This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. Because its constantly evolving, staying up to date with the latest in OpenTelemetry is no small feat.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
Dynatrace automatic root-cause analysis and intelligent automation enables organizations to accelerate their cloud journey, reduce complexity, and achieve greater agility in their digital transformation efforts. This integration augments our existing support for OpenTelemetry to provide customers with more flexibility.
BT, the UK’s largest mobile and fixed broadband provider, faced this challenge when managing multiple monitoring tools across different teams. By automating root-cause analysis, TD Bank reduced incidents, speeding up resolution times and maintaining system reliability. The result?
Combined with Microsoft Sentinel, Dynatrace automation and AI capabilities provide SecOps teams with deeper intelligence to detect attacks, vulnerabilities, audit logs, and problem events based on metrics, logs, and traces it collects from monitored environments. Runtime vulnerability analysis. Runtime application protection.
Based on your requirements, you can select one of three approaches for Davis AI anomaly detection directly from any time series chart: Auto-Adaptive Threshold: This dynamic, machine-learning-driven approach automatically adjusts reference thresholds based on a rolling seven-day analysis, continuously adapting to changes in metric behavior over time.
In response, many organizations are adopting a FinOps strategy. Empowering teams to manage their FinOps practices, however, requires teams to have access to reliable multicloud monitoring and analysis data. Dynatrace looks inside the machine and immediately tells you what’s running on it.
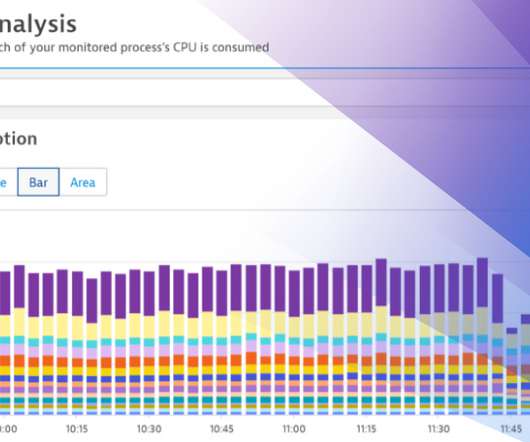
We’re happy to announce that with Dynatrace version 1.198, we’ve dramatically improved CPU analysis, allowing you to easily understand CPU consumption over time, in the context of your workloads. All deeper analysis actions are performed across the entire timeframe. Easily identify and analyze your most impacting workloads.
One Dynatrace customer, TD Bank, placed Dynatrace at the center of its AIOps strategy to deliver seamless user experiences. AI for IT operations (AIOps) uses AI for event correlation, anomaly detection, and root-cause analysis to automate IT processes.
This article includes key takeaways on AIOps strategy: Manual, error-prone approaches have made it nearly impossible for organizations to keep pace with the complexity of modern, multicloud environments. Traditional cloud monitoring tools haven’t solved the challenge with their bolt-on correlation and machine-learning approaches.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels. The time taken to complete the page load.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. In addition, their logs-heavy approach to analysis made scaling processes complex and costly. To achieve it, Spier and his team turned to Dynatrace.
In an era dominated by automated, code-driven software deployments through Kubernetes and cloud services, human operators simply can’t keep up without intelligent observability and root cause analysis tools. The chart feature allows for quick analysis of problem peaks at specific times.
Answering this question requires careful management of release risk and analysis of lots of data related to each release version of your software. Answers provided by built-in Dynatrace Release Analysis. How Release Analysis works. Dynatrace uses built-in version detection strategies. “To release or not to release?”
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. They need ways to monitor infrastructure, even if it’s no longer on premises. Traditional monitoring tools cannot monitor legacy and cloud-native applications on the same platform. Dynatrace news.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
A robust application security strategy is vital to ensuring the safety of your organization’s data and applications. Monitoring and alerting: Continuously monitor external assets for signs of compromise and alerting teams to potential threats. This is why exposure management is a key cornerstone of modern application security.
While many organizations have embraced cloud observability to better manage their cloud environments, they may still struggle with the volume of entities that observability platforms monitor. The key to getting answers from log monitoring at scale begins with relevant log ingestion at scale. Log ingestion strategy no.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Stage 2: Service monitoring.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
Every company has its own strategy as to which technologies to use. Since Micrometer conforms data to the right form and then sends it off for analysis, companies need an easy way to analyze massive amounts of data , get actionable insights in real time, and interpret the resulting alerts and responses. Dynatrace news. of Micrometer.
As the world becomes increasingly interconnected with the proliferation of IoT devices and a surge in applications, digital transactions, and data creation, mobile monitoring — monitoring mobile applications — grows ever more critical.
AI data analysis can help development teams release software faster and at higher quality. AI observability and data observability The importance of effective AI data analysis to organizational success places a burden on leaders to better ensure that the data on which algorithms are based is accurate, timely, and unbiased.
Digital transformation strategies are fundamentally changing how organizations operate and deliver value to customers. A comprehensive digital transformation strategy can help organizations better understand the market, reach customers more effectively, and respond to changing demand more quickly. Competitive advantage.
Option 1: Log Processing Log processing offers a straightforward solution for monitoring and analyzing title launches. This allows us to focus on data analysis and problem-solving rather than managing complex systemchanges. As we thought more about this problem and possible solutions, two clear optionsemerged.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis, a powerful in-memory data store, is no exception.
Mobile app monitoring and mobile analytics make this possible. With the right monitoring solution, you can get ahead of problems to help increase overall app adoption and user satisfaction. What is mobile app monitoring? Mobile app monitoring is the process of collecting and analyzing data about application performance.
Dynatrace HTTP monitors help you to ensure that your APIs are available and performing well from all locations around the world in compliance with your SLAs. HTTP monitors are the perfect tool for proactively monitoring API endpoints, API transactions (for example, CRUD scenarios), health-check endpoints, and your mobile back-end services.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Dynatrace helps enhance your AI strategy with practical, actionable knowledge to maximize benefits while managing costs effectively.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. That’s another example where monitoring is of tremendous help as it provides the current resource consumption picture and help to continuously fine tune those settings. . Monitoring in the Kubernetes world .
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. Network performance monitoring core to observability For these reasons, network activity becomes a key data source in IT observability. But this approach merely perpetuates data silos and cloud complexity.
This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more. What is infrastructure monitoring? . What to look for when selecting an infrastructure monitoring solution?
Dynatrace is proudly committed to providing users with an integrated observability platform that provides true end-to-end monitoring and analysis. However, when applications span monitoring environments, end-to-end tracing becomes much more difficult because each environment only sees a piece of the complete transaction.
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Redis®, a powerful in-memory data store, is no exception.
The 2024 State of AI Report highlights this trend, with 89% of technology leaders anticipating that AI will significantly enhance incident response by learning to automate and optimize various tasks, such as performance monitoring and workload scheduling. These algorithms are not limited to monitoring IT environments.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. Synthetic monitor metrics. Dynatrace news.
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. We can experiment with different content placements or promotional strategies to boost visibility and engagement.
Data proliferation—as well as a growing need for data analysis—has accelerated. They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. That’s where a data lakehouse can help.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. Once products and services are live, IT teams must continuously monitor and manage them. What is AIOps, and how does it work? Aggregation. Reduced IT spend.
Use Cases and Requirements At Netflix, our counting use cases include tracking millions of user interactions, monitoring how often specific features or experiences are shown to users, and counting multiple facets of data during A/B test experiments , among others. Additionally, we employ a bucketing strategy to prevent wide partitions.
Customer experience analytics is the systematic collection, integration, and analysis of data related to customer interactions and behavior with an organization and/or its products and services. Defining clear objectives will guide your analysis efforts and help maintain focus on extracting the most relevant and actionable information.
In order to accomplish this, one of the key strategies many organizations utilize is an open source Kubernetes environment, which helps build, deliver, and scale containerized Cloud Native applications. Don’t underestimate complexity. Kubernetes is not monolithic. Stand-alone observability won’t cut it.
By implementing these strategies, organizations can minimize the impact of potential failures and ensure a smoother transition for users. Dynatrace can monitor production environments for performance degradations and outage events that may cause customers to lose access.
Unlike traditional monitoring, which focuses on watching individual metrics for system health indicators with no overall context, observability goes deeper , analyzing telemetry data for a comprehensive view of the system’s internal state in context of the wider system. There are three main types of telemetry data: Metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content