This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hardware virtualization for cloud computing has come a long way, improving performance using technologies such as VT-x, SR-IOV, VT-d, NVMe, and APICv. The latest AWS hypervisor, Nitro, uses everything to provide a new hardware-assisted hypervisor that is easy to use and has near bare-metal performance. I'd expect between 0.1%
The mystery begins Towards the end of 2017, I was on a conference call to discuss an issue with the Netflix application on a new set top box. The role of a Partner Engineer at Netflix is to help device manufacturers launch the Netflix application on their devices. aka “Lollipop”.
When this happens, usually a k8s cloud-controller provided by the cloud vendor will detect that the actual server, in our case an EC2 Instance, has actually gone away, and will in turn delete the k8s node object. Where Do Lost Nodes Come From? Nodes can go away for any reason, especially in “the cloud”. UDP packet?
I summarized these topics and more as a plenary conference talk, including my own predictions (as a senior performance engineer) for the future of computing performance, with a focus on back-end servers. This was a chance to talk about other things I've been working on, such as the present and future of hardware performance.
If your application runs on servers you manage, either on-premises or on a private cloud, you’re responsible for securing the application as well as the operating system, network infrastructure, and physical hardware. What are some key characteristics of securing cloud applications?
Recognized as the fastest growing database by popularity, PostgreSQL was named the DBMS of the year in both 2018 and 2017 by DB-Engines, and continues to grow in popularity in 2019. Oracle support for hardware and software packages is typically available at 22% of their licensing fees. In fact, PostgreSQL is so popular, 11.5%
Linux has been adding tracing technologies over the years: kprobes (kernel dynamic tracing), uprobes (user-level dynamic tracing), tracepoints (static tracing), and perf_events (profiling and hardware counters). Oracle VM Server is based on Xen. amazon"). I also wrote and published an entertaining SMF manifest that played music.
Tom Davidson, Opening Microsoft's Performance-Tuning Toolbox SQL Server Pro Magazine, December 2003. Waits and Queues has been used as a SQL Server performance tuning methodology since Tom Davidson published the above article as well as the well-known SQL Server 2005 Waits and Queues whitepaper in 2006.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
Hardware virtualization for cloud computing has come a long way, improving performance using technologies such as VT-x, SR-IOV, VT-d, NVMe, and APICv. The latest AWS hypervisor, Nitro, uses everything to provide a new hardware-assisted hypervisor that is easy to use and has near bare-metal performance. I'd expect between 0.1%
TL;DR: A lot has changed since 2017 when we last estimated a global baseline resource per-page resource budget of 130-170KiB. To update our global baseline from 2017, we want to update our priors on a few dimensions: The evolved device landscape. Hardware Past As Performance Prologue. The Moto G4 , for example. Hard Reset.
On August 7, 2019, AMD finally unveiled their new 7nm EPYC 7002 Series of server processors, formerly code-named "Rome" at the AMD EPYC Horizon Event in San Francisco. This is the second generation EPYC server processor that uses the same Zen 2 architecture as the AMD Ryzen 3000 Series desktop processors.
A close monitoring of the hardware enthusiast community, including many of the most respected hardware analysts and reviewers paints an even more dire picture about Intel in the server processor space. Despite all of this, Intel is not going to lose their entire server processor business any time soon.
This blog was originally published in October 2017 and was updated in September 2023. Sharding in MongoDB is a technique used to distribute a database horizontally across multiple nodes or servers, known as “shards.” MongoDB distributes data across these shard servers to ensure an even distribution.
In general terms, to achieve HA in PostgreSQL, there must be: Redundancy: To ensure data redundancy and provide continuous performance when a primary server fails, multiple copies of the database reside in replica servers. When the primary server fails, a standby server takes over as the new primary.
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. I will compare AWS Aurora with MySQL (Percona Server) 5.6 84.1 | | version_comment | Percona Server (GPL), Release 84.1, With faster disks (i.e. MySQL on ec2.
I summarized these topics and more as a plenary conference talk, including my own predictions (as a senior performance engineer) for the future of computing performance, with a focus on back-end servers. This was a chance to talk about other things I've been working on, such as the present and future of hardware performance.
This follow-up post revisits the question for SQL Server 2019, using a larger number of rows. It has 32GB RAM, with 24GB available to the SQL Server 2019 instance. It would be nice if SQL Server could push the aggregation down into the scan and just return distinct values from the column store directly. Test Environment.
This server is spending about a third of its CPU cycles just checking the time! As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. 30.14% in the middle of the flame graph. Searching shows it was elsewhere as well for a total of 32.1%.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
Thankfully, I found some older linux-devel mailing list archives, rescued from server backups, often stored as tarballs of digests. It's time in some cgroup paths, but this server is not doing much disk I/O. My search was starting to feel cursed. But it was somehow missing from all of them. to the load average. Yes, I'd say so.
— Alex Russell (@slightlylate) October 4, 2017. Late-loading JavaScript can cause “server-side rendered” pages to fail in infuriating ways. The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. First Load.
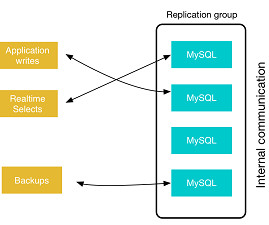
This blog was originally published in February 2017 and was updated in August 2023. The idea is to use secondary servers on your infrastructure for either reads or other administrative solutions. Network Connectivity: Establish a reliable network connection between the primary and replica servers. Restart the MySQL service.
Richard Thaler won the 2017 Nobel prize in Economics for his work on Behavioral Economics. Hardware engineers design and implement solutions in RTL, while software engineers attempt to solve the problem either at the OS or application level. We believed existing hardware and OS protocols protected the processor.
I recently was asked the following question by an online retailer: “Why should I invest in monitoring the user experience when I already have monitoring for our database, infrastructure, app server, and network?”. 38% of all sites measured in Sept 2017 (~500K) are more than 75% 3rd party content. The Rise of Cloud Computing.
STELLA: report from the SNAFU-catchers workshop on coping with complexity , Woods 2017, Coping with Complexity workshop. Today’s choice is a report from a 2017 workshop convened with that title, and recommended to me by John Allspaw – thank you John! How do participants do that?
This server is spending about a third of its CPU cycles just checking the time! As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. 30.14% in the middle of the flame graph. Searching shows it was elsewhere as well for a total of 32.1%.
This blog was originally published in July 2017 and was updated in August 2023. KEY partitioning KEY partitioning is similar to HASH partitioning, except that only one or more columns to be evaluated are specified, and the MySQL server provides its own hashing function. So, What is MySQL Partitioning?
SQL Server relies on Forced-Unit-Access (Fua) I/O subsystem capabilities to provide data durability, detailed in the following documents: SQL Server 2000 I/O Basic and SQL Server I/O Basics, Chapter 2. Be sure to deploy SQL Server2017 CU6 or newer for best data durability and performance results. “.
Is it worth exploring tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, server push, clients hints, HTTP/2, service workers and — oh my — edge workers? Long FMP usually indicates JavaScript blocking the main thread, but could be related to back-end/server issues as well.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content