This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. Author & founder of BangDB.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. It also serves as central configuration of access patterns such as consistency or latency targets.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. We can use cloud technologies such as Amazon Kinesis or Azure Stream Analytics for collecting, processing, and analyzing real-time, streaming data to get timely insights and react quickly to new information(e.g.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical. Load time and network latency metrics. Minimizing the number of network requests that your app makes can improve performance by reducing latency and improving load times.
The result is a framework that offers a single source of truth and enables companies to make the most of advanced analytics capabilities simultaneously. The performance of these queries needs to be at a level where they can support ad-hoc analytics use cases. Data lakehouses deliver the query response with minimal latency.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Uber’s interactive analytics team shares how they integrated Alluxio’s data caching into Presto, the SQL query engine powering thousands of daily active users on petabyte scale at Uber, to dramatically reduce data scan latencies through leveraging Presto on local disks.
This is where unified observability and Dynatrace Automations can help by leveraging causal AI and analytics to drive intelligent automation across your multicloud ecosystem. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Oh, and in additional to low latency, “ we require access to fresh data.” Cache all the things.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database.
WiredTiger is a good all-purpose engine while In-Memory is better for specific use cases such as real-time analytics. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
There are two main types of DNS servers: authoritative servers and caching resolvers. But the real robustness of the DNS system comes through the way lookups are handled, which is what caching resolvers do. Caching techniques ensure that the DNS system doesnt get overloaded with queries. No Server Required - Jekyll & Amazon S3.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
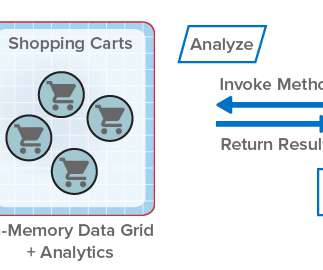
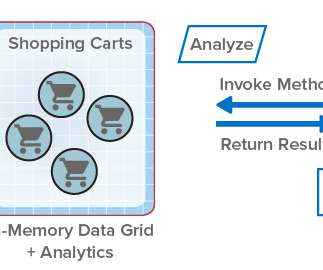
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Take a look at how integrated data analytics can help client applications. The Challenges with Parallel Queries.
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Take a look at how integrated data analytics can help client applications. The Challenges with Parallel Queries.
Redis's microsecond latency has made it a de facto choice for caching. Its support for advanced data structures (for example, lists, sets, and sorted sets) also enables a variety of in-memory use cases such as leaderboards, in-memory analytics, messaging, and more. TB of in-memory capacity in a single cluster.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later.
Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions. These distributed storage services also play a pivotal role in big data and analytics operations.
But once we had a good understanding, we knew exactly what to look for and began analyzing the analytics of our user data to identify areas that could be improved. We can then forward this data to a custom analytics service. One of the key Next.js These edge servers are distributed in data centers across the globe.
Analytic models—including simple ones like Amdahl’s Law —represent a third, often underused, evaluation method that can provide insight for both practice and research, albeit with less accuracy. How many buffers are needed to track pending requests as a function of needed bandwidth and expected latency? Answered in Part 2.).
This data is distinct from CrUX because it’s collected directly by the website owner by installing an analytics snippet on their website. INP is a measure of the latency for all interactions on a given page, where the highest latency — or close to it — informs the final score. It’s right there in the name!
smart cameras & analytics) to interactive/immersive environments and autonomous driving (e.g. Each of these categories opens up challenging problems in AI/visual algorithms, high-density computing, bandwidth/latency, distributed systems. cameras) in many usages ranging from digital security/surveillance and automated retail (e.g.
To mitigate the performance issues, we had to add a lot of (unbudgeted) extra servers and had to aggressively cache pages on a reverse proxy. It can be hosted on a CDN like Vercel or Netlify, which results in lower latency. Vercel also offers an Analytics feature , which measures the core Web Vitals of your production deployment.
It’s a good setup for real-time analytics and high-speed logging. Redis can handle a high volume of operations per second, making it useful for running applications that require low latency. Couchbase Couchbase is a distributed document store with a powerful search engine and built-in operational and analytical capabilities.
Previously, Part 1 of these two blog posts provided our thesis that analytic models can complement measurement and simulations to give quick insight, show what is not possible, provide a double-check, and suggest future directions. How many buffers are needed to track pending requests as a function of needed bandwidth and expected latency?
Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time. This system also had significantly lower memory latency than many contemporary systems (which were still using front-side bus architectures and separate “NorthBridge” chips).
This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs. In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream.
Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user. They allow you to cache resources on the user's device when they visit your site for the first time. CPU Utilization and Power Consumption (Source: Blackburn 2008).
Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user. They allow you to cache resources on the user's device when they visit your site for the first time. CPU Utilization and Power Consumption (Source: Blackburn 2008).
Without effective caching on the client, the server will see an increase in workload, more CPU usage and ultimately increased latency for the end user. They allow you to cache resources on the user's device when they visit your site for the first time. CPU Utilization and Power Consumption (Source: Blackburn 2008).
A particular problem occurs when a reporting / analytical workload shares storage with a transactional workload. In such a case we have a Bandwidth heavy workload profile (reporting) sharing with a Latency Sensitive workload (transactional). The key thing to observe is the impact on the latency sensitive (OLTP) workload.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously.
â€A CDN, or Content Delivery Network, is a network of servers strategically positioned across various locations to expedite content delivery to users based on their geographic location.These patterns split into two main forms of traffic:Static Traffic: When a user request targets static content, the CDN first checks its cache.
It offers reliability and performance of a data warehouse, real-time and low-latency characteristics of a streaming system, and scale and cost-efficiency of a data lake. In contrast, Alluxio a middleware for data access - think Alluxio storage layer as fast cache.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content