This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. This integration eliminates the need for separate data collection, transfer, configuration, storage, and analytics, streamlining operations and reducing costs.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ? What is Apache Kafka?
This is explained in detail in our blog post, Unlock log analytics: Seamless insights without writing queries. This architecture also means you are not required to determine your log data use cases beforehand or while analyzing logs within the new logs app.
One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries. However, the process for effectively scaling Elasticsearch can be nuanced, since one needs a proper understanding of the architecture behind it and of performance tradeoffs.
Analytical Insights Additionally, impression history offers insightful information for addressing a number of platform-related analytics queries. Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. All data should be also available for offline analytics in Hive/Iceberg. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low.
Cloud-based application architectures commonly leverage microservices. High latency or lack of responses. You receive an alert message from Dynatrace (your infrastructure observability hub) letting you know that the average response latency of all deployed APIs has tripled. Soaring number of active connections.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Cassandra serves as the backbone for a diverse array of use cases within Netflix, ranging from user sign-ups and storing viewing histories to supporting real-time analytics and live streaming. Data Model At its core, the KV abstraction is built around a two-level map architecture.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Data lakehouses deliver the query response with minimal latency.
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. Latency is the time that it takes a request to be served. Use SLO data to communicate with stakeholders and drive better business decisions. Reliability.
Trace your application Imagine a microservices architecture with hundreds of dependencies. Without distributed tracing, pinpointing the cause of increased latency could take hours or even days. Interact with data intuitively and easily and benefit from immediate, AI-supported insights. The same is true when it comes to log ingestion.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. Dynatrace news. As teams begin collecting and working with observability data, they are also realizing its benefits to the business, not just IT.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Customers can use response streaming to achieve the following: Improve Time to First Byte (TTFB) performance for latency-sensitive applications. Return larger payload sizes.
Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds. Sending and receiving messages from other users.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Power business analytics with Dynatrace Banks that can deploy vertically integrated risk management solutions will deliver unprecedented agility, precision, and control for risk management functions. Maximize performance for high-frequency and low-latency trading strategies. Automated issue resolution. Break down data silos.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. SRG validates the status of the resiliency SLOs for the experiment period.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns.
Netflix is known for its loosely coupled microservice architecture and with a global studio footprint, surfacing and connecting the data from microservices into a studio data catalog in real time has become more important than ever. Data Mesh leverages Iceberg tables as data warehouse sinks for downstream analytics use cases.
This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. The Dynatrace AIOps platform approach integrates data from disparate monitoring point solutions and uses deterministic AI to fully map the topology of complex, distributed architectures for real-time, actionable insights. Performance.
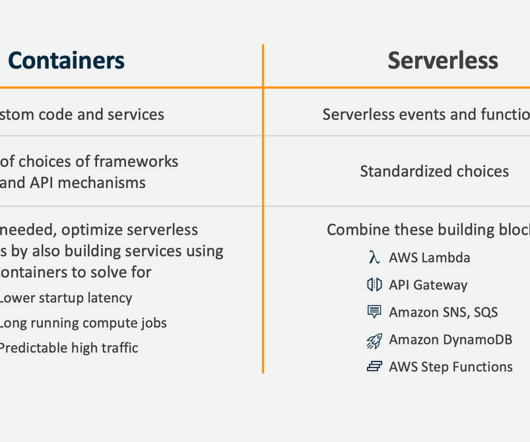
I don’t advocate “Serverless Only”, and I recommended that if you need sustained high traffic, low latency and higher efficiency, then you should re-implement your rapid prototype as a continuously running autoscaled container, as part of a larger serverless event driven architecture, which is what they did.
Azure HDInsight supports a broad range of use cases including data warehousing, machine learning, and IoT analytics. This means that you can improve performance, scale your application, and enable complex application architectures like IaaS and PaaS, on premise + cloud, or multi-cloud hybrid environments.
Organizations are depending more and more on distributed architectures to provide application services. For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Dynatrace news. This trend is prompting advances in both observability and monitoring.
Procella: unifying serving and analytical data at YouTube Chattopadhyay et al., That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Oh, and in additional to low latency, “ we require access to fresh data.” VLDB’19.
As organizations adopt microservices-based architecture , service-level objectives (SLOs) have become a vital way for teams to set specific, measurable targets that ensure users are receiving agreed-upon service levels. You can set SLOs based on individual indicators, such as batch throughput, request latency, and failures-per-second.
Already in the 2000s, service-oriented architectures (SOA) became popular, and operations teams discovered the need to understand how transactions traverse through all tiers and how these tiers contributed to the execution time and latency. Distributed computing didn’t start with the rise of microservices.
Amazon DynamoDB offers low, predictable latencies at any scale. This architectural pattern was a response to the scaling challenges that had challenged Amazon.com through its first 5 years, when direct database access was one of the major bottlenecks in scaling and operating the business. This impacts the predictability of a Domainâ??s
With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. Redis, a powerful in-memory data store, is no exception.
Building general purpose architectures has always been hard; there are often so many conflicting requirements that you cannot derive an architecture that will serve all, so we have often ended up focusing on one side of the requirements that allow you to serve that area really well.
With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. Redis®, a powerful in-memory data store, is no exception.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
The partnership between AI and cloud computing brings about transformative trends like enhanced security through intelligent threat detection, real-time analytics, personalization, and the implementation of edge computing for quicker on-site decision-making. Key among these trends is the emphasis on security and intelligent analytics.
Wondering where RabbitMQ fits into your architecture? Microservices Communication In the context of a microservices architecture that demands scalability and loose coupling among services, RabbitMQ serves as a critical component. Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios.
In this blog post, I will explain how these three new capabilities empower you to build applications with distributed systems architecture and create responsive, reliable, and high-performance applications using DynamoDB that work at any scale. DynamoDB Cross-region Replication.
The architecture usually integrates several private, public, and on-premises infrastructures. Key Components of Hybrid Cloud Infrastructure A hybrid cloud architecture usually merges a public Infrastructure-as-a-Service (IaaS) platform with private computing assets and incorporates tools to manage these combined environments.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. However, Redis, with its single-threaded architecture, may encounter bottlenecks with large numbers of concurrent connections.
Distributed Storage Architecture Distributed storage systems are designed with a core framework that includes the main system controller, a data repository for the system, and a database. Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions.
Real-Time Device Tracking with In-Memory Computing Can Fill an Important Gap in Today’s Streaming Analytics Platforms. The Limitations of Today’s Streaming Analytics. How are we managing the torrent of telemetry that flows into analytics systems from these devices? The list goes on.
Whether it’s health-tracking watches, long-haul trucks, or security sensors, extracting value from these devices requires streaming analytics that can quickly make sense of the telemetry and intelligently react to handle an emerging issue or capture a new opportunity.
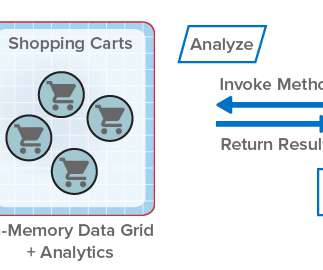
ScaleOut StateServer® Pro Adds Analytics to In-Memory Data Grids . By transparently distributing stored objects across a cluster of servers (physical or virtual), it automatically scales performance for fast-growing workloads and maintains consistently low access latency. In-Memory Data Grids for Fast-Changing Data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content