This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Read the complete test methodology.
By Jennifer Shin , Tejas Shikhare , Will Emmanuel In 2022, a major change was made to Netflix’s iOS and Android applications. And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. Until recently, an internal API framework, Falcor , powered our mobile apps.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. It was a great privilege. Ford, et al., “TCP
2022-05-16T10:00:00+00:00. 2022-05-16T14:04:13+00:00. Examples of this might be, expecting that the HTML is fully static, such that we can cache it downstream in some deterministic manner — “partially dynamic” HTML bodies are much more likely to be handled incorrectly by caching logic. Sean Roberts.
KeyCDN is always looking for ways to minimize latency and accelerate the delivery of assets worldwide. POP in Bogotá - Colombia Bogotá is experiencing rapid growth, and in 2022 the population of Colombia's capital climbed to 7.9 So far, we could cover Latin America through Mexico City, Santiago, and São Paulo.
With a dedicated POP, latency for visitors is reduced even further, resulting in better loading times. The total population of Ireland as of January 2022 was 5 million, with approximately 2 million residents in the greater Dublin area. The total population of Peru in 2022 was about 33.5
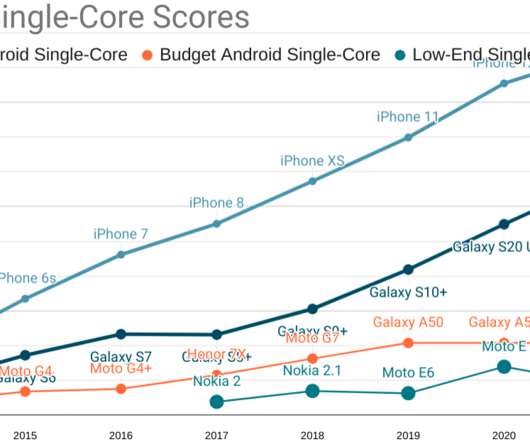
Per the 2022 Web Almanac , which pulls data from real-world devices via the CrUX dataset , today's web offers poor performance for most users. These devices feature: Eight slow, big.LITTLE ARM cores (A75+A55, or A73+A53) built on last-generation processes with very little cache. 4GiB of RAM. Qualcomm has some 'splainin to do.
I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available. Many HPC workloads synchronize work on a barrier, and work much better if there’s a consistently narrow latency distribution without a long tail.
The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. There are three generations of GPUs that are relevant to this comparison. There are two differences that improve the results.
2022-09-27T14:00:00+00:00. 2022-09-27T16:33:12+00:00. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage. Caching Schemes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content