This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The AWS UK region will be our third in the European Union (EU), and we're shooting to have it ready by the end of 2016 (or early 2017). This region will provide even lower latency and strong data sovereignty to local users. Today, I am excited to add the United Kingdom to that list!
1% : performers raked in 60% of all concert-ticket revenue world-wide in 2017—more than double their share in 1982. Quotable Stuff: @mjpt777 : APIs to IO need to be asynchronous and support batching otherwise the latency of calls dominate throughput and latency profile under burst conditions.
A latency outlier issue that happened every 15 minutes. html [The PMCs of EC2]: /blog/2017-05-04/the-pmcs-of-ec2.html Recently that's included: - Debugging why perf profiling stopped working in recent Docker containers. Java core dump analysis for a crashing JVM. - Analyzing slab memory growth on a instance with containers.
Based in the Paris area, the region will provide even lower latency and will allow users who want to store their content in datacenters in France to easily do so. The new region in France will be ready for customers to use in 2017. Cette nouvelle région sera disponible pour les clients dès 2017.
It's HighScalability time: This is your 1500ms latency in real life situations - pic.twitter.com/guot8khIPX. ivanveram : World R&D leading companies 2017 in US$. — Ivo Mägi (@ivomagi) November 27, 2018. Do you like this sort of Stuff? Please support me on Patreon. I'd really appreciate it. 1: Amazon; No.2:
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. Many new tools can now be written, and the main toolkit we're working on is [bcc]. Hit Ctrl-C to end. ^C
The talks are up on YouTube , including my own (behind a paywall, but the slides are freely available [1] ): The talk, like this post, is an update on network and CPU realities this series has documented since 2017. These are depressingly similar specs to devices I recommended for testing in 2017. 2023 Content Targets #. 4GiB of RAM.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.” If you’re interested in attending, please check out the links, and I look forward to meeting and re-meeting many of you there.
Since then, AWS has added another PoP in Palermo in 2017. We needed to serve our growing base of startup, government, and enterprise customers across many vertical industries, including automotive, financial services, media and entertainment, high technology, education, and energy.
The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. In 2017, we brought the Amazon Global Network to Africa, through AWS Direct Connect. It is our first Region in Africa, and we're shooting to have it ready in the first half of 2020.
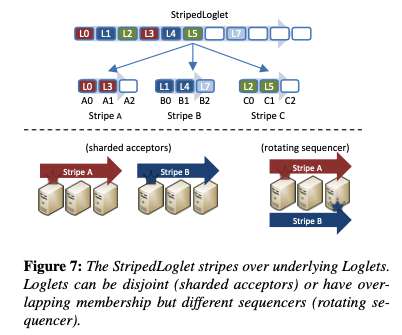
Back in 2017 the engineering team at Facebook had a problem. The initial version of Delos went into production after eight months using a ZooKeeper-backed Loglet implementation, and then four months later it was swapped out for a new custom-built NativeLoglet that gave a 10x improvement in end-to-end latency. Every little helps!
This Region will consist of three Availability Zones at launch, and it will provide even lower latency to users across the Middle East. 2017 continues a busy year for AWS in the Middle East. The Region will be in the heart of Gulf Cooperation Council (GCC) countries, and we're aiming to have it ready by early 2019.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. The change was obvious in the production graphs, showing a drop in write latencies: Once tested more broadly, it showed the write latencies dropped by 43%, delivering slightly better performance than on CentOS.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems. RabbitMQ in Action.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
In April 2017, Amazon Web Services announced that it would launch a new AWS infrastructure region Region in Sweden. They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more.
In support of Amazon Prime Day 2017, the biggest day in Amazon retail history, DynamoDB served over 12.9 Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases. million requests per second.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. As for Romania, it covers an area of over 238,000 square kilometers and as of 2017 had a population of almost 20 million. In 2017, the average speed was 21.33Mb/s ranking them 18th in the world.
If you or your company are able to generate a credible worldwide latency estimate in the higher percentiles for next year's update, please get in touch. So what did $650, give or take, buy in late 2017 or early 2018? But it won't be based on the sort of numbers that folks explicitly running speed tests see; those aren't real life.
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. Another element they have in common is that they are both consuming and producing messages. Apache Kafka is currently the leading project in this area.
In contrast, tools like DebugBear and WebPageTest use more realistic throttling that accurately reflects network round trips on a higher-latency connection. The report, released in 2017, provides network data from sessions collected from real Chrome users. Real usage data would be better, of course.
— Alex Russell (@slightlylate) October 4, 2017. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Maybe "ambush by JS"? First Load.
A 2017 study by Akamai says as much when it found that even a 100ms delay in page load can decrease conversions by 7% and lose 1% of their sales for every 100ms it takes for their site to load which, at the time of the study, was equivalent to $1.6 Site performance is potentially the most important metric.
Although both countries are relatively close to one another, they are separated by a distance of approximately 500km, which adds up in terms of latency. According to Wikipedia , the average connection speed in Q1 of 2017 was 20.5Mbps. This is a massive increase from year 2000 when only 37.2% of the population were Internet users.
For years SSRS was bundled with the installation of SQL Server, which helped add to some of the confusion around licensing and support for the product, so beginning with SSRS 2017, the installation package for Reporting Services is a separate download. Disk latency for ReportServer and ReportServerTempDB are very important.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 Since then, Microsoft has changed the naming of this series to Lsv2. Memory (GiB).
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. The change was obvious in the production graphs, showing a drop in write latencies: Once tested more broadly, it showed the write latencies dropped by 43%, delivering slightly better performance than on CentOS.
Delta Air Lines experienced a severe system outage in 2017, resulting in flight cancellations and delays across their network. Proactive monitoring aids in detecting performance bottlenecks, latency difficulties, and other anomalies that may influence availability.
Delta Air Lines experienced a severe system outage in 2017, resulting in flight cancellations and delays across their network. Proactive monitoring aids in detecting performance bottlenecks, latency difficulties, and other anomalies that may influence availability.
WebGL 2 launched for other platforms on Chrome and Firefox in 2017. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. The underlying graphics capabilities from OpenGL ES 3.0 have been available in iOS since 2013 with iOS 7.0. Offscreen Canvas.
According to Monetate , the following conversion rate results were gathered for Q3 of 2017 until Q3 of 2018. Online users are becoming less and less patient meaning you as an eCommerce store owner need to implement methods for reducing latency and speeding up your website. This reduces latency and speeds up your website.
Gojko Adzic has done some great speaking and writing on his experience here, and I included the link to his talk from late 2017. I also rewrote the section on Startup Latency since Cold Starts are one of the big “FUD” areas of Serverless. I also wrote an article on just this area last year.
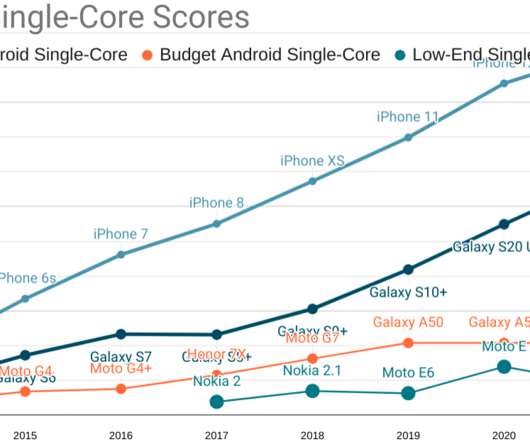
TL;DR: A lot has changed since 2017 when we last estimated a global baseline resource per-page resource budget of 130-170KiB. To update our global baseline from 2017, we want to update our priors on a few dimensions: The evolved device landscape. The Moto G4 , for example. Here begins our 2021 adventure. Hard Reset.
rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU) 10:15:51 PM UID PID %usr %system %guest %CPU CPU Command 10:16:51 PM 0 18468 2.85 Some people have found values that seem to work for their systems and workloads: they know that when load goes over X, application latency is high and customers start complaining.
They understood that most websites lack tight latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. This raises a follow-on question: what's an interaction?
A peculiar throughput limitation on Intel’s Xeon Phi x200 (Knights Landing) Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC.
Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC. simple addition instead of FMA) or with fewer registers and shorter pipeline latency (e.g,
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 This file was introduced in this commit in 2017, with the purpose of improving the performance of user programs that determine aggregate memory statistics. The input to stdin is sent to the backend (i.e., We then exported the .har
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. An interesting way of avoiding parsing costs is to use binary templates that Ember has introduced in 2017. Alex Danilo has explained WebAssembly and how it works at his Google I/O 2017 talk. Bundle Buddy. Bundlephobia.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content