This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Read our documentation and explore how Dynatrace helps you address your regulatory and compliance requirements. Want to learn more?
To continue down the carbon reduction path, IT leaders must drive carbon optimization initiatives into the hands of IT operations teams, arming them with the tools needed to support analytics and optimization. We are updating product documentation to include underlying static assumptions.
This is explained in detail in our blog post, Unlock log analytics: Seamless insights without writing queries. There is no need to think about schema and indexes, re-hydration, or hot/cold storage. Using patent-pending high ingest stream-processing technologies, OpenPipeline currently optimizes data for Dynatrace analytics and AI at 0.5
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Teams have introduced workarounds to reduce storage costs. Current analytics tools are fragmented and lack context for meaningful analysis.
When using Dynatrace, in addition to automatic log collection, you gain full infrastructure context and access to powerful, advanced log analytics tools such as the Logs, Notebooks, and Dashboards apps. For forensic log analytics use cases, the Security Investigator app benefits from the scalability and analytics power of Dynatrace Grail.
Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This decoupling simplifies system architecture and supports scalability in distributed environments.
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . Further reading about Business Analytics : . Digital Business Analytics. Digital Business Analytics: Let’s get started.
This means compromising between keeping data available as long as possible for analysis while juggling the costs and overhead of storage, archiving, and retrieval. Every API call is saved in audit logs to document the complete picture of activities in your environments.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storage engine can have a significant impact on application performance.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSONB storage results in a larger storage footprint.
Security policies give authorized users access to Dynatrace capabilities, such as Grail and its add-ons, exploratory analytics, and Dynatrace AppEngine. ALLOW storage:system:read; The Storage All System Data Read policy grants access to Dynatrace internal data such as auditing events and query execution events.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. And finally, we have an Apache Iceberg layer which stores assets in a denormalized fashion to help answer heavy queries for analytics use cases. Mapping is used to define how documents and their fields are supposed to be stored and indexed.
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
Some of our customers run tens of thousands of storage disks in parallel, all needing continuous resizing. Please see Davis Forecast analysis documentation to learn more about our AutoML approach and which algorithms are used within the Davis Forecast service. This can lead to hundreds of warnings and errors every week. What’s Next?
Many AWS services and third party solutions use AWS S3 for log storage. We hear from our customers how important it is to have a centralized, quick, and powerful access point to analyze these logs; hence we’re making it easier to ingest AWS S3 logs and leverage Dynatrace Log Management and Analytics powered by Grail.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. Analytics without boundaries. Example business events from anywhere. Configuration overview.
Customers can then ingest logs from AWS into the Dynatrace® platform, for in-depth log management and security analytics powered by Grail TM. AWS AppFabric ingests and normalizes audit logs from SaaS applications and delivers them to an Amazon Simple storage service (Amazon S3) bucket in an organization’s AWS account.
You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API. Check our Privacy Rights documentation to stay tuned to our continuous improvements. See documentation for Record deletion in Grail via API.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. documentation. Prometheus Data Source documentation. Dynatrace news. To start leveraging your Prometheus metrics in Dynatrace, please visit: Extension Framework 2.0
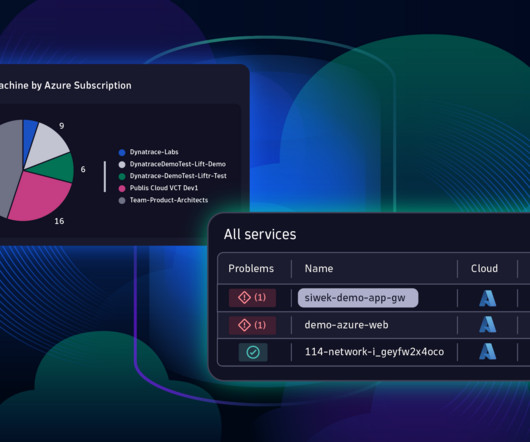
Set up complete monitoring for your Azure subscription with Azure Monitor integration After activating the Azure Native Dynatrace Service (see Dynatrace Documentation for details), the Azure Monitor integration is enabled easily via the Microsoft Azure Portal, as shown in the following screenshot.
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . Further reading about Business Analytics : . Digital Business Analytics. Digital Business Analytics: Let’s get started.
Streamline privacy requirements with flexible retention periods Data retention is a critical aspect of data handling, and it’s not just about privacy compliance—it’s about having the flexibility to optimize data storage times in Grail for your Dynatrace use cases. Other data types will be available soon). What’s next?
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Improved analytic context. Tools that feature client-side compression can help reduce total data transfer volumes and storage footprints. Are these costs consistent?
We do not use it for metrics, histograms, timers, or any such near-real time analytics use case. Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Kinesis Data Analytics. Amazon Simple Storage Service (S3). Dynatrace news. Amazon EC2 Spot Fleet.
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. Improved error handling for unexpected storage issues. (APM-360014).
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. They store data in various formats, including key-value pairs, documents, graphs, and column-family stores. Diverging from MySQLs methodology, MongoDB employs an architecture without fixed schemas.
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. This consistent performance is a big part of why the Snapchat Stories feature , which includes Snapchat's largest storage write workload, moved to DynamoDB.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Kinesis Data Analytics. Amazon Simple Storage Service (S3). Dynatrace news. Amazon EC2 Spot Fleet.
If you’re new to Conductor, this earlier blogpost and the documentation should help you get started and acclimatized to Conductor. External Payload Storage External payload storage was implemented to prevent the usage of Conductor as a data persistence system and to reduce the pressure on its backend datastore.
To generate client-id, refer to our OAuth documentation. This integration allows seamless connectivity to a variety of databases, enabling the real-time retrieval and storage of business data. Configure this similar to [link] Replace tenantid with your tenant ID Client ID to generate token : Client ID used to generate OAuth token.
Further, open source databases can be modified in infinite ways, enabling institutions to meet their specific needs for data storage, retrieval, and processing. Non-relational databases: Instead of tables, non-relational (NoSQL) databases use document-based data storage, column-oriented storage, and graph databases.
You can customize it to display information from sources like Google Analytics, GitHub, Feedly, shell command output, and more. Dash Dash is an online documentation site that presents the Unix man pages (i.e. Storage is in plain text, includes Git-based versioning, wiki-style linking, color themes, and lots more.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. After the successful launch of the first Dynamo system, we documented our experiences in a paper so others could benefit from them. Amazon DynamoDBâ??s
1 among non-relational/document-based systems ( DB-Engines, July 2023 ). Instead of the table-based structure of relational databases, MongoDB stores data in documents and collections, a design for handling large amounts of unstructured data and for real-time web applications. It ranks No.
It’s used for data management (shocker), application development, and data analytics. PostgreSQL has powerful and advanced features, including asynchronous replication, full-text searches of the database, and native support for JSON-style storage, key-value storage, and XML. How-to documentation is readily available.
IT professionals are familiar with scoping the size of VMs with regards to vCPU, memory, and storage capacity. Memory optimized – High memory-to-CPU ratio, relational database servers, medium to large caches, and in-memory analytics. Storage optimized – High disk throughput and IO. Premium storage support. Generation.
We explore how you can use web analytics or real user measurement data on your website to get insight into any imposter domains re-publishing your work. A better approach is to use the data you are already collecting with your web analytics or R eal U ser M easurement ( RUM ) services. Turning The Data Into Information.
More recently weve expanded our platform to include additional forms of user interaction observation in support of our real-time analytics – here weve begun to leverage NoSQL technologies like Redis. Of course, with as much textual data as we have we are leveraging Lucene/SOLR (a NoSQL solution) for Search and Semantic processing.
Online analytical processing , OLAP : Online analytical processing applications enable users to analyze multidimensional data interactively from multiple perspectives which consist of three basic analytical operations: . The CITUS columnar extension feature set includes: Highly compressed tables: Reduces storage requirements.
It can be used to power new analytics, insight, and product features. It can be used to power new analytics, insight, and product features. These nodes and edges require a good amount of compute and storage which is typically distributed across a large number servers either running in the cloud or your own data center.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content