This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data.
Driven by that value, Dynatrace brings real-time observability, security, and business data into context and makes sense of it so our customers can get answers, automate, predict, and prevent. Executives are sitting on a goldmine of data, and they don’t know it. Common business analytics incur too much latency.
This is an article from DZone's 2023 Data Pipelines Trend Report. For more: Read the Report We live in an era of rapid data generation from countless sources, including sensors, databases, cloud, devices, and more. Stream processing is used to query a continuous stream of data and immediately process events in that stream.
In a digital-first world, site reliability engineers and IT data analysts face numerous challenges with data quality and reliability in their quest for cloud control. Increasingly, organizations seek to address these problems using AI techniques as part of their exploratory dataanalytics practices.
Key benefits of Runtime Vulnerability Analytics Managing application vulnerabilities is no small feat. Traditional tools often overload you with data, making it challenging to identify which vulnerabilities actually put your environment at risk. Please see the instructions in Dynatrace Documentation. Not a Dynatrace customer yet?
With 99% of organizations using multicloud environments , effectively monitoring cloud operations with AI-driven analytics and automation is critical. IT operations analytics (ITOA) with artificial intelligence (AI) capabilities supports faster cloud deployment of digital products and services and trusted business insights.
Logs provide answers, but monitoring is a challenge Manual tagging is error-prone Making sure your required logs are monitored is a task distributed between the data owner and the monitoring administrator. Finding the right logs is cumbersome Even if your logs are monitored, you need to make sense of the vast data volume.
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. The only way to address these challenges is through observability data — logs, metrics, and traces. Teams interact with myriad data types.
Existing siloed tools lead to inefficient workflows, fragmented data, and increased troubleshooting times. Rather than relying on disparate tools for each environment and team, Dynatrace integrates all data into one cohesive platform. As a result, dedicated data pipeline tools are unnecessary for preprocessing data before ingestion.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
Data processing in the cloud has become increasingly popular due to its scalability, flexibility, and cost-effectiveness. This article will explore how these technologies can be used together to create an optimized data pipeline for data processing in the cloud.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. Yet, the impact of choosing the right NoSQL database goes beyond these parameters; it affects your business outcomes. How do these metrics translate into real-world value for your business?
Understanding Teradata Data Distribution and Performance Optimization Teradata performance optimization and database tuning are crucial for modern enterprise data warehouses.
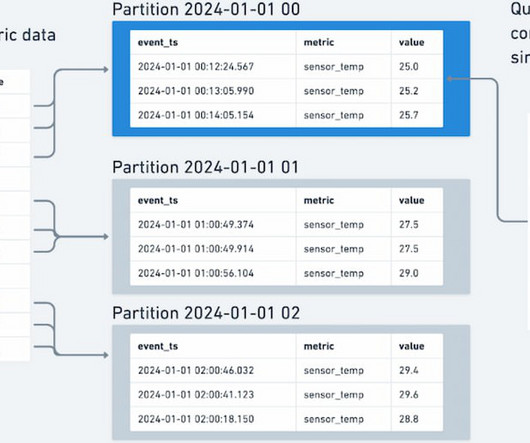
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures. Time series data has become an essential part of data collection in various fields due to its ability to capture trends, patterns, and anomalies.
While applications are built using a variety of technologies and frameworks, there is one thing they usually have in common: the data they work with must be stored in databases. Now, Dynatrace has gone a step further and expanded its coverage and intelligent observability into the next layer: database infrastructure.
The massive volumes of log data over months, sometimes years, of a breach have made this a complicated and expensive problem to solve. A traditional log-based SIEM approach to security analytics may have served organizations well in simpler on-premises environments. and “was any sensitive data stolen?”
What is log analytics? Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. In what follows, we explore log analytics benefits and challenges, as well as a modern observability approach to log analytics.
What is log analytics? Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. In what follows, we explore log analytics benefits and challenges, as well as a modern observability approach to log analytics.
Authors: Ruoxi Sun (Tech Lead of Analytical Computing Team at PingCAP). TiDB is a Hybrid Transaction/Analytical Processing (HTAP) database that can efficiently process analytical queries. Fei Xu (Software Engineer at PingCAP).
Ready to transition from a commercial database to open source, and want to know which databases are most popular in 2019? Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy? Polyglot Persistence Trends : Number of Databases Used & Top Combinations.
How do I solve issues quickly while meeting every regional data privacy regulation? Most monitoring tools lack stringent data privacy controls, which could impact the data privacy of end-users. How do I connect the dots between mobile analytics and performance monitoring? Location data masking. IP address masking.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. Analysis of such large data sets often requires powerful distributed data stores like Hadoop and heavy data processing with techniques like MapReduce.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
Microsoft Azure SQL is a robust, fully managed database platform designed for high-performance querying, relational data storage, and analytics. For a typical web application with a backend, it is a good choice when we want to consider a managed database that can scale both vertically and horizontally.
A key element of effectively leveraging observability is analyzing telemetry data in context. Manual and configuration-heavy approaches to putting telemetry data into context and connecting metrics, traces, and logs simply don’t scale. PurePath traces provide a transaction-centric view across all telemetry data.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. However, as we highlighted previously, business data can be significantly more complex than simple metrics.
They frequently articulate the need for real-time visibility into business data to support agile business decisions. But existing business intelligence (BI) tools often lack the broad context, ease of data access, and real-time insights needed to understand and improve customer experience and complex business processes.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. They’re unleashing the power of cloud-based analytics on large data sets to unlock the insights they and the business need to make smarter decisions. All of these factors challenge DevOps maturity.
In this blog post, we’ll use Dynatrace Security Analytics to go threat hunting, bringing together logs, traces, metrics, and, crucially, threat alerts. However, our customers often want to augment the data Dynatrace provides with data from third-party tools.
I have ingested important custom data into Dynatrace, critical to running my applications and making accurate business decisions… but can I trust the accuracy and reliability?” ” Welcome to the world of data observability. At its core, data observability is about ensuring the availability, reliability, and quality of data.
If you’re running SAP, you’re likely already familiar with the HANA relational database management system. HANA maintains all the business and analyticsdata that your business runs on. Today we’re proud to announce that we’ve extended our SAP monitoring capabilities to support SAP HANA databases.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
It provides an easy way to select, integrate, and customize foundation models with enterprise data using techniques like retrieval-augmented generation (RAG), fine-tuning, or continued pre-training. Full-stack tracing: Track each user request across multiple FMs, vector databases, orchestrators (LangChain), and custom business logic.
It is an open standard format which organizes data into key/value pairs and arrays detailed in RFC 7159. JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. You can also check out our Working with JSON Data in PostgreSQL vs. JSONB Patterns & Antipatterns.
There are no hosts, no backend, no database – just HTML, CSS, and JavaScript. The app pulls all of the data from GitHub and Dynatrace APIs. With that simple copy-paste, I now have all the performance, errors, and user experience data for BizOpsConfigurator! Now we have performance and errors all covered: Business Analytics.
Structured Query Language (SQL) is a simple declarative programming language utilized by various technology and business professionals to extract and transform data. To conclude, GUIs are a vital addition to ease the lives of database users and developers.
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement dataanalytics models to discover customer behaviour with the goal of maximizing user joy.
As an application owner, product manager, or marketer, however, you might use analytics tools like Adobe Analytics to understand user behavior, user segmentation, and strategic business metrics such as revenue, orders, and conversion goals. Common examples of data points that makes sense to have in many systems are: Session IDs.
Dynatrace recently opened up the enterprise-grade functionalities of Dynatrace OneAgent to all the data needed for observability, including metrics, events, logs, traces, and topology data. Seamlessly report and be alerted on non-topology-related custom metrics, using Dynatrace as a metric database. Dynatrace news.
SSRF can lead to unauthorized access to sensitive data, such as cloud metadata, internal databases, and other protected resources. Notable breaches, such as the Capital One data breach, have demonstrated the severe impact of SSRF, where attackers exploited an SSRF vulnerability to access AWS metadata and gain privileged access.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content