This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What is an MPP Database?
This is explained in detail in our blog post, Unlock log analytics: Seamless insights without writing queries. There is no need to think about schema and indexes, re-hydration, or hot/cold storage. Using patent-pending high ingest stream-processing technologies, OpenPipeline currently optimizes data for Dynatrace analytics and AI at 0.5
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. Yet, the impact of choosing the right NoSQL database goes beyond these parameters; it affects your business outcomes.
What is log analytics? Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. In what follows, we explore log analytics benefits and challenges, as well as a modern observability approach to log analytics.
What is log analytics? Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. In what follows, we explore log analytics benefits and challenges, as well as a modern observability approach to log analytics.
Information related to user experience, transaction parameters, and business process parameters has been an unretrieved treasure, now accessible through new and unique AI-powered contextual analytics in Dynatrace. Executives drive business growth through strategic decisions, relying on data analytics for crucial insights.
Almost daily, teams have requests for new toolsfor database management, CI/CD, security, and collaborationto address specific needs. Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost.
Microsoft Azure SQL is a robust, fully managed database platform designed for high-performance querying, relational data storage, and analytics. For a typical web application with a backend, it is a good choice when we want to consider a managed database that can scale both vertically and horizontally.
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Enter Grail-powered data and analytics.
To stay competitive in an increasingly digital landscape, organizations seek easier access to business analytics data from IT to make better business decisions faster. Five constraints that limit insights from business analytics data. Digital businesses rely on real-time business analytics data to make agile decisions.
A traditional log-based SIEM approach to security analytics may have served organizations well in simpler on-premises environments. Security Analytics and automation deal with unknown-unknowns With Security Analytics, analysts can explore the unknown-unknowns, facilitating queries manually in an ad hoc way, or continuously using automation.
Modern tech stacks such as Apache Spark, Azure Data Factory, Azure Databricks, and Azure Synapse Analytics offer powerful tools for building optimized data pipelines that can efficiently ingest and process data on the cloud. It provides built-in connectors for various data sources such as databases, file systems, cloud storage, and more.
Grail combines the big-data storage of a data warehouse with the analytical flexibility of a data lake. With Grail, we have reinvented analytics for converged observability and security data,” Greifeneder says. This unified approach enables Grail to vault past the limitations of traditional databases.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Similar to the tutorial extension, we created an extension that performs queries against databases.
Seamlessly report and be alerted on non-topology-related custom metrics, using Dynatrace as a metric database. Because you can now seamlessly report non-topological metrics, you can now use Dynatrace as a metric database. The post Intelligent, context-aware AI analytics for all your custom metrics appeared first on Dynatrace blog.
The ELK stack is an abbreviation for Elasticsearch, Logstash, and Kibana, which offers the following capabilities: Elasticsearch: a scalable search and analytics engine with a log analytics tool and application-formed database, perfect for data-driven applications.
We will use a graph database such as Neo4j to store the information. Additionally, we can use columnar databases like Cassandra to store information like user feeds, activities, and counters. After that, the post gets added to the feed of all the followers in the columnar data storage. Sample Queries supported by Graph Database.
As an application owner, product manager, or marketer, however, you might use analytics tools like Adobe Analytics to understand user behavior, user segmentation, and strategic business metrics such as revenue, orders, and conversion goals. Enable the storage types, select Add property.
These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. They can call on dozens of databases and deliver gigabytes of data across myriad devices. A modern approach to log analytics stores data without indexing.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. The dashboard tracks a histogram chart of total storage utilized with logs daily. It also tracks the top five log producers by entity.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
They’re unleashing the power of cloud-based analytics on large data sets to unlock the insights they and the business need to make smarter decisions. From a technical perspective, however, cloud-based analytics can be challenging. The sheer number of permutations can break traditional databases.
Follower clusters are a ScaleGrid feature that allows you to keep two independent database systems (of the same type) in sync. Note: ScaleGrid implements follower clusters using storage snapshots. It is not available for our in-memory database offerings like hosting for Redis™*. Database Dev/Test Setup. Data Analytics.
Why should a relational database even care about unstructured data? If you store each of the keys as columns, it will result in frequent DML operations – this can be difficult when your data set is large - for example, event tracking, analytics, tags, etc. JSON database in 9.2 JSONB Patterns & Antipatterns.
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. ” In many cases, indexed databases only provide access to a sample of statistical data summaries.
A common question that I get is why do we offer so many database products? To do this, they need to be able to use multiple databases and data models within the same application. Seldom can one database fit the needs of multiple distinct use cases. Seldom can one database fit the needs of multiple distinct use cases.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking.
The choice of self-managed cloud databases vs DBaaS is a common debate among those who are looking for the best option that will cater to their particular needs. Database as a Service (DBaaS) and managed databases offer distinct advantages along with certain challenges.
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. References. Vander-Zaden, H.M. Durand and P.
PostgreSQL is an open source object-relational database system that has soared in popularity over the past 30 years from its active, loyal, and growing community. For the 2nd year in a row, PostgreSQL has kept the title of #1 fastest growing database in the world according to the DBMS of the Year report by the experts at DB-Engines.
AWS Certified Database – Specialty: Database specialists with deep knowledge of relational and non-relational databases and some AWS experience might want to check out this certification. Data analytics. The top AWS certification options. So, what are the best AWS certifications? Machine learning.
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. We do not use it for metrics, histograms, timers, or any such near-real time analytics use case. Storage Layer The storage layer for TimeSeries comprises a primary data store and an optional index data store.
million” – Gartner Data observability is a practice that helps organizations understand the full lifecycle of data, from ingestion to storage and usage, to ensure data health and reliability. Data observability is crucial to analytics and automation, as business decisions and actions depend on data quality.
Retention-based deletion is governed by a policy outlining the duration for which data is stored in the database before it’s deleted automatically. For instance, if data is mistakenly ingested into the database, it may need to be deleted to prevent inaccuracies or sensitive data from being stored.
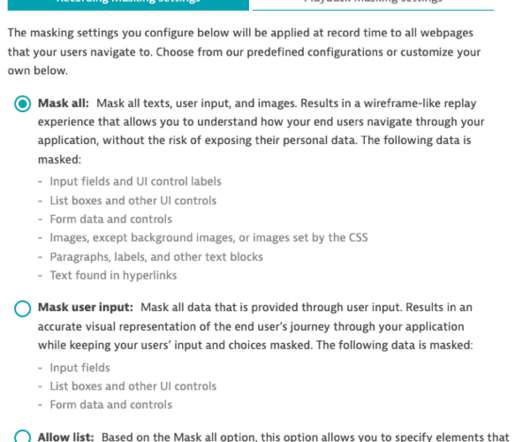
Azure supporting services (Synapse Analytics). DL/I segment name for DL/I databases. RUM linking timeouts adjusted in transaction storage. (APM-341299). The trace list now correctly supports sorting on the number of database calls. (APM-340223). Masking v1. Masking v2. See Available metrics. Improved host settings UI.
The use of open source databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “open source database” really is and what it offers. What is an open source database?
Driving down the cost of Big-Data analytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of data analytics in the cloud. Hadoop is quickly becoming the preferred tool for this type of large scale data analytics.
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
Azure Data Lake Analytics. Azure Data Lake Storage Gen1. Manual tasks like shutting down virtual machines in bulk or creating database backups can be error prone. We’re happy to announce that now you can gain cloud monitoring excellence with Dynatrace for 15 additional Azure services, including: Azure Automation Account.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content