This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article sets out to explore some of the essential tools required by organizations in the domain of dataengineering to efficiently improve data quality and triage/analyze data for effective business-centric machine learning analytics, reporting, and anomaly detection.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Let’s dive in!
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. The Flink jobs sink is equipped with a data mesh connector, as detailed in our Data Mesh platform which has two outputs: Kafka and Iceberg.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. In the Efficiency space, our data teams focus on transparency and optimization.
Ultimately, IT automation can deliver consistency, efficiency, and better business outcomes for modern enterprises. Automating IT practices offers enterprises faster data centers and cloud operations, as well as increased flexibility and accuracy. IT automation tools can achieve enterprise-wide efficiency. Read eBook now!
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley.
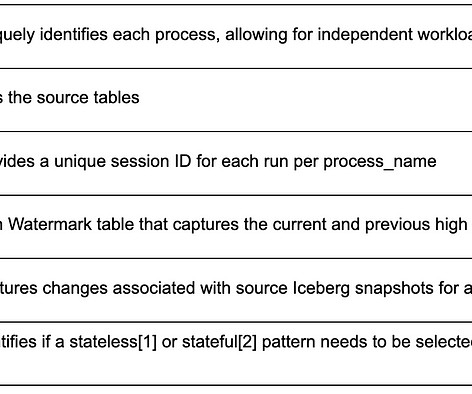
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with dataanalytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. We will show how we are building a clean and efficient incremental processing solution (IPS) by using Netflix Maestro and Apache Iceberg. Users configure the workflow to read the data in a window (e.g.
Building data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects.
A unified data management (UDM) system combines the best of data warehouses, data lakes, and streaming without expensive and error-prone ETL. It offers reliability and performance of a data warehouse, real-time and low-latency characteristics of a streaming system, and scale and cost-efficiency of a data lake.
Curious to learn more about other Data Science and Engineering functions at Netflix? To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham.
This article is the last in a multi-part series sharing a breadth of AnalyticsEngineering work at Netflix, recently presented as part of our annual internal AnalyticsEngineering conference. Its easier to develop and maintain, and tends to be more familiar for analyticsengineers, data scientists, and dataengineers.
STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. AWS Inferentia 2.6x shorter training time, saving 54% energy and 75% cost. Good example, well presented interesting new material.
Our ecosystem enables engineering teams to run applications and services at scale, utilizing a mix of open-source and proprietary solutions. In turn, our self-serve platforms allow teams to create and deploy, sometimes custom, workloads more efficiently. The standardized data model and processing promotes scalability and consistency.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content