This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
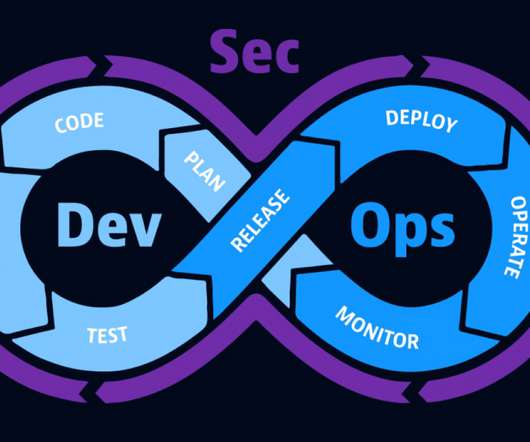
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
Not surprisingly, the theme of Infosec Europe 2022 Conference is “Stronger together,” putting an emphasis on IT collaboration. DevSecOps practices build on DevOps, ensuring that security concerns are top of mind as developers build code. Learn how security improves DevOps. DevOps vs. DevSecOps – blog.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
Cloud-native applications now dominate IT as DevOps teams respond to growing demands to deliver functionality faster and more securely. As DevOps teams are pivoting to cloud-native technologies, IT environments have become increasingly complex. Dynatrace news. Improving cross-team collaboration improves cloud-native success.
The CVE Program, which publishes vulnerabilities as they become known, reported a 25% increase in vulnerabilities between 2021 and 2022. This includes collecting metrics, logs, and traces from all applications and infrastructure components. As organizations develop new applications, vulnerabilities will continue to emerge.
As a result, site reliability has emerged as a critical success metric for many organizations. surpassed $387 billion in 2022, more than double the figure of three years earlier. Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019.
SLOs have evolved beyond basic target measurements; they are powerful guidance tools for site reliability engineers (SREs) and DevOps platform teams to help direct areas of improvement in both CI/CD as well as production processes of every organization. Step 4: Identify key metrics to use as service-level indicators (SLIs).
The 2022 State of SRE Report surveyed 450 SREs across a variety of organizations about how they view SRE today and where they see it evolving as a discipline. More than half (54%) of respondents reported that too many metrics made finding the relevant ones difficult. Check out the webinar or download the 2022 State of SRE Report.
During the Dynatrace Perform 2022 session “Get actionable answers at scale from OpenTelemetry,” Dynatrace product manager, Arlindo Lima, and W.W. Dynatrace’s observability platform is an example of how OpenTelemetry metrics can be enhanced for better visibility. ” Extended visibility. Watch session now!
According to the Cloud Native Computing Foundation (CNCF), 84% of organizations are using or evaluating Kubernetes , up from 81% in 2022. By over-rotating on log analysis, Spier and his team were missing the value, cost savings, and productivity that come from having metrics, traces and logs all in one place and in context.
How Mitchells & Butlers brought the business together with DevOpsmetrics from Dynatrace – blog Many organizations are undergoing a digital transformation. DevOpsmetrics and digital experience data are critical to this. Learn more. Here is what they reported.
65% of businesses report that 40% of their customers now engage with them through mobile devices , and 70% of digital businesses will require IT and Ops to report digital metrics by 2025. AIOps leverages user experience data to inform DevOps. ” These answers are now critical for business success.
These are two values he shares with DevOps activist Andreas Grabner, who sat down with Hightower at Dynatrace Perform 2022 to talk about taming Kubernetes and the future of cloud-native technologies. As a developer, I can say these are the metrics I care about and just give them to you. The art—and science—of simplicity.
In a presentation at the Perform 2022 conference, Huetter uses the IBM Z platform to expand on the benefits of using an observability platform to manage hybrid cloud infrastructure. Below that depicts which applications are causing failures and how many users have been affected, so DevOps teams can identify which problems to fix first.
Organizations that have achieved SRE maturity have a better handle on the state of their infrastructure, the ability to tie reliability metrics more tightly to business objectives, and the means to ensure a consistent and responsive customer experience. Dynatrace’s 2022 State of SRE Report surveyed 450 SREs across the globe.
AIOps aims to provide actionable insight for IT teams that helps inform DevOps, CloudOps, SecOps, and other operational efforts. According to the Dynatrace 2022 Global CIO Report , organizations are under more pressure than ever to keep pace with digital transformation. But AIOps also improves metrics that matter to the bottom line.
Whether it’s an email notification coming in the middle of the night or a customer calling while you are driving home, it‘s the job of SREs working in the DevOps space to ensure that applications and the infrastructure are up and running. Both app versions are available via the marketplaces in parallel until the end of December 2022.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. To solve this problem, Dynatrace launched Grail, its causational data lakehouse , in 2022. Logs on Grail, included in the 2022 release, enables an endless variety of log-based use cases.
Adopting this powerful tool can provide strategic technological benefits to organizations — specifically DevOps teams. This ease of deployment has led to mass adoption, with nearly 80% of organizations now using container technology for applications in production, according to the CNCF 2022 Annual Survey.
At Dynatrace Perform 2022, Dynatrace Product Manager Florian Geigl and Senior Product Manager Matt Reider discuss the key DevOps challenges of Kubernetes complexity and explore how Dynatrace streamlines operations. Then, it ties these issues to specific business effects and metric anomalies.
According to the Global CIO Report 2022 , 71% of CIOs say the explosion of data produced by cloud-native technology stacks is beyond human abilities to manage manually. By following a programmatical approach, developers, DevOps and SREs benefit from a single source of truth and streamlined collaboration.
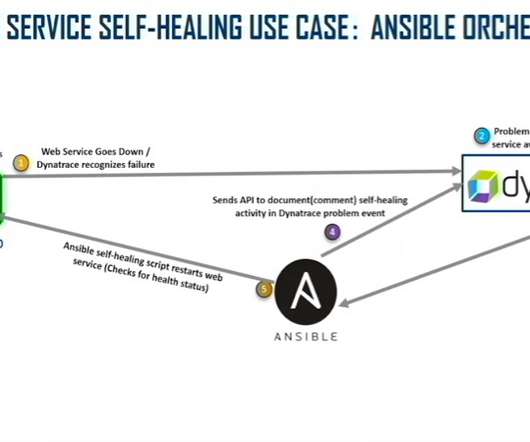
At Dynatrace Perform 2022 , David Walker, a Lockheed Martin Fellow, and William Swofford, a full-stack engineer at Lockheed Martin, discuss how to create a self-diagnosing and self-healing IT server environment using this AIOps combination for auto-baselining, auto-remediation, monitoring as code, and more.
Dynatrace also named a Gartner Customers’ Choice Customers also named Dynatrace a Customers’ Choice in the latest Gartner® Peer Insights™ Voice of the Customer: Application Performance Monitoring report, from November 2022. In these two reports, Dynatrace is the only provider to be recognized as a Leader and as a Customers’ Choice.
Flow Metrics are a major pillar of how we measure improvement in value streams. . As organizations begin to adopt Flow Metrics , our natural tendencies emerge to massage the newfound visibility to make the metrics “look good”. Flow Metrics anti-pattern: Excluding part of the value stream. Chop up the value stream.
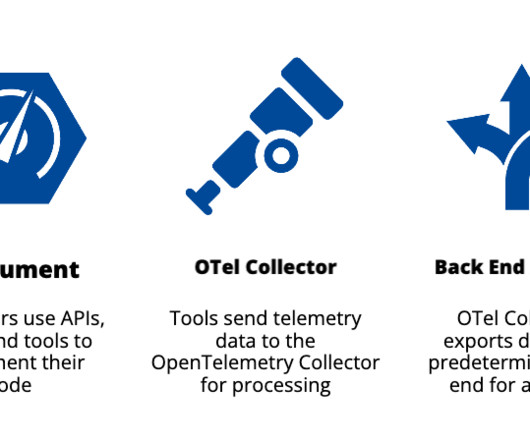
How OpenTelemetry works Observability data is the stock-in-trade of OpenTelemetry: Logs, metrics, and traces. OpenTelemetry works by providing developers with APIs, SDKs, and tools to instrument their code and collect telemetry data such as logs, metrics, and traces. It’s also being built into Kubernetes.” But one blind spot remained.
The demo has been in active development since the summer of 2022 with Dynatrace as one of its leading contributors. Jaeger and Prometheus backends for displaying the collected traces and metrics, but you can easily configure alternative backends. is the custom metrics ingest endpoint that is used by the collector to export metrics.
In a session at Dynatrace Perform 2022, Kopp joins Tim Gerlach, Product Owner of APM at SAP Business Platform to describe how. For example, OpenTelemetry for instrumenting microservices, Fluentd for collecting logs, and Prometheus for collecting metrics. Nonetheless, they still want to collect metrics, traces, and logs.
They predicted this figure would jump to 75% by 2022. Some SCA and SAST vendors have automated their products to align with the fast pace of modern DevOps teams, but many are still slow and cumbersome. Containers have become hugely popular. So far, their prediction seems to be spot-on. Run source code tests. The best of all worlds.
To that end, in 2022, Dynatrace released Grail , the auto-indexing, schema-on-read data lakehouse, along with Notebooks and Dashboards. Start by asking yourself what’s there, whether it’s logs, metrics, or traces. Once you double down on the type, you want to figure out, or browse, which metric is relevant.
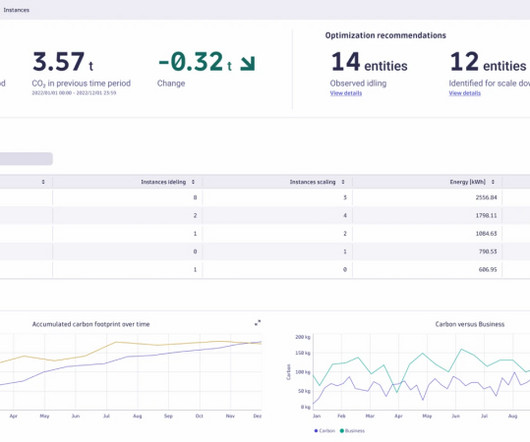
The cloud now has a greater carbon footprint than the airline industry,” wrote anthropologist Steven Gonzalez Monserrate in a 2022 article from MIT. “A The app’s advanced algorithms and real-time data analytics translate utilization metrics into their CO2 equivalent (CO2e). These metrics include CPU, memory, disk, and network I/O.
According to the 2022 Global CIO Report , 71% of CIOs from large organizations said all this data is beyond humans’ ability to manage. We start with data types—logs, metrics, traces, routes. IT teams can resort to playing defense, fighting daily fires rather than focusing on more important tasks, like innovation.
It also enables the agile DevOps development techniques that have been adopted by 83% of IT organizations, according to Puppet. Agile DevOps practices using cloud platforms needn’t be subject to the management overhead of traditional monolithic development. The principles of cloud-native architecture.
Sustainability at AWS re:Invent 2022 -All the talks and videos I could find… Las Vegas MSG Sphere under construction next door to the Venetian Sands Expo Center — Photo by Adrian This blog post is long overdue — I spent too long trying to find time to watch all the videos, and finally gave up and listed a few below that I haven’t seen.
Attendees at the DevOps Enterprise Summit in Europe last week had the opportunity to hear from leaders at Tasktop as they delivered sessions around the shift from project to product. The post DOES Europe 2022—Day 1 Wrap-up appeared first on Tasktop Blog.
photo by Adrian I gave a talk at Monitorama in Portland Oregon in June, which set out the idea that carbon is just another metric to monitor, and that in a few years most of the monitoring and performance tuning tools are going to be reporting and optimizing for carbon alongside latency, throughput, availability and cost.
If you were on a desert island and forced to bring only one service level objective of a successful application, you would absolutely want to keep tracking user journeys, leaving the rest of the metrics behind. Continuously deploying new releases at 100X or 1000X speed is a DevOps state of flow all organizations strive for. license.
The latest DevOps Research and Assessment (DORA) survey found that highly evolved organizations are twice as likely to be very product-oriented compared to mid-level organizations. Meanwhile, 40% of large enterprises are estimated to manage internal business capabilities as products by 2022.
For that reason, the tools and platforms that an SRE uses can vary greatly from organization to organization, especially in 2022. Terraform, along with Ansible, which we will talk about more next, are two of the most used tools for a site reliability engineer and DevOps teams. so they are going to see more tools in that toolbelt.
billion by 2022 and growing at a respectable 13.7% Even better, we can glean valuable end-to-end system data that can be used for higher-level business-centric Flow Metrics , empowering you to generate more business value through your software delivery. . There’s a reason that the data integration market is expected to be worth $12.24
More specifically, a 2022 ITIC survey found that downtime costs more than $300,000 per hour for 91% of small-, mid-size, and large enterprises. ” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content