This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional network-based security approaches are evolving. Enhanced security measures, such as encryption and zero-trust, are making it increasingly difficult to analyze security threats using network packets. While network security remains relevant, the emphasis is now on application observability and threat detection.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries. This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Its architecture supports stream transformations, joins, and filtering, making it a powerful tool for real-time analytics. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
High latency or lack of responses. You receive an alert message from Dynatrace (your infrastructure observability hub) letting you know that the average response latency of all deployed APIs has tripled. Is it the WSO2-AM gateway itself, a networking issue, a sudden increase in demand, or something else entirely?
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. Load time and networklatency metrics. Minimize network requests.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. We can use cloud technologies such as Amazon Kinesis or Azure Stream Analytics for collecting, processing, and analyzing real-time, streaming data to get timely insights and react quickly to new information(e.g.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. It also serves as central configuration of access patterns such as consistency or latency targets.
Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. This leads to a more efficient and streamlined experience for users. Challenges with running Hyper-V Working with Hyper-V can come with several challenges.
Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. Improve business decisions with precision analytics.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Customers can use response streaming to achieve the following: Improve Time to First Byte (TTFB) performance for latency-sensitive applications. Return larger payload sizes. How does Dynatrace help?
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. A network administrator sets up a network, manages virtual private networks (VPNs), creates and authorizes user profiles, allows secure access, and identifies and solves network issues.
This proximity reduces latency and enables real-time decision-making. However, these technologies are on a path of rapid convergence as factories scale up their IIoT networks and demand faster, more autonomous decision-making. This capability reduces rework and scrap, leading to cost savings and better resource utilization.
With DEM solutions, organizations can operate over on-premise network infrastructure or private or public cloud SaaS or IaaS offerings. STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables).
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. This approach often leads to heavyweight high-latencyanalytical processes and poor applicability to realtime use cases.
In summary, the Dynatrace platform enables banks to do the following: Capture any data type: logs, metrics, traces, topology, behavior, code, metadata, network, security, web, and real-user monitoring data, and business events. Maximize performance for high-frequency and low-latency trading strategies. Automated issue resolution.
This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem. The Dynatrace platform approach to managing your cloud initiatives provides insights and answers to not just see what could go wrong but what could go right.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
When choosing an API monitoring tool, keep in mind that not all have the same breadth of functionality or depth of analytic capabilities. In that case, you can plan accordingly and limit the use of API services in that region or adjust your alerting thresholds to account for the longer latency in regions with poorer performance.
Azure Virtual Network Gateways. Our customers have frequently requested support for this first new batch of services, which cover databases, big data, networks, and computing. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics. Azure DB for PostgreSQL.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
The next level of observability: OneAgent In the first two parts of our series, we used OpenTelemetry to manually instrument our application and send the telemetry data straight to the Dynatrace analytics back end. This allows us to quickly tell whether the network link may be saturated or the processor is running at its limit.
TiDB is an open-source, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads. There shouldn't be any jitters (either in the cluster or on disk), and no hotspots, slow queries, or network fluctuations. Ideally, a TiDB cluster should always be efficient and problem-free.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon Kinesis Data Analytics. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Dynatrace news. Amazon Elastic File System (EFS).
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
Things always always feel fast when we’re developing because, more often than not, we’re working on high-spec machines on dedicated networks, and also serving from localhost which removes the bulk of the latency and bandwidth issues that a real user would suffer. How: RUM tooling, analytics, monitoring.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon Kinesis Data Analytics. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Dynatrace news. Amazon Elastic File System (EFS).
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. That's where we built many pioneering networking technologies, our next-generation software for customer support, and the technology behind our compute service, Amazon EC2.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems.
To move as fast as they can at scale while protecting mission-critical data, more and more organizations are investing in private 5G networks, also known as private cellular networks or just “private 5G” (not to be confused with virtual private networks, which are something totally different). What is a private 5G network?
Japanese companies and consumers have become used to low latency and high-speed networking available between their businesses, residences, and mobile devices. With the launch of the Asia Pacific (Tokyo) Region, companies can now leverage the AWS suite of infrastructure web services directly connected to Japanese networks.
The partnership between AI and cloud computing brings about transformative trends like enhanced security through intelligent threat detection, real-time analytics, personalization, and the implementation of edge computing for quicker on-site decision-making. Key among these trends is the emphasis on security and intelligent analytics.
Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions. By breaking up large datasets into more manageable pieces, each segment can be assigned to various network nodes for storage and management purposes.
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. This allows for faster failover times while minimizing latency. Building upon Redis. Redis and Fast Data.
For example, the most fundamental abstraction trade-off has always been latency versus throughput. Modern CPUs strongly favor lower latency of operations with clock cycles in the nanoseconds and we have built general purpose software architectures that can exploit these low latencies very well. Where to go from here?
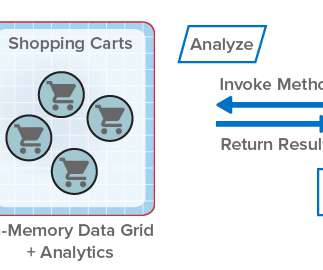
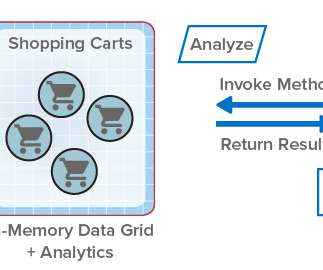
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
A performance budget as a mechanism for planning a web experience and preventing performance decay might consist of the following yardsticks: Overall page weight, Total number of HTTP requests, Page-load time on a particular mobile network, First Input Delay (FID). Similarly, unoptimized images were the leading cause of page bloat.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content