This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
Efficient data processing is crucial for businesses and organizations that rely on bigdataanalytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-source data processing framework, has emerged as a game-changer in this domain.
With 99% of organizations using multicloud environments , effectively monitoring cloud operations with AI-driven analytics and automation is critical. IT operations analytics (ITOA) with artificial intelligence (AI) capabilities supports faster cloud deployment of digital products and services and trusted business insights.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
As user experiences become increasingly important to bottom-line growth, organizations are turning to behavior analytics tools to understand the user experience across their digital properties. In doing so, organizations are maximizing the strategic value of their customer data and gaining a competitive advantage.
In an era where data is the new oil, effectively utilizing data is crucial for the growth of every organization. It is not enough to store these data durably, but also to effectively query and analyze them. Without a querying capability, the data stored in S3 would not be of any benefit.
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Several pain points have made it difficult for organizations to manage their data efficiently and create actual value.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for bigdataanalytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse? How does a data lakehouse work?
Statistical analysis and mining of huge multi-terabyte data sets is a common task nowadays, especially in the areas like web analytics and Internet advertising. Analysis of such large data sets often requires powerful distributed data stores like Hadoop and heavy data processing with techniques like MapReduce.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. As our subscribers grow worldwide and Netflix enters the world of gaming , the number of batch workflows and real-time data pipelines increases rapidly.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement dataanalytics models to discover customer behaviour with the goal of maximizing user joy.
Driving down the cost of Big-Dataanalytics. The Amazon Elastic MapReduce (EMR) team announced today the ability to seamlessly use Amazon EC2 Spot Instances with their service, significantly driving down the cost of dataanalytics in the cloud. By Werner Vogels on 18 August 2011 04:00 PM. Comments ().
Part of our series on who works in Analytics at Netflix?—?and and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer on the Product Data Science and Engineering team.
Introduction With bigdata streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
In what follows, we define software automation as well as software analytics and outline their importance. What is software analytics? This involves bigdataanalytics and applying advanced AI and machine learning techniques, such as causal AI. We also discuss the role of AI for IT operations (AIOps) and more.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
This year’s conference agenda was packed full of choices, including: Keynotes : Topics included accelerating digital transformation, with Dynatrace CIO Mike Maciag, and Spatial Collapse: The Great Acceleration of Turning Data Into an Asset, with Tricia Wang from Sudden Compass. We’ve all heard it: data is one of your biggest assets.
Discover real-time query analytics and governance with DataCentral: Uber’s bigdata observability powerhouse, tackling millions of queries in petabyte-scale environments.
Device interaction for the collection of health and other operational data is yet another Python application. We are heavy users of Jupyter Notebooks and nteract to analyze operational data and prototype visualization tools that help us detect capacity regressions. We also use Python to detect sensitive data using Lanius.
For most people looking for a log management and analytics solution, Elasticsearch is the go-to choice. The same applies to InfluxDB for time series data analysis. As NetEase expands its business horizons, the logs and time series data it receives explode, and problems like surging storage costs and declining stability come.
At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight. Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the cloud network infrastructure to address the identified problems.
At Dynatrace Perform 2023 , Ben Rushlo, Business Insights leader at Dynatrace, and Navid Mehdiabadi, BCLC’s APM expert, discuss how the right business insights are crucial to making data-driven decisions and improving business outcomes. “It’s a journey in Dynatrace,” Rushlo said. “Our players just see the frontend.
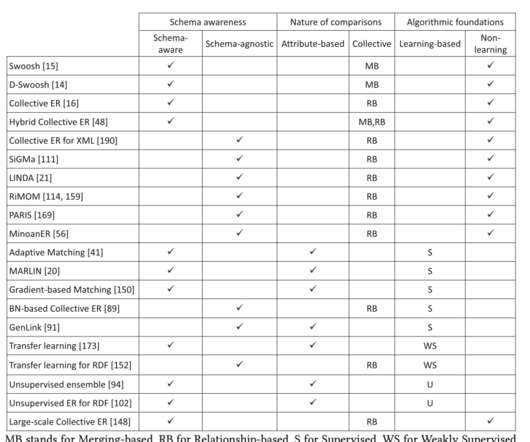
An overview of end-to-end entity resolution for bigdata , Christophides et al., It’s an important part of many modern data workflows, and an area I’ve been wrestling with in one of my own projects. ACM Computing Surveys, Dec. 2020, Article No.
The Business Insights team at Dynatrace has been working with our largest Digital Experience Monitoring customers to help them turn the Core Web Vitals data they’re collecting with Dynatrace into actionable insights they can use to optimize pages ahead of this June 2021 change in Google’s search ranking algorithm. 28-day lookbacks.
AIOps combines bigdata and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. Aggregation.
Digital transformation is yet another significant focus point for the sectors and the enterprises that are ranking top on cloud and business analytics. Nowadays, BigData tests mainly include data testing, paving the way for the Internet of Things to become the center point. Besides, AI and ML seem to reach a new level.
Our customers have frequently requested support for this first new batch of services, which cover databases, bigdata, networks, and computing. See the health of your bigdata resources at a glance. Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics.
“AIOps platforms address IT leaders’ need for operations support by combining bigdata and machine learning functionality to analyze the ever-increasing volume, variety and velocity of data generated by IT in response to digital transformation.” – Gartner Market Guide for AIOps platforms. Evolution of modern AIOps.
Scripts and procedures usually focus on a particular task, such as deploying a new microservice to a Kubernetes cluster, implementing data retention policies on archived files in the cloud, or running a vulnerability scanner over code before it’s deployed. Bigdata automation tools. Batch process automation.
Trying to manually keep up, configure, script and source data is beyond human capabilities and today everything must be automated and continuous. User Experience and Business Analytics ery user journey and maximize business KPIs. Continuous Automation.
Retail is one of the most important business domains for data science and data mining applications because of its prolific data and numerous optimization problems such as optimal prices, discounts, recommendations, and stock levels that can be solved using data analysis methods.
Complex cloud computing environments are increasingly replacing traditional data centers. In fact, Gartner estimates that 80% of enterprises will shut down their on-premises data centers by 2025. Collect raw data in virtual and nonvirtual environments from multiple feeds, normalize and structure the data, and aggregate it for alerts.
Stephanie Lane , Wenjing Zheng , Mihir Tendulkar Source credit: Netflix Within the rapid expansion of data-related roles in the last decade, the title Data Scientist has emerged as an umbrella term for myriad skills and areas of business focus. Learning through data is in Netflix’s DNA. It can be hard to know from the outside.
Log4Shell required many organizations to take devices and applications offline to prevent malicious attackers from gaining access to IT systems and sensitive data. As a result, organizations need to be vigilant in identifying and addressing vulnerabilities to protect their systems and data.
Anytime, every time or sometime you would have heard someone going around with data analysis and saying maybe this could have happened because of this, maybe users did not like the feature or maybe we were wrong all the time. Any analysis and prediction in dataanalytics across industries experience what I call maybe syndrome.
Setting up a data warehouse is the first step towards fully utilizing bigdata analysis. Still, it is one of many that need to be taken before you can generate value from the data you gather. An important step in that chain of the process is data modeling and transformation.
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., I’ve been excited about the potential for approximate query processing in analytic clusters for some time, and this paper describes its use at scale in production. VLDB’19. Approximate query support. Implementation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content