This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. In recommendation systems, context windows during inference are often limited to hundreds of eventsnot due to model capability but because these services typically require millisecond-level latency. Zhai et al.,
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. km university campus.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
This will reduce the total number of image operations because once the image has been processed it will be cached by our shield servers, allowing our edge servers to pull and cache the processed image instead of having to process the image again. This will improve the image processing performance and decrease the overall cost.
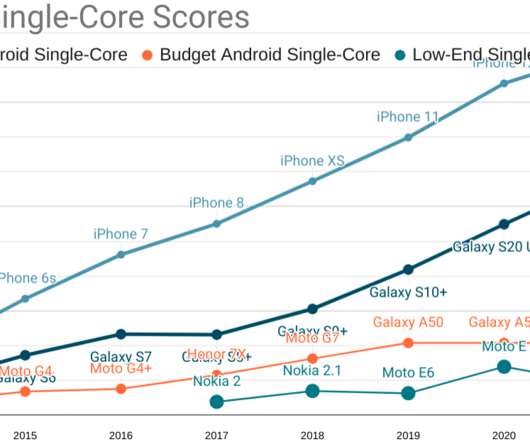
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. The worldwide ASP 18 months ago was ~$300USD , so the average performance in the deployed fleet can be represented by a $300 device from mid-2019. So what did $150USD fetch in 2019?
Without beating around the bush, our ASP 2019 device was an Android that cost between $300-$350, new and unlocked. These devices feature: Eight slow, big.LITTLE ARM cores (A75+A55, or A73+A53) built on last-generation processes with very little cache. 4GiB of RAM. Qualcomm has some 'splainin to do.
Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. total used free shared buff/cache available Mem: 64414 15421 349 5 48643 48409 Swap: 0 0 0. This is a 64-Gbyte memory system, and 48 Gbytes is in the page cache.
2019-04-17T12:30:16+02:00. 2019-04-29T18:34:58+00:00. The browser caches the results of these lookups, but they can be slow. This typically happens once per server and takes up valuable time — especially if the server is very distant from the browser and network latency is high. Drew McLellan. The as Attribute.
Well, according to HTTP Archive , as of June 1, 2019 the average desktop page is 1,896.8 KeyCDN’s Cache Enabler plugin is fully compatible the HTML attributes that make images responsive. The main reason is because it decreases the latency to the user where they are located by serving your images from a POP physically closest to them.
The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. Before the implementation of our Bucharest POP, Romanian users were delivered content from our surrounding KeyCDN POPs.
Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data. There is a lot of awesome technology involved with Hyperscale in how it is architected to use SSD-based caches and page servers. Azure SQL Managed Instance Performance Considerations.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Because HTTP redirection is handled server-side, it is typically faster than client-side redirection, especially if the browser can cache the new location of the requested file. Originally published September 2016, updated July 2019. Using JavaScript Redirection. Keep in mind that all of these methods add time to your page loads.
The L3 cache size is 64MB. The L3 cache size is 64MB. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 On March 25, 2019, Microsoft announced the availability of higher performance, larger capacity managed disks for Azure VMs. lanes for I/O connectivity. Azure Lsv2 Details.
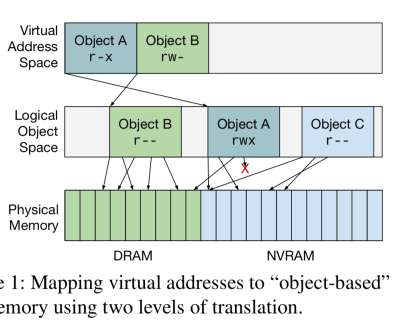
HotStorage 2019. At 0.4ns, we’re in the same ballpark as regular L1 cache reference latency. A tale of two abstractions: the case for object space , Bittman et al., That makes sense, because the test ‘repeatedly deferenced a persistent pointer,’ so we’d expect everything to be in L1. The last word.
Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. This is a 64-Gbyte memory system, and 48 Gbytes is in the page cache (the file system cache). This shows many cache misses, with a hit ratio varying between 6.5
with its low latency I/O operations, gives the benefit of ‘No buffering’ to developers. 12.9.0 – August 20, 2019; 16.8.6 – May 6, 2019. Caching of individual modules. Scalability: Applications developed with Node.js can be scaled vertically and horizontally to improve their performance. Network: Node.js
To this end, having a solid caching strategy can make all the difference for your visitors. ?? How is your knowledge of caching and Cache-Control headers? — Harry Roberts (@csswizardry) 3 March, 2019. Cache-Control. The amount of control we’re granted makes for very intricate and powerful caching strategies.
The Apache MADLib project is still going strong, and the recent (July 2019) 1.16 A pipeline breaker occurs when the output of one operator must be materialized to disk or transferred over the network, as opposed to being directly communicated from operator to operator via CPU cache, or, in the worst case, via RAM.
Using an image CDN, such as KeyCDN, can significantly reduce the latency of your image delivery. Well, according to HTTP Archive , as of June 1, 2019 the average desktop page is 1,896.8 width=600&quality=70 Combine this with our WebP caching to automatically deliver the highest performing image format.
Front-End Performance Checklist 2019 [PDF, Apple Pages, MS Word]. Front-End Performance Checklist 2019 [PDF, Apple Pages, MS Word]. 2019-01-07T12:00:13+00:00. 2019-04-29T18:34:58+00:00. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Vitaly Friedman.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content