This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like: Automated Kubernetes root cause analysis. Automated Kubernetes root cause analysis: a paradigm shift. Davis AI targeting Kubernetes orchestration.
In an era dominated by automated, code-driven software deployments through Kubernetes and cloud services, human operators simply can’t keep up without intelligent observability and root cause analysis tools. The chart feature allows for quick analysis of problem peaks at specific times.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels. The time taken to complete the page load.
As teams moved their deployment infrastructure to containers, monitoring and logging methods changed a lot. That’s why it makes sense to collect logs from every node and send them to some sort of central location outside the Kubernetes cluster for persistence and later analysis.
Even in higher education, IT staff depend on key visibility into their complex ecosystems of applications and infrastructure to monitor and manage application health. They also explored how Dynatrace is advancing visibility and health monitoring with new AI-driven health view features. ” One major gap was application health.
This allows you to build customized visualizations with Dashboards or perform in-depth analysis with Notebooks. Traditional insight into HTTP monitor execution details For nearly two thousand Dynatrace customers, Dynatrace Synthetic HTTP monitors provide insights into the health of monitored endpoints worldwide and around the clock.
Luckily, Dynatrace provides in-depth memory allocation monitoring, which allows fine-grained allocation analysis and can even point to the root cause of a problem. While memory allocation analysis can show wasteful or inefficient code, it can also reveal different problems, one of which we’ll examine in this blog post.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. Traditional log analysis evaluates logs and enables organizations to mitigate myriad risks and meet compliance regulations. Grail enables 100% precision insights into all stored data.
With the pace of digital transformation continuing to accelerate, organizations are realizing the growing imperative to have a robust application security monitoring process in place. What are the goals of continuous application security monitoring and why is it important?
Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. Extending this visibility into your CI/CD pipelines offers even greater value.
Still, it is critical to collect, store, and make easily accessible these massive amounts of log data for analysis. Current analytics tools are fragmented and lack context for meaningful analysis. Find time- or entity-bound anomalies or patterns in your infrastructure monitoring logs.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
Moreover, the number of services in an enterprise’s portfolio makes it impractical to manually configure and adapt alerting for the tens of thousands of service endpoints teams need to monitor. A unified platform approach also makes OpenTelemetry data available to more teams across the organization for more diversified analysis.
AI data analysis can help development teams release software faster and at higher quality. AI observability and data observability The importance of effective AI data analysis to organizational success places a burden on leaders to better ensure that the data on which algorithms are based is accurate, timely, and unbiased.
The urgency of monitoring these batch jobs can’t be overstated. Monitor batch jobs Monitoring is critical for batch jobs because it ensures that essential tasks, such as data processing and system maintenance, are completed on time and without errors. Individual batch job status with processing times and status Figure 4.
Fortunately, the Spring Boot framework offers a powerful observability stack that streamlines real-time monitoring and performance analysis. Diagnosing issues within complex microservice architectures can quickly become a time-consuming and daunting task.
Monitoring is a small aspect of our operational needs; configuring, monitoring, and checking the configuration of tools such as Fluentd and Fluentbit can be a bit frustrating, particularly if we want to validate more advanced configuration that does more than simply lift log files and dump the content into a solution such as OpenSearch.
The entire topology is built on Dynatrace based on the components it finds configured on your IBM i system, all acting cohesively to accelerate root cause and impact analysis. It’s all monitored remotely ! It’s crucial to monitor the performance of these jobs, including their CPU usage, number of instances, and status.
Does that mean that reactive and exploratory data analysis, often done manually and with the help of dashboards, are dead? Of course, Dynatrace can effortlessly integrate such metrics from Prometheus exporters and make them available for charting, alerting, and analysis. So you can stop configuring and start analyzing!
Monitoring business processes is one thing organizations can do to help improve the key business processes that enable them to provide great customer experiences. Business process monitoring refers to continuously tracking and analyzing key performance indicators (KPIs) from relevant process milestones.
As the world becomes increasingly interconnected with the proliferation of IoT devices and a surge in applications, digital transactions, and data creation, mobile monitoring — monitoring mobile applications — grows ever more critical.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. New detailed flow views enhance process analysis.
An hourly rate for Infrastructure Monitoring The Dynatrace Platform Subscription (DPS) offers a flat rate for Infrastructure Monitoring , providing observability for cloud platforms, containers, networks, and data center technologies with no limits on host memory and with AIOps included.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. The post Container monitoring for VA Platform One helps VA achieve workload performance appeared first on Dynatrace news.
DIY mobile app monitoring breeds complexity. In this case, mobile development teams often resort to costly do-it-yourself approaches where they attempt to put together different types of tooling to try to manage and monitor the mobile apps. An automated, all-in-one approach to mobile app monitoring.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. Network performance monitoring core to observability For these reasons, network activity becomes a key data source in IT observability. But this approach merely perpetuates data silos and cloud complexity.
In the recently published Gartner® “ Critic al Capabilities for Application Performance Monitoring and Observability,” Dynatrace scored highest for the IT Operations Use Case (4.15/5) This is accomplished by using service monitoring and anomaly detection for early-warning notifications of performance issues.” 5) in the Gartner report.
Dynatrace is proudly committed to providing users with an integrated observability platform that provides true end-to-end monitoring and analysis. However, when applications span monitoring environments, end-to-end tracing becomes much more difficult because each environment only sees a piece of the complete transaction.
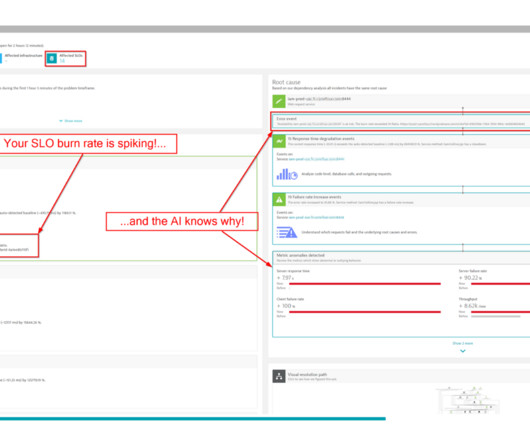
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. Without implementing robust SLO monitoring, anomaly detection, and alerting on SLOs, teams can miss issues that breach defined quality targets. What is SLO monitoring?
Dynatrace is proud to provide deep monitoring support for Azure Linux as a container host operating system (OS) platform for Azure Kubernetes Services (AKS) to enable customers to operate efficiently and innovate faster. Why monitor Azure Linux container host for AKS? How Can Dynatrace Monitor Azure Linux container host for AKS?
Dynatrace OneAgent ® discovers, observes, and protects access to OpenAI automatically, with no manual configuration, revealing the full context of used technologies, service interaction topology, security-vulnerability analysis, and the observability of all metrics, traces, logs, and business events in real time.
In the 2023 Magic Quadrant for Application Performance Monitoring (APM) and Observability, Gartner has named Dynatrace a Leader and positioned it highest for Ability to Execute and furthest for Completeness of Vision. Gartner ranked Dynatrace No. 1 for Security Operations Use Case (4.46/5) 5), DevOps/AppDev (4.08/5), 5) Use Cases.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. The Collector is expected to be ready for prime time in 2025, reaching the v1.0
According to Dynatrace research , on average, companies have 10 different monitoring tools. For example, suppose a company has standardized on a suite of disparate tools to monitor its infrastructure and apps. The report offers a better understanding of the observability landscape.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. Once products and services are live, IT teams must continuously monitor and manage them. What is AIOps, and how does it work? Aggregation. Reduced IT spend.
Dynatrace also named a Gartner Customers’ Choice Customers also named Dynatrace a Customers’ Choice in the latest Gartner® Peer Insights™ Voice of the Customer: Application Performance Monitoring report, from November 2022. In these two reports, Dynatrace is the only provider to be recognized as a Leader and as a Customers’ Choice.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
Dynatrace integrates with Tenable to provide a single pane of glass for security findings across various environments and products, allowing unified analysis, prioritization, and orchestration of findings. Monitor and detect suspicious user activity: Analyze and detect suspicious user activity within the Tenable platform.
Dynatrace automatic root-cause analysis and intelligent automation enables organizations to accelerate their cloud journey, reduce complexity, and achieve greater agility in their digital transformation efforts. This integration augments our existing support for OpenTelemetry to provide customers with more flexibility.
Automatic data capture and display: More data, including span attributes, is available for out-of-the-box analysis, with no additional configuration necessary. The team decides to dig into the “prod” namespace to perform exploratory analysis of their critical production workloads. s – 7.24 s) to investigate further.
Unlike traditional monitoring, which focuses on watching individual metrics for system health indicators with no overall context, observability goes deeper , analyzing telemetry data for a comprehensive view of the system’s internal state in context of the wider system. There are three main types of telemetry data: Metrics.
Modern observability and security require comprehensive access to your hosts, processes, services, and applications to monitor system performance, conduct live debugging, and ensure application security protection. Dynatrace OneAgent: Quick overview Dynatrace OneAgent is a unified monitoring solution deployed across your IT environment.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content