This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. Analysis of such large data sets often requires powerful distributed data stores like Hadoop and heavy data processing with techniques like MapReduce.
Automating IT practices without integrated AIOps presents several challenges. This kind of automation can support key IT operations, such as infrastructure, digital processes, business processes, and big-data automation. Bigdata automation tools. The challenges of automating IT and how to combat them.
She dispelled the myth that more bigdata equals better decisions, higher profits, or more customers. Investing in data is easy but using it is really hard”. The fact is, data on its own isn’t meaningful. Tricia quoted the statistic that companies typically use 3% of their data to inform decisions.
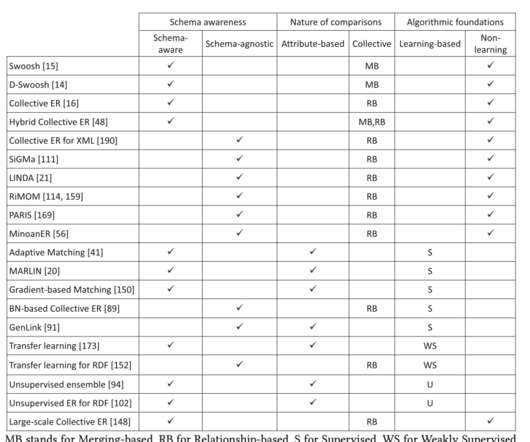
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No. More sophisticated methods may also split and merge blocks.
Data scientists and engineers collect this data from our subscribers and videos, and implement dataanalytics models to discover customer behaviour with the goal of maximizing user joy. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., I’ve been excited about the potential for approximate query processing in analytic clusters for some time, and this paper describes its use at scale in production. VLDB’19. Approximate query support.
Challenges and Considerations in Distributed Storage Deployment Although distributed storage systems offer significant advantages, they also present distinct challenges that must be addressed. These distributed storage services also play a pivotal role in bigdata and analytics operations.
Gartner defines AIOps as the combination of “bigdata and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” AIOps is often presented as a way to reduce the noise of countless alerts, but it can and should be more than that.
The other document you can specify is a customer error page that is presented to your customers when a 4XX class error occurs (e.g. Driving down the cost of Big-Dataanalytics. This enables Amazon S3 to know what document to serve if one isnt explicitly requested: for example [link]. the index.html from that subdirectory.
Unlike relational databases, NoSQL databases do not require a fixed schema, allowing for more flexible data models. This flexibility makes NoSQL databases well-suited for applications with dynamic data requirements, such as real-time analytics, content management systems, and IoT applications.
We use high-performance transactions systems, complex rendering and object caching, workflow and queuing systems, business intelligence and dataanalytics, machine learning and pattern recognition, neural networks and probabilistic decision making, and a wide variety of other techniques. Driving down the cost of Big-Dataanalytics.
Workloads from web content, bigdataanalytics, and artificial intelligence stand out as particularly well-suited for hybrid cloud infrastructure owing to their fluctuating computational needs and scalability demands. Capabilities for handling diverse data management functions are necessary.
Although there are many books on data mining in general and its applications to marketing and customer relationship management in particular [BE11, AS14, PR13 etc.], The rest of the article is organized as follows: We first introduce a simple framework that ties together a retailer’s actions, profits and data. Sale channels.
The AWS Events team is organizing a number of events where I will present together with a number of AWS customers: AWS Cloud Computing Event in Berlin on October 7 with AWS customers moviepilot , Cellular , Schnee von morgen and Plinga. AWS Solutions Architect Matt Tavis will present on " Architecting for the Cloud ". Contact Info.
Next to a presentation by me about HPC on AWS, there is a panel with Japanese HPC experts moderated by Dr Kazuyuki Shudo of Titec. I will be presenting about how CIO strategies for business continuity are changing in the light of increasing business agility. Driving down the cost of Big-Dataanalytics.
Take, for example, The Web Almanac , the golden collection of BigData combined with the collective intelligence from most of the authors listed below, brilliantly spearheaded by Google’s @rick_viscomi. This book presents 14 specific rules that will cut 25% to 50% off response time when users request a page. Still good.
Ill be using that information in presentations and some future writings on this topic. Driving down the cost of Big-Dataanalytics. If you run such a service or know of one that I should be checking out, please leave the info in the comments below. blog comments powered by Disqus. Contact Info. Werner Vogels.
IBM BigData and Analytics Hub website cited a case study, where a US insurance company was estimating 15% of their testing efforts to be just test data collection for the backend system and the frontend system. For testing purposes, usually, a mix of static and dynamic data is needed.
When I started to write this post I thought I knew who all was presenting but then I had to go back over the session lineup to see for myself. Best practices on Building a BigDataAnalytics Solution – Michael Rys. If you want to learn about Azure Data Lake, there is no one better.
Government and BigData. One particular early use case for AWS GovCloud (US) will be massive data processing and analytics. The scalability, flexibility and the elasticity of AWS makes it an ideal environment for the agencies to run their analytics. Driving down the cost of Big-Dataanalytics.
Having access to large data sets can be helpful, but only if organizations are able to leverage insights from the information. These analytics can help teams understand the stories hidden within the data and share valuable insights. “That is what exploratory analytics is for,” Schumacher explains.
Traditional rule-based models and ML techniques, such as classification and regression trees (CART) and hidden Markov models (HMM) present limitations to model the complexity of this process. Last but not least, as the quality of TTS gets better and better, we expect a natural intonation matching the semantics of synthesized texts.
Presently we know it is far from easy to forecast the future – all of us have discovered this in 2020 through major ups and downs. But in expectation of the big developments in tech trials for 2021, as we had forecast of last year for 2020 , we are looking forward to renewed hope. billion in 2019 to $40.74 The most recent 2021 trend.
Artificial Intelligence (AI) and Machine Learning (ML) AI and ML algorithms analyze real-time data to identify patterns, predict outcomes, and recommend actions. BigDataAnalytics Handling and analyzing large volumes of data in real-time is critical for effective decision-making.
This session dives into pioneering a journey as a frontrunner in using data and technology to navigate this uncharted territory to proactively identify and mitigate climate-related financial risks while unlocking the opportunities presented by the sustainability transition. Discover how Scepter, Inc.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content