This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. In recommendation systems, context windows during inference are often limited to hundreds of eventsnot due to model capability but because these services typically require millisecond-level latency. Kang and J. 2018.00035.
It's HighScalability time: This is your 1500ms latency in real life situations - pic.twitter.com/guot8khIPX. — Ivo Mägi (@ivomagi) November 27, 2018. Do you like this sort of Stuff? Please support me on Patreon. I'd really appreciate it. Know anyone looking for a simple book explaining the cloud?
SCM slots between DRAM and flash in terms of latency, cost, and density. dr_c0d3 : 2000: Write 100s of lines of XML to "declaratively" configure your servlets and EJBs 2018: Write 100s of lines of YAML to "declaratively" configure your microservices At least XML had schemas. sethearley : 7 areas of opportunity for #AI in teaching.
Delay is Not an Option: Low Latency Routing in Space , Murat ). It's HighScalability time: Curious how SpaceX's satellite constellation works? Here's some fancy FCC reverse engineering magic. Do you like this sort of Stuff? Please support me on Patreon. I'd really appreciate it. Know anyone looking for a simple book explaining the cloud?
This is exactly what Rawgit did in October 2018, yet (at the time of writing) a crude GitHub code search still yielded over a million references to the now-sunset service, and almost 20,000 live sites are still linking to it! On a slower, higher-latency connection, the story is much, mush worse. Risk: Service Shutdowns. to just 3.6s.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system. Warm capacity.
Tim Bray : How to talk about [Serverless Latency] · To start with, don’t just say “I need 120ms.” Whether it’s database or message queues it’s a really weird combo of licenses and features for hostage. Because nobody knows how to make money. Support contracts aren’t enough.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
A typical example of modern "microservices-inspired" Java application would function along these lines: Netflix : We observed during experimentation that RAM random read latencies were rarely higher than 1 microsecond whereas typical SSD random read speeds are between 100–500 microseconds.
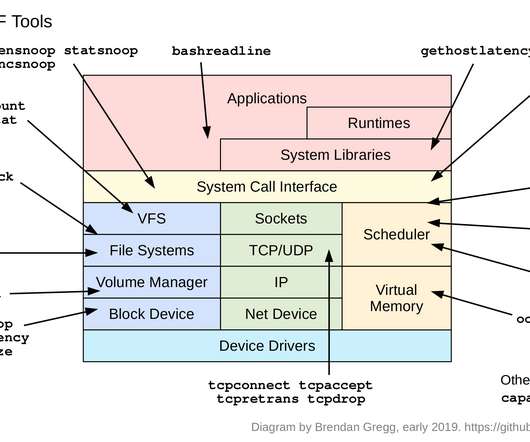
Screenshot: tracing read latency for PID 181: # bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'. Here's key differences as of August 2018: Type DTrace bpftrace. It's shaping up to be a DTrace version 2.0: I wrote seeksize.d
For the first time in history, a VC-backed startup in 2018 was more likely to sell to a PE buyer than a fellow VC-backed company. TServerless : We sat with a solution architect, apparently they are aware of the latency issue and suggested to ditch api gw and build our own solution. 10% : Netflix captured screen time in US; 8.3
12 million requests / hour with sub-second latency, ~300GB of throughput / day. @coryodaniel : Rewrote an #AWS APIGateway & #lambda service that was costing us about $16000 / month in #elixir. Its running in 3 nodes that cost us about $150 / month. myelixirstatus !#Serverless.No Serverless.No
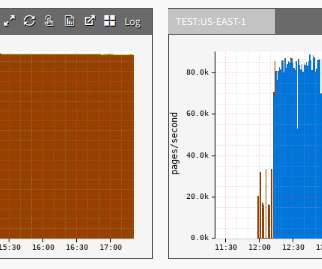
The image below shows a significant drop in latency once we've launched the new point of presence in Israel. In fact, latency has been reduced by almost 50%! With a total of 5 POPs in Oceania, this continent benefits from lower latency with every POP added. With a population of 2.5
ENEL is using AWS to transform its entire business, closing all of their data centers by 2018, migrating workloads from over 6,000 on-premises servers onto AWS in nine months, and using AWS IoT services to better manage and understand energy consumption. ENEL is one of the leading energy operators in the world. million unique visits.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
As mentioned in our earlier blog post , Intel and Netflix have been collaborating on the SVT-AV1 encoder and decoder framework since August 2018. The teams have been working closely on SVT-AV1 development, discussing architectural decisions, implementing new tools, and improving compression efficiency.
There are several emerging data trends that will define the future of ETL in 2018. In 2018, we anticipate that ETL will either lose relevance or the ETL process will disintegrate and be consumed by new data architectures. With the arrival of new cloud-native tools and platform, ETL is becoming obsolete. More details on this approach.
This Region will consist of three Availability Zones at launch, and it will provide even lower latency to users across the Middle East. Plus another AWS GovCloud (US) Region in the United States is coming online by the end of 2018. This news marks the 22nd AWS Region we have announced globally.
They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more. Starting today, developers, startups, and enterprises—as well as government, education, and non-profit organizations—can use the new AWS Europe (Stockholm) Region.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Delta is used in production since 2018 for datastore synchronization and event processing use cases in Netflix studio applications.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Delta is used in production since 2018 for datastore synchronization and event processing use cases in Netflix studio applications.
How many buffers are needed to track pending requests as a function of needed bandwidth and expected latency? Can one both minimize latency and maximize throughput for unscheduled work? These models are useful for insight regarding the basic computer system performance metrics of latency and throughput (bandwidth). Little’s Law.
Screenshot: tracing read latency for PID 181: # bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'. Here's key differences as of August 2018: Type DTrace bpftrace. It's shaping up to be a DTrace version 2.0: I wrote seeksize.d
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. Block I/O latency as a histogram. 6 * 7 * Copyright 2018 Netflix, Inc. 1 /* 2 * biolatency.bt
This week I updated three of those posts — two really old ones (primarily of interest to computer architecture historians), and one from 2018: July 2012: Local and Remote Memory Latency on AMD Processors in 2-socket and 4-socket servers December 2013: Notes on Memory Bandwidth on the Xeon Phi (Knights Corner) Coprocessor January 2018: A Peculiar (..)
This week I updated three of those posts — two really old ones (primarily of interest to computer architecture historians), and one from 2018: July 2012: Local and Remote Memory Latency on AMD Processors in 2-socket and 4-socket servers. December 2013: Notes on Memory Bandwidth on the Xeon Phi (Knights Corner) Coprocessor.
How many buffers are needed to track pending requests as a function of needed bandwidth and expected latency? Can one both minimize latency and maximize throughput for unscheduled work? The M/M/1 queue will show us a required trade-off among (a) allowing unscheduled task arrivals, (b) minimizing latency, and (c) maximizing throughput.
They understood that most websites lack tight latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. This raises a follow-on question: what's an interaction?
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
The truth is that the two tools were fairly distinct until PSI was updated in 2018 to use Lighthouse reporting. INP is a measure of the latency for all interactions on a given page, where the highest latency — or close to it — informs the final score. It’s right there in the name!
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Source: Google /SOASTA Research, 2018. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load. Improvement #2: The Critical Render Path.
Although both countries are relatively close to one another, they are separated by a distance of approximately 500km, which adds up in terms of latency. As of August 2018, Helsinki alone had a population of almost 650,000 people. As for Finland, it covers an area of over 338,000 square kilometers and has a population of over 5.5
If you or your company are able to generate a credible worldwide latency estimate in the higher percentiles for next year's update, please get in touch. Since 2010, volumes have been on a slow downward glide path , shrinking from ~350MM per year in a decade ago to ~260MM in 2018. but which blessedly sports 8GB of RAM.
Azure SQL Database Managed Instance became generally available in late 2018. The General Purpose tier is designed for applications with typical performance and I/O latency requirements and provides built-in HA. The Business Critical tier is designed for applications that require low I/O latency and higher HA requirements.
In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. direct access to raw block storage [18] without the abstraction of a filesystem for workloads that require consistent I/O performance and low latency. Kubernetes has emerged as go to container orchestration platform for data engineering teams.
I can count on one hand the number of teams I’ve worked with who have goals that allow them to block launches for latency regressions, including Google products. — Alex Russell (@slightlylate) August 27, 2018. Few teams I’ve encountered have actionable metrics associated with the real experiences of their users.
Charlie Vazac introduced server timing in a Performance Calendar post circa 2018. Latency – How much time does it take to deliver a packet from A to B. In practice, it looks something like this: server-timing: processing_time; dur=123.4; desc="Time to process request at origin" NOTE: This is not a new API.
India became a 4G-centric market sometime in 2018. Sadly, data on latency is harder to get, even from Google's perch, so progress there is somewhat more difficult to judge. If there's a bright spot in our construction of a 2021 baseline for performance, this is it. 5G looks set to continue a bumpy rollout for the next half-decade.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content