This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article sets out to explore some of the essential tools required by organizations in the domain of dataengineering to efficiently improve data quality and triage/analyze data for effective business-centric machine learning analytics, reporting, and anomaly detection.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that dataanalytics is key to driving informed business decision-making.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Alex Diamond This Q&A aims to mythbust some common misconceptions about succeeding in analytics at a big tech company. Within a few months I’d picked up BI tools, predictive modeling, and data ingestion/ETL.
Part of our series on who works in Analytics at Netflix?—?and I’m a Senior AnalyticsEngineer on the Content and Marketing Analytics Research team. Being an AnalyticsEngineer is like being a hybrid of a librarian ?? One of my favorite things about being an AnalyticsEngineer is the variety.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. We can experiment with different content placements or promotional strategies to boost visibility and engagement.
They require teams of dataengineers to spend months building complex data models and synthesizing the data before they can generate their first report. Data is automatically replicated across multiple Availability Zones for redundancy and also backed up to S3 for durability. How you can get started.
Database selection is a challenge every dataengineer faces. Among the many databases available, Apache Doris and ClickHouse, as two mainstream analytical databases, are often compared. Each has its strengths and is suited to different scenarios, making the choice difficult.
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. What will be the cost of rolling out the winning cell of an AB test to all users?
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with dataanalytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
A large number of our data users employ SparkSQL, pyspark, and Scala. A small but growing contingency of data scientists and analyticsengineers use R, backed by the Sparklyr interface or other data processing tools, like Metaflow.
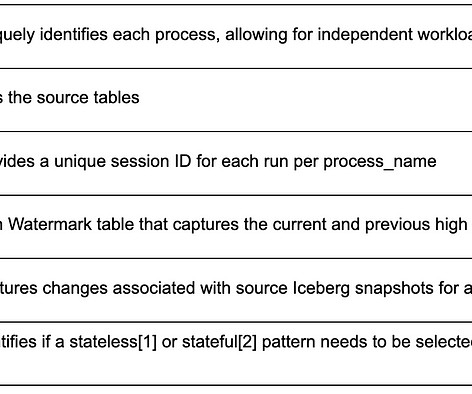
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
This requires significant dataengineering efforts, as well as work to build machine-learning models. Big data automation tools. These tools provide the means to collect, transfer, and process large volumes of data that are increasingly common in analytics applications. Creating a sound IT automation strategy.
However, in recent years there has been an exponential increase in the amount of data that connected systems produce, which has brought about a need for new ways to store and analyze such information.
Curious to learn more about other Data Science and Engineering functions at Netflix? To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham.
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
While BI solutions have existed for decades, customers have told us that it takes an enormous amount of time, engineering effort, and money to bridge this gap. These solutions lack interactive data exploration and visualization capabilities, limiting most business users to canned reports and pre-selected queries.
Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems. These characteristics allow for an on-call response time that is relaxed and more in line with traditional big dataanalytical pipelines.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
Data ingestion is the foremost layer in a dataengineering pipeline, acting as a vital pillar in the overall analytics architecture. Thus, it is essential to implement data ingestion just right. Here is everything you need to know to take the first step toward a flawless data pipeline.
Building data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines. Data pipeline initiatives are generally unfinished projects.
We also asked respondents what tools they used for statistics and machine learning and what platforms they used for dataanalytics and data management. The highest salaries were associated with Clicktale (now ContentSquare), a cloud-based analytics system for researching customer experience: only 0.2% The Last Word.
Setting up a data warehouse is the first step towards fully utilizing big data analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Data solution vendors like SnapLogic and Informatica are already developing machine learning and artificial intelligence (AI) based smart data integration assistants. These assistants can recommend next-best-action or suggest datasets, transforms, and rules to a dataengineer working on a data integration project.
STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. AWS Inferentia 2.6x shorter training time, saving 54% energy and 75% cost. Good example, well presented interesting new material.
This article is the last in a multi-part series sharing a breadth of AnalyticsEngineering work at Netflix, recently presented as part of our annual internal AnalyticsEngineering conference. Its easier to develop and maintain, and tends to be more familiar for analyticsengineers, data scientists, and dataengineers.
This diverse technological landscape generates extensive and rich data from various infrastructure entities, from which, dataengineers and analysts collaborate to provide actionable insights to the engineering organization in a continuous feedback loop that ultimately enhances the business.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content