This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An average of 434 ms is awful, and a small queue size (aqu-sz) indicates it's a problem with the disk and not the workload applied. Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util nvme0n1 4.40 I want to see distributions and event logs. But first, about this disk. Hit Ctrl-C to end.
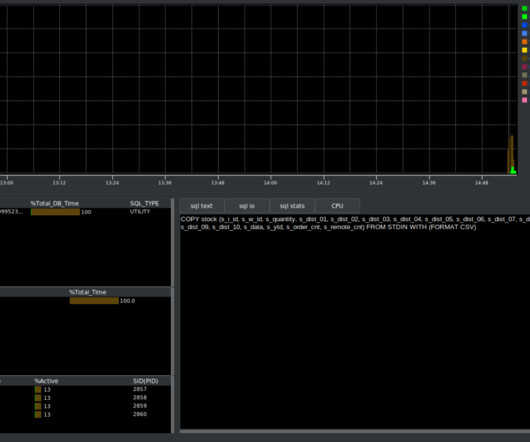
During a copy operation, the data is transferred from the client’s file system to the Aurora PostgreSQL DB cluster. To use pgSentinel we have installed pg_stat_statements and pgsentinel and added the following to our postgresql.conf. and start the build running.
An average of 434 ms is awful, and a small queue size (aqu-sz) indicates it's a problem with the disk and not the workload applied. Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util nvme0n1 4.40 I want to see distributions and event logs. But first, about this disk. Hit Ctrl-C to end.
An average of 434 ms is awful, and a small queue size (aqu-sz) indicates it's a problem with the disk and not the workload applied. Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util nvme0n1 4.40 I want to see distributions and event logs. But first, about this disk. Hit Ctrl-C to end.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content