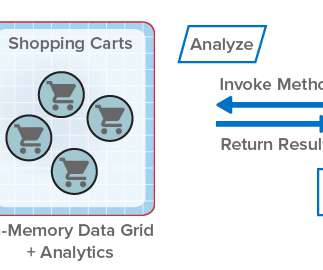
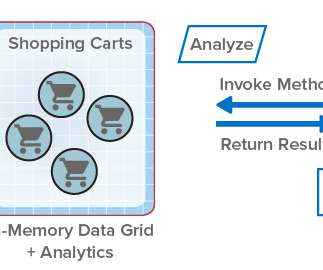
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
WiredTiger is a good all-purpose engine while In-Memory is better for specific use cases such as real-time analytics. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. Choosing the appropriate storage engine can have a significant impact on application performance.
Werner Vogels weblog on building scalable and robust distributed systems. Japanese companies and consumers have become used to low latency and high-speed networking available between their businesses, residences, and mobile devices. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. For example, the most fundamental abstraction trade-off has always been latency versus throughput. The throughput of this pipeline is more important than the latency of the individual operations. Driving down the cost of Big-Data analytics.
This approach allows companies to combine the security and control of private clouds with public clouds’ scalability and innovation potential. Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. can enhance Redis by handling management tasks, backups, and scalability, facilitating global reach and easy cloud integration for global businesses.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content