This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Triage and diagnosis become a long process of hunting for clues. With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like: Automated Kubernetes root cause analysis. Incidents are harder to solve. New to Dynatrace?
DevOps teams don’t need just more noise—they need smarter alerting that is automatic, accurate, and actionable with precise root cause analysis. Root cause analysis is often hampered by a lack of timely information, the involvement of multiple tools, or conflicting sources of truth. What you need to know for root cause analysis.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
A business process is a collection of related, usually structured tasks or steps, performed in sequence, that achieve a defined business goal. Tasks may be manual or automatic, and many business processes will include a combination of both. Make better decisions by providing managers with real-time data about the business.
Apache Kafka is a battle-tested distributed stream-processing platform popular in the financial industry to handle mission-critical transactional workloads. Processed market data and orders may then be saved to a time series database for further analysis.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. Traditional log analysis evaluates logs and enables organizations to mitigate myriad risks and meet compliance regulations. Ingesting, processing, retaining, and querying logs.
Luckily, Dynatrace provides in-depth memory allocation monitoring, which allows fine-grained allocation analysis and can even point to the root cause of a problem. While memory allocation analysis can show wasteful or inefficient code, it can also reveal different problems, one of which we’ll examine in this blog post.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. The post Automated Change Impact Analysis with Site Reliability Guardian appeared first on Dynatrace news.
AI data analysis can help development teams release software faster and at higher quality. AI observability and data observability The importance of effective AI data analysis to organizational success places a burden on leaders to better ensure that the data on which algorithms are based is accurate, timely, and unbiased.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
Still, it is critical to collect, store, and make easily accessible these massive amounts of log data for analysis. Current analytics tools are fragmented and lack context for meaningful analysis. The post Any analysis, any time: Dynatrace Log Management and Analytics powered by Grail appeared first on Dynatrace news.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
.” With this design philosophy, Dynatrace makes sure no stakeholders are left behind in the monitoring process. To learn more about the executive-level health views, check out the full session, “ Instantly understand and improve application health with new AI-powered analysis views.”
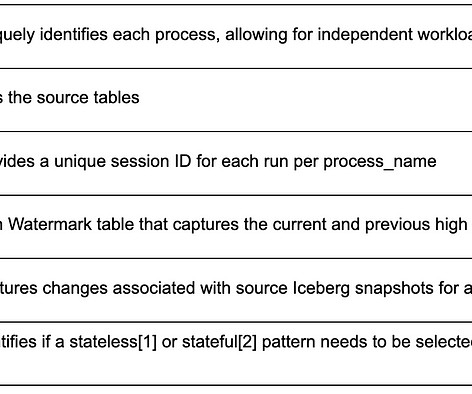
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
Does that mean that reactive and exploratory data analysis, often done manually and with the help of dashboards, are dead? Of course, Dynatrace can effortlessly integrate such metrics from Prometheus exporters and make them available for charting, alerting, and analysis.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Commitment to privacy.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. Aggregation. Enhanced automation.
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. The team decides to dig into the “prod” namespace to perform exploratory analysis of their critical production workloads. s – 7.24 s) to investigate further.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. Davis AI root cause analysis is used to pinpoint the problem, entity, and root cause.
Dynatrace Grail™ and Davis ® AI act as the foundation, eliminating the need for manual log correlation or analysis while enabling you to take proactive action. This shortens root cause analysis dramatically, as explained in our recent blog post Full Kubernetes logging in context from Fluent Bit to Dynatrace.
Easy access to exception details in the context of a full trace for exception analysis Expanded log insights for your applications Only Dynatrace enables true and unified observability across all ingested logs, including infrastructure components and hyperscalers providing backend services or cloud-native frontend applications.
The more data ingestion channels you provide to the Dynatrace Davis® AI engine, the more comprehensive Dynatrace automated root cause analysis becomes. A $20 billion Germany-based financial services company told us they found the process of pushing Syslog messages to Dynatrace natively to be seamless.
Dynatrace addresses this issue by providing unified ingest and analysis of container vulnerability findings across cloud and container registries. Key Steps in the Integration Process Container image scanning AWS ECR scans container images for vulnerabilities. Thus, getting a holistic view of security risks is challenging.
Dynatrace automatic root-cause analysis and intelligent automation enables organizations to accelerate their cloud journey, reduce complexity, and achieve greater agility in their digital transformation efforts. This integration augments our existing support for OpenTelemetry to provide customers with more flexibility.
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. After replaying the requests, this dedicated service also records the responses from the production and replay paths for offline analysis.
Data proliferation—as well as a growing need for data analysis—has accelerated. Converging observability, security, and business data with Grail – resource center Discover everything you need to know about Grail, the Dynatrace causational data lakehouse with a massively parallel processing analytics engine. What is a data lakehouse?
Whenever a change is detected, Dynatrace automatically generates a Deployment change event for the corresponding process and the host on which the process runs. Predictive traffic analysis Deploying OneAgent within the staging environment facilitates the availability of telemetry data for analysis by Davis AI.
The app scans all incoming logs for various patterns and uses DQL (Dynatrace Query Language) to collect context like hosts, other processes, and traces for each potential problem. Figure 3: Funnel analysis implemented by selecting a custom user journey. Hyperscaler security events are ingested into Grail as BizEvents.
5, including: Configuration Change Control and CM-4 – Impact Analysis now requires privacy impact analysis for configuration changes. They help organizations understand risks, improve processes, and boost security readiness. The result is a more effective security posture. 5 on the FedRAMP website. Dynatrace for U.S.
Financial data engineering in SAS involves the management, processing, and analysis of financial data using the various tools and techniques provided by the SAS software suite. Here are some key aspects of financial data engineering in SAS: 1.
But when navigating this process, one of the biggest challenges facing enterprises is having too many tools. The report offers a better understanding of the observability landscape.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Traces are used for performance analysis, latency optimization, and root cause analysis. To understand what this means, let’s first look at two of the core concepts: observability and telemetry.
CloudOps includes processes such as incident management and event management. AIOps reduces the time needed to resolve an incident by automating key steps in the incident response process. The four stages of data processing. There are four stages of data processing: Collect raw data. Aggregate it for alerts.
Information related to user experience, transaction parameters, and business process parameters has been an unretrieved treasure, now accessible through new and unique AI-powered contextual analytics in Dynatrace. Lack of visibility into business processes to improve, optimize, and remediate issues and systems harms business success.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
“There are too many manual processes,” said Michael Winkler, senior principal in product management at Dynatrace, during a Perform 2023 breakout session. But DevOps automation isn’t just about reducing manual effort and increasing process speed; it’s also about gaining insight with answer-driven operations.
It uses fault-tree analysis to identify the component events that cause outcomes at a higher level. Causal AI applies a deterministic approach to anomaly detection and root-cause analysis that yields precise, continuous, and actionable insights in real time. That’s where causal AI can help. How can organizations improve data quality?
Modern observability and security require comprehensive access to your hosts, processes, services, and applications to monitor system performance, conduct live debugging, and ensure application security protection. It automatically discovers and monitors each host’s applications, services, processes, and infrastructure components.
With the latest advances from Dynatrace, this process is instantaneous. Moreover, it is fast, powered by its massively parallel processing data lakehouse. As a result, organizations can reduce complexity, effort, and processing time to run powerful business analytics on exabytes of data in real time.
As batch jobs run without user interactions, failure or delays in processing them can result in disruptions to critical operations, missed deadlines, and an accumulation of unprocessed tasks, significantly impacting overall system efficiency and business outcomes. Individual batch job status with processing times and status Figure 4.
Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. asc | fields `Host`, `Recently Restarted?
In the last blog post of this series, we delved into how Dynatrace, functioning as a deploy-stage orchestrator, solves the challenges confronted by Site Reliability Engineers (SREs) during the early of automating CI/CD processes. This slow feedback and time spent rerunning tests can hinder the overall software deployment process.
In this post, let’s explore a key performance metric studied during garbage collection analysis: "GC throughput." During that pause period, no customer transactions will be processed. We’ll understand what it means, its significance in Java applications, and how it impacts overall performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content