This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The previous article described the caching algorithms used by Caffeine , in particular the eviction and concurrency models. This allows for quickly discarding new arrivals that are unlikely to be used again, guarding the main region from cache pollution.
We have chosen this NoSQL based solution over relational databases as it provides the scalability to have hierarchies which go beyond two levels and extensibility due to the schema-less behavior of NoSQL data storage. We will use a cache having an LRU based eviction policy for caching user feeds of active users. Optimization.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). People Analytics Can we support AB experiments related to recruiting and help improve candidate experience as well as attract solid talent?
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. Simplify error analytics. Built for enterprise scalability. With SnapStart enabled, function code is initialized once when a function version is published.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. In addition to storing item size information in the page token, the server also estimates the average item size for a given namespace and caches it locally.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Application example: user profile cache, where profiles are constructed elsewhere (e.g., Author & founder of BangDB. Workload C: Read only. This workload is 100% read.
Since then we’ve introduced Amazon Kinesis for real-time streaming data, AWS Lambda for serverless processing, Apache Spark analytics on EMR, and Amazon QuickSight for high performance Business Intelligence. is a software company providing unified business communications solutions for call centers, including real-time reporting and analytics.
Implement appropriate caching layers (for example, read-only cache for static data). For a deeper look into these and many other recommendations, my colleagues and I wrote an eBook about performance and scalability on the topic. Reduce inter-process communications overhead. Implement intelligent retry and failover processes.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. We do not use it for metrics, histograms, timers, or any such near-real time analytics use case.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
Digital Experience Monitoring (DEM) – A fully integrated DEM enables monitoring of the end-user experience for your applications while also providing data for business-level analytics. Organic scalability of the monitoring platform with the applications. Dynatrace does this by querying Azure monitor APIs to collect platform metrics.
Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization. DevOps practitioners struggle to maintain highly available and scalable applications. Experienced database administrators learn to spot patterns that can lead to common problems.
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. Cache all the things. Cache all the things. VLDB’19. are divided. Making Procella fast.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Werner Vogels weblog on building scalable and robust distributed systems. Today AWS has launched Amazon ElastiCache , a new service that makes it easy to add distributed in-memory caching to any application. Systems that make extensive use of caching almost all report a significant reduction in the cost of their database tier.
Cluster and container Log Analytics. REDIS for caching. 3 Log Analytics. If you want to learn more about log analytics, check out my YouTube tutorial on Log Analytics and look out for our product team’s blog on log analytics. Full-stack observability. End-to-end code-level tracing. Service mash insights.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. They may even help develop personalized web analytics software as well as leverage Hashes, Bitmaps, or Streams from Redis Data Types into a wider scope of applications such as analytic operations.
Senior DevOps Engineer : Your engineering work will focus on using your deep knowledge of the web stack including firewalls, web applications, caches and data stores to create innovative infrastructure architectures that are resilient, scalable, and blazingly fast.
WiredTiger is a good all-purpose engine while In-Memory is better for specific use cases such as real-time analytics. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. released in December 2015.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
But as companies grow and see more demand for their databases, we need to ensure that PMM also remains scalable so you don’t need to worry about its performance while tending to the rest of your environment. VictoriaMetrics maintains an in-memory cache for mapping active time series into internal series IDs.
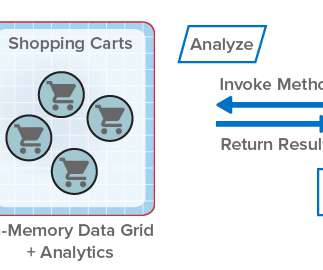
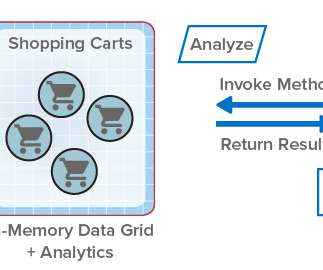
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. It also transparently makes use of the IMDG’s scalable computing resources to accelerate the analysis.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. They may even help develop personalized web analytics software as well as leverage Hashes, Bitmaps, or Streams from Redis Data Types into a wider scope of applications such as analytic operations.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. There are two main types of DNS servers: authoritative servers and caching resolvers.
Werner Vogels weblog on building scalable and robust distributed systems. The storage systems weve pioneered demonstrate extreme scalability while maintaining tight control over performance, availability, and cost. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. If you have a largely static site you can rely on the enormous power of S3 to make serving your content highly scalable and storing it extremely durable. My templates and blog posts are now located in DropBox and thus locally cached at each machine I use.
Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers. One or more specified cache servers are unavailable, which could be caused by busy network or servers. …). Please retry later.
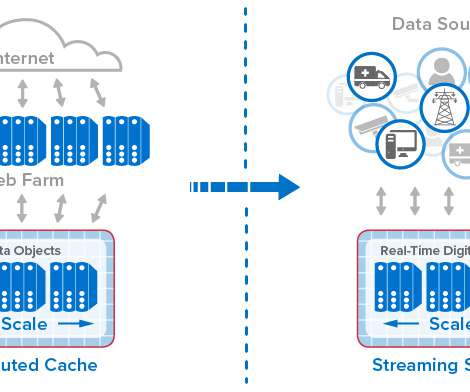
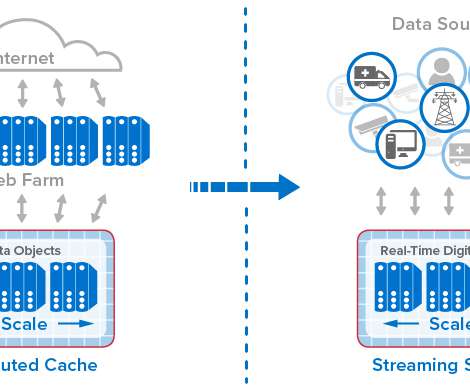
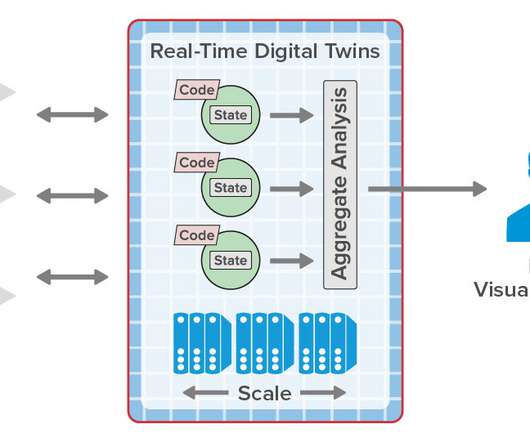
From Distributed Caches to Real-Time Digital Twins. In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
From Distributed Caches to Real-Time Digital Twins. In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
DBAs and developers appreciate its combination of flexibility, scalability, and performance. It’s a good setup for real-time analytics and high-speed logging. It’s an open source distributed NoSQL database that offers high scalability and availability. Do it without licensing costs and vendor lock-in.
The TPC designed benchmarks for transaction processing (OLTP) and analytics (OLAP) and anyone can run these benchmarks, have them audited by the TPC and published on the official benchmark rankings. When testing database performance there are 2 distinct workloads, transactional or OLTP and analytic (data warehouse, decision support) or OLAP.
Redis's microsecond latency has made it a de facto choice for caching. Its support for advanced data structures (for example, lists, sets, and sorted sets) also enables a variety of in-memory use cases such as leaderboards, in-memory analytics, messaging, and more. TB of in-memory capacity in a single cluster.
But once we had a good understanding, we knew exactly what to look for and began analyzing the analytics of our user data to identify areas that could be improved. We can then forward this data to a custom analytics service. We realized that we needed to consider a more global and scalable solution to better serve our global audience.
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks. This telematics architecture has evolved to handle ever increasing message rates (often reaching 2K messages per second), make up-to-the-minute information available to dispatchers, and feed offline analytics.
In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream. Kafka messaging queue is well known implementation of such a buffer that also supports scalable distributed deployments, fault-tolerance, and provides high performance.
RUM or analytics data (funnel analysis) can help you determine the user flows that drive the majority of your business and that will be most critical on high-load days. Traffic patterns outside of normal [RUM or Analytics]. Drop in cart completions, increase in abandonment or other key conversion events [RUM or Analytics].
WordPress VIP is a comprehensive WordPress development service for organizations requiring top-notch performance and a scalable and secure website platform. Performance scalability: Using WordPress VIP, users can handle significant traffic and sudden visitor spikes. Key Features of WordPress VIP! WordPress VIP boosts customization.
Most of the CMS vendors dodge questions of evolution by talking about incremental innovation primarily focused on customer experience (CX) such as analytics and personalisation. Using JAMstack delivers better performance, higher scalability with less cost, and overall a better developer experience as well as user experience.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. A key challenge in using an IMDG as part of a cloud-hosted application is to easily deploy, access, and manage the IMDG.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. The Need to Keep It Simple. A key challenge in using an IMDG as part of a cloud-hosted application is to easily deploy, access, and manage the IMDG.
Hyper Dimension Shuffle describes how Microsoft improved the cost of data shuffling, one of the most costly operations, in their petabyte-scale internal big data analytics platform, SCOPE. Unifying consensus and atomic commit looks at the advantages of combining scalability (consensus) and fault-tolerant mechanisms into one unified protocol.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content