This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS Graviton2); for memory with the arrival of DDR5 and High Bandwidth Memory (HBM) on-processor; for storage including new uses for 3D Xpoint as a 3D NAND accelerator; for networking with the rise of QUIC and eXpress Data Path (XDP); and so on. Ford, et al., “TCP
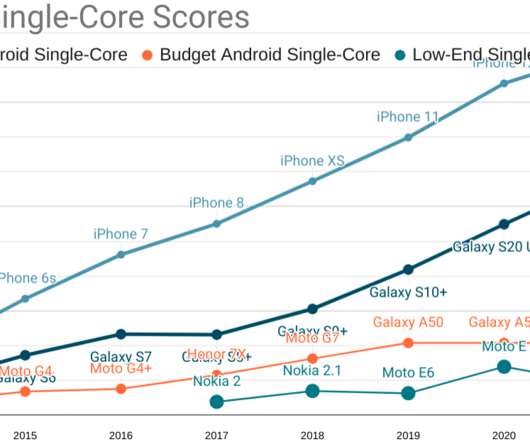
TL;DR : To serve users at the 75 th percentile ( P75 ) of devices and networks, we can now afford ~150KiB of HTML/CSS/fonts and ~300-350KiB of JavaScript (gzipped). This is a slight improvement on last year's budgets , thanks to device and network improvements. That is, what was the average device in 2016?
Thanks to progress in networks and browsers (but not devices), a more generous global budget cap has emerged for sites constructed the "modern" way: ~100KiB of HTML/CSS/fonts and ~300-350KiB of JS (compressed) is the new rule-of-thumb limit for at least the next year or two. Modern network performance and availability.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Screenshot: tracing read latency for PID 181: # bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O.
Performance issues surrounding Availability Groups typically were related to disk I/O or network speeds. Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. one without a replica).
Key Takeaways Rollbacks in MongoDB are triggered by disruptions in the replication process due to primary node crashes, network partitions, or other failures, which can lead to substantial data loss and inconsistencies. This failure in replication could happen due to crashes, network partitions, or other situations where failover occurs.
They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more. We launched Edge Network locations in Denmark, Finland, Norway, and Sweden. Our AWS Europe (Stockholm) Region is open for business now.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools.
We constrain ourselves to a real-world baseline device + network configuration to measure progress. Budgets are scaled to a benchmark network & device. JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. The median user is on a slow network.
AWS Graviton2); for memory with the arrival of DDR5 and High Bandwidth Memory (HBM) on-processor; for storage including new uses for 3D Xpoint as a 3D NAND accelerator; for networking with the rise of QUIC and eXpress Data Path (XDP); and so on. Ford, et al., “TCP
Today we’re excited to announce that we’ve launched yet another POP location to help further supercharge our network’s content delivery speeds. The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. million people. What’s Next?
Today we’re excited to announce that we’ve launched yet another POP location to help further supercharge our network’s content delivery speeds. Although both countries are relatively close to one another, they are separated by a distance of approximately 500km, which adds up in terms of latency. penetration rate.
LTS (April 2016). I wrote about it in a previous post, [DTrace for Linux 2016]. Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. The hardest part on Linux is now done: kernel support. Hit Ctrl-C to end. ^C
A message-oriented implementation requires an efficient messaging backbone that facilitates the exchange of data in a reliable and secure way with the lowest latency possible. In 2016, Apache Spark introduced Structured Streaming , a new streaming engine based on the SparkSQL abstractions and runtime optimizations.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
At the time of the last Confluence run, the gap had stretched to nearly 1000 APIs, doubling since 2016. Real-time network protocols for enabling videoconferencing, desktop sharing, and game streaming applications. Modern, asynchronous network APIs that dramatically improve performance in some situations. Delayed five years.
Time spent on redirect is most noticeable on mobile devices, especially since they tend to use slower networks. By adding the need for additional JavaScript resources to your page, you increase the latency caused by the need to first download the webpage and then parse and execute the JavaScript before the browser can execute the redirect.
We had a great experience in 2016 when we had Jepsen test out the Volt database functionality and needed an update in 2023 due to an incident at a customer site. Partitioning a network for a Volt node. Network communications between Volt nodes are blocked with Linux’s “iptables” command. Why Jepsen Testing? split brain’).
Screenshot: tracing read latency for PID 181: # bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O.
In the latest (October 2016) revision of Intel’s Instruction Extensions Programming Reference , Intel has disclosed a fairly dramatic departure from these “traditional” approaches. With 2 FMA units that have 5-cycle latency, the code must implement at least 2*5=10 independent accumulators in order to avoid stalls.
The best request is the one that never happens: in the fight for fast websites, avoiding the network is far better than hitting the network at all. Any asset that carries the no-store directive will always hit the network, no matter what. We can completely cut out the overhead of a roundtrip of latency.
As well as AWS Regions, we also have 21 AWS Edge Network Locations in Asia Pacific. This enables customers to serve content to their end users with low latency, giving them the best application experience. Since then, AWS has added two more PoPs in Hong Kong, the latest in 2016. In 2013, AWS opened an office in Hong Kong.
billion in 2016. The growing demand for IoT-testing is the government’s gradual acceptance of smart cities’ concept, which is why businesses are keen to incorporate IoT into their networks. Better and quicker services are urgently needed today. There is a huge expansion and the need for a good IoT research plan. .
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content