This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
Dynatrace continues to deliver on its commitment to keeping your data secure in the cloud. Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access.
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost.
Leverage AI for proactive protection: AI and contextual analytics are game changers, automating the detection, prevention, and response to threats in real time. Move beyond logs-only security: Embrace a comprehensive, end-to-end approach that integrates all data from observability and security.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. This has resulted in visibility gaps, siloed data, and negative effects on cross-team collaboration.
As a result, organizations are implementing security analytics to manage risk and improve DevSecOps efficiency. Fortunately, CISOs can use security analytics to improve visibility of complex environments and enable proactive protection. What is security analytics? Why is security analytics important? Here’s how.
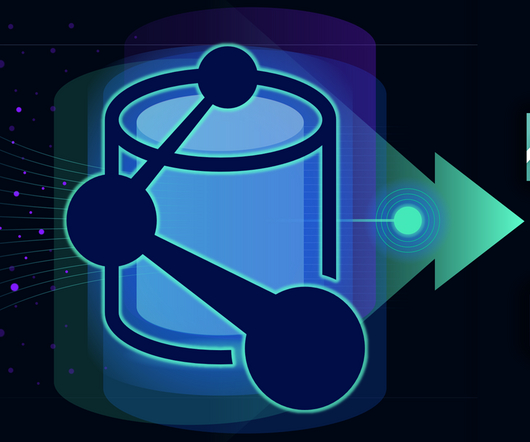
Grail – the foundation of exploratory analytics Grail can already store and process log and business events. Now we’re adding Smartscape to DQL and two new data sources to Grail: Metrics on Grail and Traces on Grail. Ensuring observability across these environments requires access to data at a massive scale.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
Existing siloed tools lead to inefficient workflows, fragmented data, and increased troubleshooting times. Rather than relying on disparate tools for each environment and team, Dynatrace integrates all data into one cohesive platform. As a result, dedicated data pipeline tools are unnecessary for preprocessing data before ingestion.
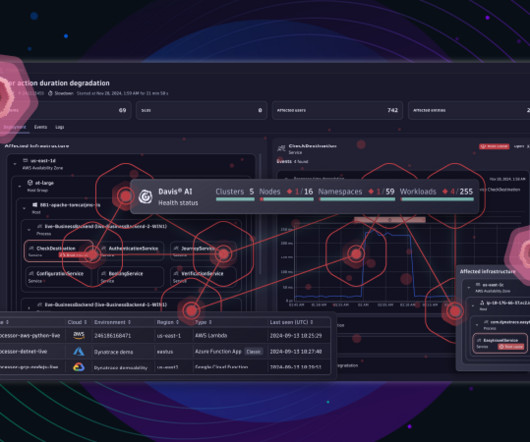
Its AI-driven exploratory analytics help organizations navigate modern software deployment complexities, quickly identify issues before they arise, shorten remediation journeys, and enable preventive operations. Dynatrace Dashboards , powered by Grail data lakehouse and Davis AI, offer precisely that.
With 99% of organizations using multicloud environments , effectively monitoring cloud operations with AI-driven analytics and automation is critical. IT operations analytics (ITOA) with artificial intelligence (AI) capabilities supports faster cloud deployment of digital products and services and trusted business insights.
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. The only way to address these challenges is through observability data — logs, metrics, and traces. Teams interact with myriad data types.
Azure observability and Azure dataanalytics are critical requirements amid the deluge of data in Azure cloud computing environments. requires Azure observability Data has become a pivotal asset in the current IT landscape, and AI has unequivocally become the linchpin for differentiation. Digital transformation 2.0
How do you get more value from petabytes of exponentially exploding, increasingly heterogeneous data? The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022.
The growing challenge in modern IT environments is the exponential increase in log telemetry data, driven by the expansion of cloud-native, geographically distributed, container- and microservice-based architectures. Organizations need a more proactive approach to log management to tame this proliferation of cloud data.
OpenTelemetry signals are often analyzed in data silos with missing context and relationships between the data and underlying topology. This leads to significant time wasted in connecting data with application workloads by manually applying labels, or by building crosslinks between the dashboards of incompatible tools.
Drowning under endless data? Having access to large data sets can be helpful, but only if organizations are able to leverage insights from the information. These analytics can help teams understand the stories hidden within the data and share valuable insights. and only they have access.” and only they have access.”
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Grail architectural basics.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Logs can include data about user inputs, system processes, and hardware states. What is log analytics? Log monitoring vs log analytics.
Following the launch of Dynatrace® Grail for Log Management and Analytics , we’re excited to announce a major update to our Business Analytics solution. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data. The need for real-time business observability.
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Several pain points have made it difficult for organizations to manage their data efficiently and create actual value.
In the rapidly evolving digital landscape, the role of data has shifted from being merely a byproduct of business to becoming its lifeblood. With businesses constantly in the race to stay ahead, the process of integrating this data becomes crucial. However, it's no longer enough to assimilate data in isolated, batch-oriented processes.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
Today’s digital businesses run on heterogeneous and highly dynamic architectures with interconnected applications and microservices deployed via Kubernetes and other cloud-native platforms. All this data is then consumed by Dynatrace Davis® AI for more precise answers, thereby driving AIOps for cloud-native environments.
They create an explosion of data that is extremely challenging to manually capture, analyze, and act on. Fragmented monitoring and analytics can’t keep up The continued reliance on fragmented monitoring tools and manual analytics strategies is a particular pain point for IT and security teams.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse?
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
The growing complexity of modern multicloud environments has created a pressing need to converge observability and security analytics. Security analytics is a discipline within IT security that focuses on proactive threat prevention using data analysis. Clair determined what log data was available to her.
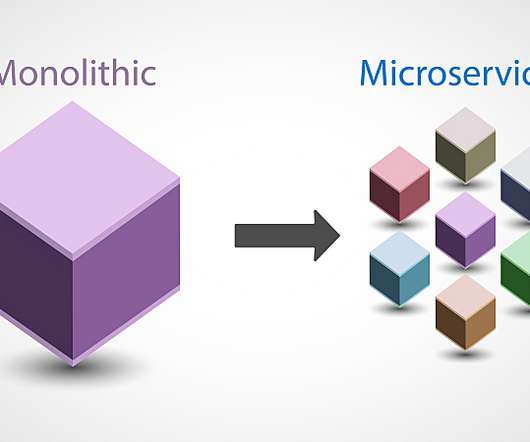
As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Traditional monolithic architectures are built around the concept of large applications that are self-contained, independent, and incorporate myriad capabilities. What is monolithic architecture?
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. They’re unleashing the power of cloud-based analytics on large data sets to unlock the insights they and the business need to make smarter decisions. All of these factors challenge DevOps maturity.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This queue ensures we are consistently capturing raw events from our global userbase.
Key takeaways from this article on modern observability for serverless architecture: As digital transformation accelerates, organizations need to innovate faster and continually deliver value to customers. Companies often turn to serverless architecture to accelerate modernization efforts while simplifying IT management.
Traditional analytics and AI systems rely on statistical models to correlate events with possible causes. While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. But to be successful, data quality is critical.
It supports multi-line logs, handles log rotation, and even includes mechanisms to check for data corruption. When using Dynatrace, in addition to automatic log collection, you gain full infrastructure context and access to powerful, advanced log analytics tools such as the Logs, Notebooks, and Dashboards apps.
Organizations continue to turn to multicloud architecture to deliver better, more secure software faster. But IT teams need to embrace IT automation and new data storage models to benefit from modern clouds. As they enlist cloud models, organizations now confront increasing complexity and a data explosion.
Considering the latest State of Observability 2024 report, it’s evident that multicloud environments not only come with an explosion of data beyond humans’ ability to manage it. It’s increasingly difficult to ingest, manage, store, and sort through this amount of data. You can find the list of use cases here.
This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
App architecture. First, let’s explore the architecture of these apps: BizOpsConfigurator. The app pulls all of the data from GitHub and Dynatrace APIs. With that simple copy-paste, I now have all the performance, errors, and user experience data for BizOpsConfigurator! Dashboard Powerups. How can I segment them?
Authors: Ruoxi Sun (Tech Lead of Analytical Computing Team at PingCAP). TiDB is a Hybrid Transaction/Analytical Processing (HTAP) database that can efficiently process analytical queries. Fei Xu (Software Engineer at PingCAP).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content