This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
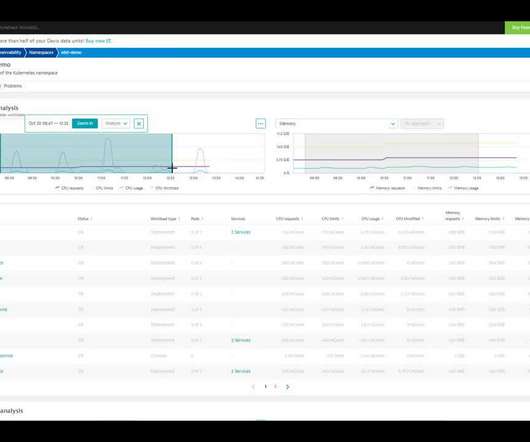
Just one click to your preventive analysis. Dynatrace now goes a step further and makes it possible for SREs and DevOps to perform proactive exploratory analysis of observability signals with intelligent answers. With Davis exploratory analysis we can now automatically analyze thousands of signals before incidences even arise.
Progressive rollouts, rollbacks, storage orchestration, bin packing, self-healing, cost efficiency, and access to the Cloud Native Computing Foundation (CNCF) ecosystem carry heavy observability challenges. Automated Kubernetes root cause analysis: a paradigm shift. Incidents are harder to solve.
Data proliferation—as well as a growing need for data analysis—has accelerated. They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. That’s where a data lakehouse can help.
In an era dominated by automated, code-driven software deployments through Kubernetes and cloud services, human operators simply can’t keep up without intelligent observability and root cause analysis tools. The chart feature allows for quick analysis of problem peaks at specific times.
Managing logs efficiently is extremely important for organizations, but dealing with large volumes of data makes it challenging to detect anomalies and unusual patterns or predict potential issues before they become critical. It offers a faster, more insightful, and automated log data analysis.
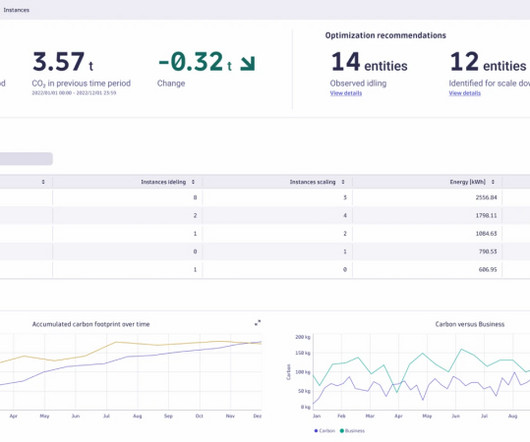
This growth was spurred by mobile ecosystems with Android and iOS operating systems, where ARM has a unique advantage in energy efficiency while offering high performance. Energy efficiency and carbon footprint outshine x86 architectures The first clear benefit of ARM in the enterprise IT landscape is energy efficiency.
DevOps teams don’t need just more noise—they need smarter alerting that is automatic, accurate, and actionable with precise root cause analysis. Root cause analysis is often hampered by a lack of timely information, the involvement of multiple tools, or conflicting sources of truth. What you need to know for root cause analysis.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. Traditional log analysis evaluates logs and enables organizations to mitigate myriad risks and meet compliance regulations. But they struggle to store unstructured data.
AI data analysis can help development teams release software faster and at higher quality. AI-enabled chatbots can help service teams triage customer issues more efficiently. A key theme at Dynatrace Perform 2024 is the need for AI observability and AI data analysis to minimize the potential for skyrocketing AI costs.
Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. Contact Sales The post Efficient SLO event integration powers successful AIOps appeared first on Dynatrace news. Interested in learning more?
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. Still, it is critical to collect, store, and make easily accessible these massive amounts of log data for analysis. This approach is cumbersome and challenging to operate efficiently at scale.
This leads to a more efficient and streamlined experience for users. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams. Dynatrace is a platform that satisfies all these criteria.
Does that mean that reactive and exploratory data analysis, often done manually and with the help of dashboards, are dead? And so, getting simple visualization use cases done efficiently becomes far from the norm. The key lies in finding the best combination of these two worlds to yield the best insights and results.
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. Dynatrace automatic root-cause analysis and intelligent automation enables organizations to accelerate their cloud journey, reduce complexity, and achieve greater agility in their digital transformation efforts.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. However, AIOps makes it possible to automate key tasks, such as error detection, alert analysis, and event reporting. For example: Greater IT staff efficiency.
Part of the problem is technologies like cloud computing, microservices, and containerization have added layers of complexity into the mix, making it significantly more challenging to monitor and secure applications efficiently. With AIOps, it is possible to detect anomalies automatically with root-cause analysis and remediation support.
It stores the metrics in a time-series database and provides the powerful PromQL query language for efficientanalysis and data visualization. Despite its powerful capabilities, there are several key considerations that determine the observability efficiency of a Kubernetes cluster through Prometheus.
Second, it enables efficient and effective correlation and comparison of data between various sources. Receiving data from multiple sources, cleaning it up, and sending it to the desired backend systems reliably and efficiently is no small feat. First, it allows human operators to correctly interpret the data they’re seeing.
In order to ship new updates of your app with confidence, you should efficiently analyze app performance during development to identify issues before they reach the end-users. This post will discuss what the best approach is to using emulators versus real devices for mobile performance analysis.
This example is a good starting point for exploratory analysis with context-aware Dynatrace Davis insights. Apply relevant signals in context for exploratory analysis. Going deeper into this example shows how Dynatrace provides an unprecedented level of exploratory analysis for both OneAgent and other data sources.
Fast and efficient log analysis is critical in todays data-driven IT environments. For enterprises managing complex systems and vast datasets using traditional log management tools, finding specific log entries quickly and efficiently can feel like searching for a needle in a haystack.
To manage these complexities, organizations are turning to AIOps, an approach to IT operations that uses artificial intelligence (AI) to optimize operations, streamline processes, and deliver efficiency. AI for IT operations (AIOps) uses AI for event correlation, anomaly detection, and root-cause analysis to automate IT processes.
Traces are used for performance analysis, latency optimization, and root cause analysis. The OpenTelemetry Protocol (OTLP) plays a critical role in this framework by standardizing how systems format and transport telemetry data, ensuring that data is interoperable and transmitted efficiently. Integration with existing tools.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
Efficient coordination among resource usage, requests, and allocation is critical. As every container has defined requests for CPU and memory, these indicators are well-suited for efficiency monitoring. One option is to continuously track the Memory utilization efficiency of existing Kubernetes objects, such as namespaces or workloads.
Other benefits include faster software innovation, continuously improved user experiences, and increased operational efficiency, achieved with automatic and intelligent observability. Through customer interviews and financial analysis, Forrester found that a composite organization will experience benefits of $20.16 Dynatrace news.
Adding Dynatrace runtime context to security findings allows smarter prioritization, helps reduce the noise from alerts, and focuses your DevSecOps teams on efficiently remedying the critical issues affecting your production environments and applications. This is the key to smarter prioritization and noise reduction.
Adopting AI to enhance efficiency and boost productivity is critical in a time of exploding data, cloud complexities, and disparate technologies. The Dynatrace and Microsoft partnership provides innovative solutions that enhance customer experience, improve efficiency, and generate considerable savings.
A 2022 Outage Analysis report found that enterprises are struggling to achieve a measurable reduction in outage rates and severity. Maintenance: Reduces the risk of an incident occurring again with root-cause analysis and continuous improvements to the system. MTTR measures the efficiency of your entire incident response capability.
Communicating security insights efficiently across teams in your organization isn’t easy Security management is a complex and challenging task; effectively communicating security insights is even more so. The CISO wants to know if the organization is exposed and asks you to provide a risk analysis and plan of action for remediation ASAP.
As batch jobs run without user interactions, failure or delays in processing them can result in disruptions to critical operations, missed deadlines, and an accumulation of unprocessed tasks, significantly impacting overall system efficiency and business outcomes. The urgency of monitoring these batch jobs can’t be overstated.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. “Logging” is the practice of generating and storing logs for later analysis. Dynatrace news. billion in 2020 to $4.1 What is log monitoring?
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. Log monitoring enables the collection of log data, and log analysis promotes intelligent, data-driven decision making. Dynatrace news.
This self-monitoring aspect is crucial for maintaining the health and efficiency of the Collector itself, ensuring that it can handle the demands of large-scale data collection and processing without degradation. In practical applications, percentiles are particularly useful for web performance analysis.
Runtime vulnerability analysis. Runtime vulnerability analysis helps reduce the time and cost to find and fix application vulnerabilities. By leveraging the combined strengths of Dynatrace and Microsoft Sentinel, enterprises can achieve a comprehensive security posture for enhanced operational efficiency.
With the seamless integration between Dynatrace and ServiceNow, organizations can successfully manage software systems to efficiently route incidents to responsible teams.
Enhances business insight and efficiency with real-time data Organizations can focus on what is important with deep insights on user sessions, top devices, OS versions, and behavioral analytics for iOS, Android, and hybrid apps. Mobile monitoring with the Dynatrace observability and security platform provides the following key benefits.
And when outages do occur, Dynatrace AI-powered, automatic root-cause analysis can also help them to remediate issues as quickly as possible. Hypermodal AI fuels automatic root-cause analysis to pinpoint the culprit amongst millions of service interdependencies and lines of code faster than humans can grasp.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Davis AI root cause analysis is used to pinpoint the problem, entity, and root cause. Executing corrective actions. Keeping relevant stakeholders in the loop. In-context topology identification.
Davis AI efficiently identified the deployment change as the potential root cause for the malfunctioning of nginx. Predictive traffic analysis Deploying OneAgent within the staging environment facilitates the availability of telemetry data for analysis by Davis AI. Davis AI can leverage this data to enable predictive analysis.
Moreover, seamless integration is achieved through out-of-the-box solutions that connect, transform, and map your findings data into a unified format using the Dynatrace Semantic Dictionary, ensuring a smooth and efficient security workflow. In-depth analysis of security findings using tools like Notebooks and Security Investigator.
As global warming advances, growing IT carbon footprints are pushing energy-efficient computing to the top of many organizations’ priority lists. Energy efficiency is a key reason why organizations are migrating workloads from energy-intensive on-premises environments to more efficient cloud platforms.
Based on your requirements, you can select one of three approaches for Davis AI anomaly detection directly from any time series chart: Auto-Adaptive Threshold: This dynamic, machine-learning-driven approach automatically adjusts reference thresholds based on a rolling seven-day analysis, continuously adapting to changes in metric behavior over time.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content