This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. No delays and overhead of reindexing and rehydration.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. What is RabbitMQ?
This is where observability analytics can help. What is observability analytics? Observability analytics enables users to gain new insights into traditional telemetry data such as logs, metrics, and traces by allowing users to dynamically query any data captured and to deliver actionable insights. Put simply, context is king.
One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries. This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. This integration will not only optimize performance but also ensure more efficient resource utilization. This leads to a lot of false positives that require manual judgement.
This leads to a more efficient and streamlined experience for users. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams. Dynatrace is a platform that satisfies all these criteria.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. This model supports both simple and complex data models, balancing flexibility and efficiency.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Data lakehouses deliver the query response with minimal latency. Reduced redundancy.
Traces are used for performance analysis, latency optimization, and root cause analysis. The OpenTelemetry Protocol (OTLP) plays a critical role in this framework by standardizing how systems format and transport telemetry data, ensuring that data is interoperable and transmitted efficiently. Employ efficient sampling.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
This blog explores how vertically integrated risk management solutions that use AI and automation enable unparalleled visibility, control, and efficiency for risk management in banking. They can accomplish this all while delivering transformation efficiency and economies of scale for IT functions that maintain risk management infrastructure.
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. This approach often leads to heavyweight high-latencyanalytical processes and poor applicability to realtime use cases. bits per unique value.
Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. With improved diagnostic and analytic capabilities, DevOps teams can spend less time troubleshooting. Improve business decisions with precision analytics. Why full-stack observability matters.
Dynatrace is a launch partner in support of AWS Lambda Response Streaming , a new capability enabling customers to improve the efficiency and performance of their Lambda functions. Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes.
Effective ICT risk management Dynatrace Runtime Vulnerability Analytics offers AI-powered risk assessment and intelligent automation for continuous real-time exposure management throughout your entire application stack. Dynatrace Security Analytics can also improve the effectiveness and efficiency of threat hunts.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The data warehouse is not designed to serve point requests from microservices with low latency. Moving data with Bulldozer at Netflix.
Advances in the Industrial Internet of Things (IIoT) and edge computing have rapidly reshaped the manufacturing landscape, creating more efficient, data-driven, and interconnected factories. This proximity reduces latency and enables real-time decision-making.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. Observing AI models Running AI models at scale can be resource-intensive.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
The goal of observability is to understand what’s happening across all these environments and among the technologies, so you can detect and resolve issues to keep your systems efficient and reliable and your customers happy.
Digital experience monitoring enables companies to respond to issues more efficiently in real time, and, through enrichment with the right business data, understand how end-user experience of their digital products significantly affects business key performance indicators (KPIs).
For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites. ” Data from the build process feeds impactful analytics from Davis AI to detect the precise root cause if software fails to meet specific benchmarks. Meanwhile, in the U.S.,
API monitoring captures and analyzes metrics that describe the vital aspects of an application’s performance, which can help developers gain a deeper understanding of the health and efficiency of the APIs they’re utilizing. To understand the importance of API monitoring, consider a website that provides weather information.
Higher latency and cold start issues due to the initialization time of the functions. Observability challenges in serverless applications can be therefore categorized into: Data collection : how to collect metrics, logs and traces from serverless functions efficiently, reliably, and consistently?
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Operational Reporting Pipeline Example Iceberg Sink Apache Iceberg is an open source table format for huge analytics datasets. tactical) in nature.
This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. Adding application security to development and operations workflows increases efficiency. This is the number of failures that affect users’ ability to use an application by the total time in service. Performance.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
TiDB is an open-source, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads. Ideally, a TiDB cluster should always be efficient and problem-free. It should be stable, load-balanced, and have a reliable rate of queries per second (QPS).
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. This evolution in automation, referred to as answer-driven automation, empowers teams to address complex issues in real time, optimize workflows, and enhance overall operational efficiency.
service availability with <50ms latency for an application with no revenue impact. Tailoring SLOs in this way ensures that you’re spending resources making sure that SLOs are met, used efficiently, driving customer value, and helping Developers improve their QA and resolution processes.
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics. With our brand new Azure Front Door page, you get immediate insights into the number of served client requests, latency, and back-end health, so you always have a clear picture of the metrics that really matter.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Using AI for Enhanced Cloud Operations The integration of AI in cloud computing is enhancing operational efficiency in several ways.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. However, having a scalable stream processing platform doesn’t help much if you can’t store data in a cost efficient manner.
Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios. Understanding RabbitMQ as a Message Broker RabbitMQ is a powerful message broker that enables applications to communicate by efficiently directing messages from producers to their intended consumers.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
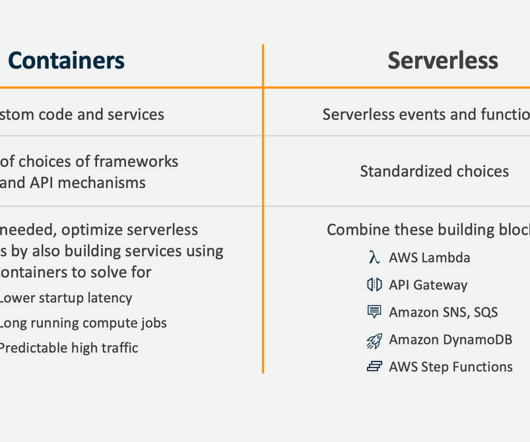
I don’t advocate “Serverless Only”, and I recommended that if you need sustained high traffic, low latency and higher efficiency, then you should re-implement your rapid prototype as a continuously running autoscaled container, as part of a larger serverless event driven architecture, which is what they did.
We will show how we are building a clean and efficient incremental processing solution (IPS) by using Netflix Maestro and Apache Iceberg. As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. past 3 hours or 10 days).
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content