This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I summarized these topics and more as a plenary conference talk, including my own predictions (as a senior performance engineer) for the future of computing performance, with a focus on back-end servers. Ford, et al., “TCP
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. Oracle VM Server is based on Xen. If you choose this route, AWS makes it very easy to create servers (you just need a credit card) and learn how to use them. amazon").
Since then, AWS has added another PoP in Palermo in 2017. ENEL is using AWS to transform its entire business, closing all of their data centers by 2018, migrating workloads from over 6,000 on-premises servers onto AWS in nine months, and using AWS IoT services to better manage and understand energy consumption.
The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. In 2017, we brought the Amazon Global Network to Africa, through AWS Direct Connect. What would have taken two weeks on local servers now only takes a few minutes.
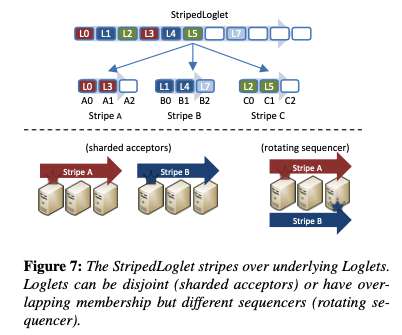
Back in 2017 the engineering team at Facebook had a problem. The initial version of Delos went into production after eight months using a ZooKeeper-backed Loglet implementation, and then four months later it was swapped out for a new custom-built NativeLoglet that gave a 10x improvement in end-to-end latency. Every little helps!
Many database administrators find themselves having to support instances of SQL Server Reporting Services (SSRS), or at least the backend databases that are required for SSRS. These topics apply to both SQL Server Reporting Services as well as Power BI Report Server. Installation and support of SSRS can be confusing.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems.
In support of Amazon Prime Day 2017, the biggest day in Amazon retail history, DynamoDB served over 12.9 percent availability in the event of a server, a rack of servers, or an Availability Zone failure. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
I summarized these topics and more as a plenary conference talk, including my own predictions (as a senior performance engineer) for the future of computing performance, with a focus on back-end servers. Ford, et al., “TCP
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
With Bucharest being the capital and largest city of Romania, it makes for a great edge server location. The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. In 2017, the average speed was 21.33Mb/s ranking them 18th in the world.
A 2017 study by Akamai says as much when it found that even a 100ms delay in page load can decrease conversions by 7% and lose 1% of their sales for every 100ms it takes for their site to load which, at the time of the study, was equivalent to $1.6 Site performance is potentially the most important metric.
The tooling to get a report with details from the time it takes to establish a server connection to the time it takes for the full page to render is out there. In contrast, tools like DebugBear and WebPageTest use more realistic throttling that accurately reflects network round trips on a higher-latency connection.
With Helsinki being the capital and most populous municipality of Finland, it makes for a great edge server location. Although both countries are relatively close to one another, they are separated by a distance of approximately 500km, which adds up in terms of latency. This is a massive increase from year 2000 when only 37.2%
— Alex Russell (@slightlylate) October 4, 2017. Late-loading JavaScript can cause “server-side rendered” pages to fail in infuriating ways. The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. First Load.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. These AMD EPYC processors have a number of advantages for SQL Server workloads, as I will explain in this article. Since then, Microsoft has changed the naming of this series to Lsv2.
According to Monetate , the following conversion rate results were gathered for Q3 of 2017 until Q3 of 2018. Online users are becoming less and less patient meaning you as an eCommerce store owner need to implement methods for reducing latency and speeding up your website. This reduces latency and speeds up your website.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
TL;DR: A lot has changed since 2017 when we last estimated a global baseline resource per-page resource budget of 130-170KiB. To update our global baseline from 2017, we want to update our priors on a few dimensions: The evolved device landscape. The Moto G4 , for example. Here begins our 2021 adventure. Hard Reset.
They understood that most websites lack tight latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. "Server-Side Rendering", a.k.a. "SSR" " [ an intro to "isomorphic javascript", a.k.a. "Server-Side
Thankfully, I found some older linux-devel mailing list archives, rescued from server backups, often stored as tarballs of digests. It's time in some cgroup paths, but this server is not doing much disk I/O. Latency was acceptable and no one complained. My search was starting to feel cursed. to the load average. termc$ uptime.
Is it worth exploring tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, server push, clients hints, HTTP/2, service workers and — oh my — edge workers? Long FMP usually indicates JavaScript blocking the main thread, but could be related to back-end/server issues as well.
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 the ipykernel process) of the jupyter-lab server process , which means the main event loop being injected by pystan is that of the ipykernel process, not the jupyter-server process. The input to stdin is sent to the backend (i.e.,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content