This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, amidst this rapid evolution, ensuring a robust data universe characterized by high quality and integrity is indispensable. While much emphasis is often placed on refining AI models, the significance of pristine datasets can sometimes be overshadowed.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that dataanalytics is key to driving informed business decision-making.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch data pipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Data pipeline asset management with Dataflow.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This queue ensures we are consistently capturing raw events from our global userbase.
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley.
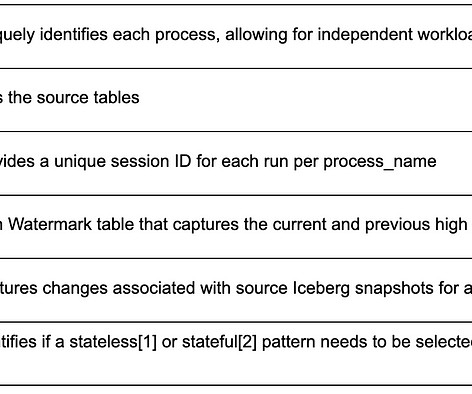
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Alex Diamond This Q&A aims to mythbust some common misconceptions about succeeding in analytics at a big tech company. Working in Studio Data Science & Engineering (“Studio DSE”) was basically a dream come true.
Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. Curious to learn more about other Data Science and Engineering functions at Netflix?
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. In the Reliability space, our data teams focus on two main approaches.
In this tutorial, you are going to learn about QuestDB SQL extensions which prove to be very useful with time-series data. Using some sample data sets, you will learn how designated timestamps work and how to use extended SQL syntax to write queries on time-series data.
Part of our series on who works in Analytics at Netflix?—?and I’m a Senior AnalyticsEngineer on the Content and Marketing Analytics Research team. Being an AnalyticsEngineer is like being a hybrid of a librarian ?? One of my favorite things about being an AnalyticsEngineer is the variety.
Stephanie Lane , Wenjing Zheng , Mihir Tendulkar Source credit: Netflix Within the rapid expansion of data-related roles in the last decade, the title Data Scientist has emerged as an umbrella term for myriad skills and areas of business focus. Learning through data is in Netflix’s DNA. It can be hard to know from the outside.
Previously, I wrote about Amazon QuickSight , a new service targeted at business users that aims to simplify the process of deriving insights from a wide variety of data sources quickly, easily, and at a low cost. Put simply, data is not always readily available and accessible to organizational end users. Enter Amazon QuickSight.
Database selection is a challenge every dataengineer faces. Among the many databases available, Apache Doris and ClickHouse, as two mainstream analytical databases, are often compared. Each has its strengths and is suited to different scenarios, making the choice difficult.
In June 2021, we asked the recipients of our Data & AI Newsletter to respond to a survey about compensation. The average salary for data and AI professionals who responded to the survey was $146,000. We didn’t use the data from these respondents; in practice, discarding this data had no effect on the results.
Scripts and procedures usually focus on a particular task, such as deploying a new microservice to a Kubernetes cluster, implementing data retention policies on archived files in the cloud, or running a vulnerability scanner over code before it’s deployed. Big data automation tools. Batch process automation.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems. At Netflix we publish the Flow Log data to Amazon S3. And in order to gain visibility into these logs, we need to somehow ingest and enrich this data.
Data ingestion is the foremost layer in a dataengineering pipeline, acting as a vital pillar in the overall analytics architecture. Thus, it is essential to implement data ingestion just right. Here is everything you need to know to take the first step toward a flawless data pipeline.
We live in a world where massive volumes of data are generated from websites, connected devices and mobile apps. In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis and ad targeting require deriving insights from these data.
Building data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects.
Setting up a data warehouse is the first step towards fully utilizing big data analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
ETL refers to extract, transform, load and it is generally used for data warehousing and data integration. There are several emerging data trends that will define the future of ETL in 2018. A common theme across all these trends is to remove the complexity by simplifying data management as a whole.
STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. SUS312 How innovators are driving more sustainable manufacturing — Marcus Ulmefors Northvolt Director Data and ML Platforms and Muhammad Sajid AWS SA. AWS Inferentia 2.6x
This article is the last in a multi-part series sharing a breadth of AnalyticsEngineering work at Netflix, recently presented as part of our annual internal AnalyticsEngineering conference. This solution enabled data to be used more effectively for real-time decision-making. Need to catch up?
This diverse technological landscape generates extensive and rich data from various infrastructure entities, from which, dataengineers and analysts collaborate to provide actionable insights to the engineering organization in a continuous feedback loop that ultimately enhances the business.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content