This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now let’s look at how we designed the tracing infrastructure that powers Edgar. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. By 2017, open source projects like Open-Tracing and Open-Zipkin were mature enough for use in polyglot runtime environments at Netflix.
Currently we have 57 Availability Zones across 19 technology infrastructure Regions. Since then, AWS has added another PoP in Palermo in 2017. The Lamborghini website was being hosted on outdated infrastructure when the company decided to boost their online presence to coincide with the launch of their Aventador J sports car.
Written by Jose Fernandez , Arthur Gonigberg , Julia Knecht , and Patrick Thomas In 2017, Netflix Studios was hitting an inflection point from a period of merely rapid growth to the sort of explosive growth that throws “how do we scale?” into every conversation. Our gateways are powered by our flagship open-source technology Zuul.
In April 2017, Amazon Web Services announced that it would launch a new AWS infrastructure region Region in Sweden. Today, we add to that presence with an infrastructure Region in Stockholm with three Availability Zones. They rely on the AWS Cloud for their entire infrastructure and use almost every AWS service available.
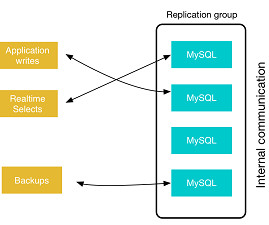
Our straining database infrastructure on Oracle led us to evaluate if we could develop a purpose-built database that would support our business needs for the long term. In support of Amazon Prime Day 2017, the biggest day in Amazon retail history, DynamoDB served over 12.9 million requests per second.
It is versatile enough for deployment in cloud-based infrastructures, on-premise data centers, or local setups, delivering a dependable and adaptable messaging framework. They utilize a routing key mechanism that ensures precise navigation paths for message traffic. RabbitMQ in Action. Manning Publications. Mastering RabbitMQ.
This blog was originally published in October 2017 and was updated in September 2023. 6) Infrastructure limitations Infrastructure and hardware limitations are very similar. When thinking about infrastructure, however, we focus on specific cases when the Mongodb instances should be small.
No single point of failure (SPOF): If the failure of a database infrastructure component could cause downtime, that component is considered an SPOF. Also, in general terms, a high availability PostgreSQL solution must cover four key areas: Infrastructure: This is the physical or virtual hardware database systems rely on to run.
That’s not all, the global mobile traffic is expected to increase sevenfold between 2017 and 2022. Rather than running the tests on a less scalable & high-maintenance in-house infrastructure, automation tests can be performed on Testsigma’s scalable, secure, and low maintenance cloud. CI/CD tools (Jenkins, Circle CI, etc.).
There is no way to model how much more traffic you can send to that system before it exceeds it’s SLA. Bill Kaiser of NewRelic published this blog in 2017 which goes some way towards what I’m talking about, but since then I have figured out a new way to interpret the data.
Delta Air Lines experienced a severe system outage in 2017, resulting in flight cancellations and delays across their network. one of the world's largest online retailers, Amazon relies heavily on its website and digital infrastructure to facilitate sales and generate revenue. High availability is a business imperative in this sector.
Delta Air Lines experienced a severe system outage in 2017, resulting in flight cancellations and delays across their network. one of the world's largest online retailers, Amazon relies heavily on its website and digital infrastructure to facilitate sales and generate revenue. High availability is a business imperative in this sector.
According to Ericsson’s analysis, international mobile data traffic is projected to become 4.5 Twitter Lite PWA : It was integrated as the standard User Interface in 2017. This architecture runs on cloud technology, and developers can focus on the code instead of the scaling, maintenance, and infrastructure facilities.
This blog was originally published in February 2017 and was updated in August 2023. The idea is to use secondary servers on your infrastructure for either reads or other administrative solutions. Solutions like Percona XtraDB Cluster are a component to improve the availability of your database infrastructure.
— Alex Russell (@slightlylate) October 4, 2017. Teams with this support are free to set performance budgets, do “bakeoffs” between competing approaches, and invest in performance infrastructure. We now have everything we need to create a ballpark perf budget for a product in 2017. Maybe "ambush by JS"?
But there are parts of the world where mobile data is prohibitively expensive, and where there is little or no broadband infrastructure. These countries generally have a combination of poor technical infrastructure and low adoption, meaning data is both costly to deliver and doesn’t have the economy of scale to drive costs down.
Durability is a cornerstone of any database system and starting with SQL Server 2017 on Linux Cumulative Update 6 (CU6), SQL Server on Linux enables “Forced Flush” behavior as described in this article , improving durability on non-Fua optimized systems. “Be The trace flag does not apply to SQL Server on Linux SQL 2017 RTM thru CU5.
TL;DR: A lot has changed since 2017 when we last estimated a global baseline resource per-page resource budget of 130-170KiB. To update our global baseline from 2017, we want to update our priors on a few dimensions: The evolved device landscape. The Moto G4 , for example. Here begins our 2021 adventure. Hard Reset.
The simple answer is the first entry (85829) is not what you are used to on a Windows system as sqlservr.exe and does not listen for TDS traffic or open database files. On Windows, if a process terminates unexpectedly the Watson infrastructure is invoked to capture process dumps and add entries to the event log.
However, when we captured packets on the ZeroMQ socket while reproducing the issue, we didn’t observe heavy traffic on this socket that could cause such blocking. Meanwhile, traffic from other ports, such as port 22 for SSH, remained unaffected. the JupyterLab process) rather than the network. Explore the impact you can make with us!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content