This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article takes a plunge into the comparative analysis of these two cult technologies, highlights the critical performance metrics concerning scalability considerations, and, through real-world use cases, gives you the clarity to confidently make an informed decision. However, the question arises of choosing the best one.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. The post Automated Change Impact Analysis with Site Reliability Guardian appeared first on Dynatrace news.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. This enables deep explorative analysis.
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. It provides a good read on the availability and latency ranges under different production conditions.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
Establish realistic SLO targets based on statistical and probabilistic analysis. This process includes benchmarking realistic SLO targets based on statistical and probabilistic analysis from Dynatrace. Latency is the time that it takes a request to be served. Implement a centralized approach to instrumenting and measuring SLOs.
Traces are used for performance analysis, latency optimization, and root cause analysis. It integrates with existing observability tools, enhancing data collection and analysis while providing standardized data formats for deeper insights and improved interoperability. Integration with existing tools. Contextualize data.
Introduction. When 54 percent of the internet traffic share is accounted for by Mobile , it's certainly nontrivial to acknowledge how your app can make a difference to that of the competitor!
Traditional performance analysis tools such as perf can introduce significant overhead, risking further performance degradation. Continuous instrumentation is critical to catching such matters as they emerge, and eBPF, with its hooks into the Linux scheduler with minimal overhead, enabled us to monitor run queue latency efficiently.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. In the screenshot below, a chaos engineering scenario introduced latency and resource stress on the “easytrade” demo application.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. With request tracing and additional data from logs, events, metadata, and analysis, Edgar is able to show the flow of a request through our distributed system?
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. Now that we’ve compared throughput performance, let’s take a look at ScaleGrid vs. DigitalOcean latency for MySQL. Read-Intensive Latency Benchmark. Balanced Workload Latency Benchmark.
With the growing complexity of application architectures which can rely on tens of thousands of microservices, end-2-end observability is a requirement to optimize application performance and to deliver intelligent root-cause analysis. The need for a simplified approach to capture telemetry.
One of the crucial success factors for delivering cost-efficient and high-quality AI-agent services, following the approach described above, is to closely observe their cost, latency, and reliability. With these latency, reliability, and cost measurements in place, your operations team can now define their own OpenAI dashboards and SLOs.
Without distributed tracing, pinpointing the cause of increased latency could take hours or even days. Interact with data intuitively and easily and benefit from immediate, AI-supported insights. Trace your application Imagine a microservices architecture with hundreds of dependencies.
Good visualizations are not just static, unintelligent data presentations; they enable interaction and ideally serve as a starting point for subsequent analysis. The Dynatrace Notebooks and Dashboards apps are the perfect starting point for visualizing and understanding your data for monitoring or in-depth analysis.
In order to gain insight into these problems, we gather a range of metrics and logs to monitor the utilization of system resources such as CPU, memory, and application-specific latencies. It is worth noting that this data collection process does not impact the performance of the application.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. This enables deep explorative analysis.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. This enables deep explorative analysis.
Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency. Spark Structured Streaming can also provide consistent fault recovery for applications where latency is not a critical requirement.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
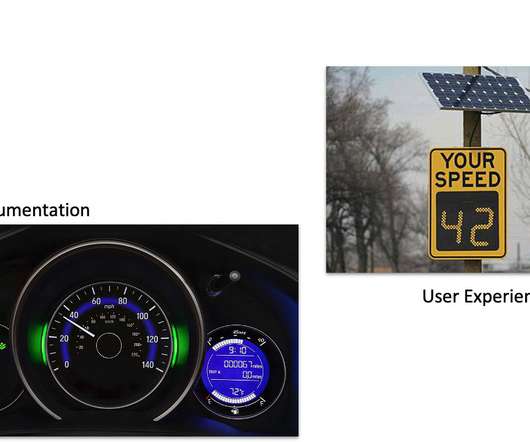
These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience. Below is a sample SRG dashboard for these signals: LatencyLatency refers to the amount of time that data takes to transfer from one point to another within a system.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems. More than one in seven outages cost more than $1 million.
Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. With a single source of truth for root-cause analysis, IT and DevOps teams can quickly get on the same page about what needs to be done and who’s responsible for doing it. Watch webinar now!
Dynatrace Grail™ and Davis ® AI act as the foundation, eliminating the need for manual log correlation or analysis while enabling you to take proactive action. This shortens root cause analysis dramatically, as explained in our recent blog post Full Kubernetes logging in context from Fluent Bit to Dynatrace.
In addition to the built-in views, Dynatrace provides data analysis that enhances your ability to query and chart metrics. With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces.
That’s because it does not require any pre-prepared schemas, and access to cold/hot storage is fully automatic and with zero latency. Automated root-cause analysis and real-time risk analysis are only two examples that help executives get closer to the vision of self-healing operations and security.
By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical. Load time and network latency metrics. Minimizing the number of network requests that your app makes can improve performance by reducing latency and improving load times.
The network latency between cluster nodes should be around 10 ms or less. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions. A similar analysis can be performed on your GRO.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. SRG validates the status of the resiliency SLOs for the experiment period.
Before you commit to leveraging AWS services, architect your solution and perform a cost analysis to make sure you can gain the most benefit. AWS continues to improve how it handles latency issues. Trying to discern a problem’s root cause through manual log analysis in this scenario is daunting.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. ScaleGrid also maintains 53% lower latency on average throughout the entire MySQL AWS performance tests.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Customers can use response streaming to achieve the following: Improve Time to First Byte (TTFB) performance for latency-sensitive applications. Return larger payload sizes.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
As such, the observability platform used to monitor Hyper-V should ideally fulfill requirements for holistic visibility, correlation and causation analysis, AI-powered analytics, scalability, and security. Dynatrace is a platform that satisfies all these criteria. Learn more about the pillars of modern observability in this e-book.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Common business analytics incur too much latency. The real-time data in context with AI-driven analysis from Dynatrace provides executives with incomparable value and customer satisfaction to improve their business processes. There can even be days of reporting intervals, which hinders real-time business insights.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. For example: All subfolders of the /opt directory are mounted as local, low latency, high-throughput drives, with relatively low storage capacity. Customizable location of large runtime files.
The other sections on that page (such as Disk analysis) provide further information and charts on topics such as available disk space, latency, dropped network packets, refused connections, and more. Performance analysis covers the technical aspects of the service, such as error rates, geo-locations, XHR actions, and user-bot ratio.
In the Dynatrace web UI, you can track your AI model in real time, examine its model attributes, and assess the reliability and latency of each specific LangChain task, as demonstrated below. OpenLLMetry provides an open source SDK for LLM observability, seamlessly integrating with Dynatrace for in-depth analysis.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content