This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Problems include provisioning and deployment; load balancing; securing interactions between containers; configuration and allocation of resources such as networking and storage; and deprovisioning containers that are no longer needed. How does container orchestration work?
When we ask SQL Server to change some aspect of a column's definition, it needs to check that the existing data is compatible with the new definition. Improvements in SQL Server2016. The subject of this post is the additional changes that are enabled for metadata-only from SQL Server2016 onward.
AWS Graviton2); for memory with the arrival of DDR5 and High Bandwidth Memory (HBM) on-processor; for storage including new uses for 3D Xpoint as a 3D NAND accelerator; for networking with the rise of QUIC and eXpress Data Path (XDP); and so on.
In just this past month we've had HSBC , ARM , Missguided , and most recently at re:Invent 2016 , Trainline , talking with us about how they are using AWS to transform and scale their businesses. I have been humbled by just how much our UK customers have been able to achieve using AWS technology so far.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
SQL Server2016 changes the internal design to (CheckScanner), applying no lock semantics and a design similar to those used with In-Memory Optimized (Hekaton) objects, allowing DBCC operations to scale far better than previous releases. Ryan Stonecipher – Principle SQL Server Software Engineer. SQL Server.
In traditional row-mode execution plans, SQL Server may introduce a Bitmap operator as part of performing early semi join reduction before a parallel hash or merge join. There have been major improvements since the first appearance of the batch mode execution engine in SQL Server 2012. Background. The Query Optimizer. Bitmap Choice.
This issue most often occurs when there is significant MySQL server activity during the backup operation, and the redo log file storage media operates faster than the backup storage media. Enabling redo log archiving on the server requires setting a value for the innodb_redo_log_archive_dirs system variable.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
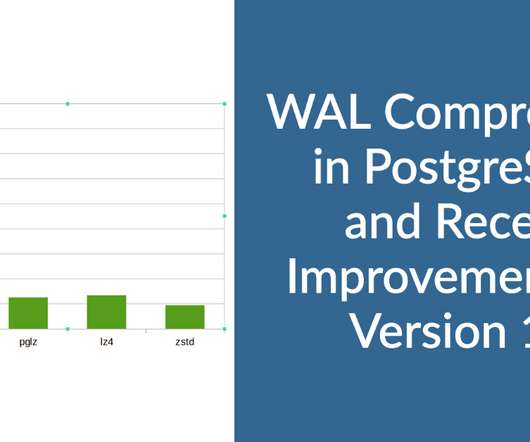
Some of the built-in features ( wal_compression ) have been there since 2016, and almost all backup tools do the WAL compression before taking it to the backup repository. Zstd can be chosen if the server load is not CPU bound because it can give us better compression at the expense of more CPU utilization.
SQL Server2016 Service Pack 1 (all SKUs) , in combination with Windows Server2016 (All SKUs) or Windows 10 Client introduces non-volatile memory support for the tail of the log file (LDF) which can significantly increase transaction throughput. Block storage is what you think of today as disk access.
Why do you need multiple instances on the same server? You can have a host with two or three instances configured as a delayed replica of the source server with SQL Delay of, let’s say, 24hr, 12hr, and 6/3hrs. You can run multiple instances on a server to test your backups with the correct version and configs.
Recovering from a MongoDB rollback involves locating rollback files, using mongorestore to load data into a separate server, cleansing unneeded data, and importing the data back into the primary cluster, coupled with ongoing monitoring and maintenance of replica sets to maintain system health.
Back in 2016, I gave a talk outlining the causes and effects of the terrible performance of web apps built using popular tools on the fastest-growing device segment: low-end to mid-range Android phones. A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage.
now has a version which will support parallelism for SELECT queries (utilizing the read capacity of storage nodes underneath the Aurora cluster). I will compare AWS Aurora with MySQL (Percona Server) 5.6 84.1 | | version_comment | Percona Server (GPL), Release 84.1, MySQL on ec2.
In a recent tip , I described a scenario where a SQL Server2016 instance seemed to be struggling with checkpoint times. I was a bit perplexed by this issue, since the system was certainly no slouch — plenty of cores, 3TB of memory, and XtremIO storage. SQL 2016 – It Just Runs Faster: Indirect Checkpoint Default.
I briefly mentioned that batch mode data is normalized in my last article Batch Mode Bitmaps in SQL Server. You will need SQL Server2016 (or later) and Developer Edition (or equivalent) to reproduce the results shown here. This table uses columnstore for its primary storage to produce batch mode execution later on.
AWS Graviton2); for memory with the arrival of DDR5 and High Bandwidth Memory (HBM) on-processor; for storage including new uses for 3D Xpoint as a 3D NAND accelerator; for networking with the rise of QUIC and eXpress Data Path (XDP); and so on.
It can be activated from SQL Server 2008 to 2014 inclusive using documented trace flag 610. From SQL Server2016 onward, FastLoadContext is enabled by default ; the trace flag is not required. For more background, see the Data Performance Loading Guide and the Tiger Team notes on the behaviour changes for SQL Server2016.
In SQL Server 2012, grouped (vector) aggregation was able to use parallel batch-mode execution, but only for the partial (per-thread) aggregate. SQL Server 2014 added the ability to perform parallel batch-mode grouped aggregation within a single Hash Match Aggregate operator. Columnstore storage. Introduction.
LTS (April 2016). I wrote about it in a previous post, [DTrace for Linux 2016]. I wrote a page on it: [perf]. - **eBPF**: tracing features completed in 2016, this provides efficient programmatic tracing to existing kernel frameworks. Oracle VM Server is based on Xen. The hardest part on Linux is now done: kernel support.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. These AMD EPYC processors have a number of advantages for SQL Server workloads, as I will explain in this article. Since then, Microsoft has changed the naming of this series to Lsv2.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
In this blog, we’ll provide a comparison between MariaDB vs. MySQL (including Percona Server for MySQL ). Introduction: MariaDB vs. MySQL The goal of this blog post is to evaluate, at a higher level, MariaDB vs. MySQL vs. Percona Server for MySQL side-by-side to better inform the decision making process.
Without this guarantee, SQL Server might add index rows that are not sorted correctly, which would not be good. For INSERT.SELECT , SQL Server makes its own determination whether to ensure rows are presented to the Clustered Index Insert operator in key order or not. DMLRequestSort Conditions.
So, apart from powering servers with renewable energy, what else can web developers do about climate change? This includes the work done by the server, the client and the intermediary communications networks that transmit data between the two. In 2016, O’Reilly published “ Designing For Sustainability ” by Tim Frick.
The summary rows for heap tables without indexes are the same in both documents (no changes for SQL Server2016): An explicit TABLOCK hint is not the only way to meet the requirement for table-level locking. The inputs to this calculation are: The version of SQL Server. Target table row size. The Data Size Calculation.
Late-loading JavaScript can cause “server-side rendered” pages to fail in infuriating ways. The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. The true median device from 2016 sold at about ~$200 unlocked.
This includes CDNs, proxy servers, and the like. Once the 60 seconds is up, the browser will head back to the server to revalidate the file. It means ‘do no t serve a copy from cache until you’ve revalidated it with the server and the server said you can use the cached copy’. public and private. Cache-Control: no-cache.
SQL Server relies on Forced-Unit-Access (Fua) I/O subsystem capabilities to provide data durability, detailed in the following documents: SQL Server 2000 I/O Basic and SQL Server I/O Basics, Chapter 2. Be sure to deploy SQL Server 2017 CU6 or newer for best data durability and performance results. “. 4 Socket, TPCC.
In this configuration, the AMI and boot is paravirt (PV), the kernel is making hypercalls instead of privileged instructions, and the system is using paravirt network and storage drivers. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. The AMI and boot are now HVM.
In this configuration, the AMI and boot is paravirt (PV), the kernel is making hypercalls instead of privileged instructions, and the system is using paravirt network and storage drivers. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. The AMI and boot are now HVM.
In a partitioned massively parallel database system, the storage format and sorting algorithm may not be optimized for that operation as we are reading multiple partitions in parallel. voting','maven'] ? ? compose','xamarin','markdown','scrum','comic'] ? ? china','sourceforge','subscription','chinese','kotlin'] ? ?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content