This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why should a relational database even care about unstructured data? JSON database in 9.2 It is useful to validate incoming JSON and store in the database. JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB Patterns & Antipatterns.
In many, high-throughput, OLTP style applications the database plays a crucial role to achieve scale, reliability, high-performance and cost efficiency. For a long time, these requirements were almost exclusively served by commercial, proprietary databases.
Depending on the type of change and the configuration of the database, an ALTER COLUMN command will need to perform one of the following actions: Change metadata in system tables only. Improvements in SQL Server 2016. The subject of this post is the additional changes that are enabled for metadata-only from SQL Server 2016 onward.
The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams. Cloud databases excel at storing large volumes of information for later reference, and this data often has business value or privacy restrictions.
In the remainder of 2016 and inq 2017, we will launch another four AWS regions in Canada, China, the United Kingdom, and France, adding another nine AZs to our global infrastructure footprint. It brings the worldwide total of AWS Availability Zones (AZs) to 38, and the number of regions globally to 14. The Ohio Region is no different.
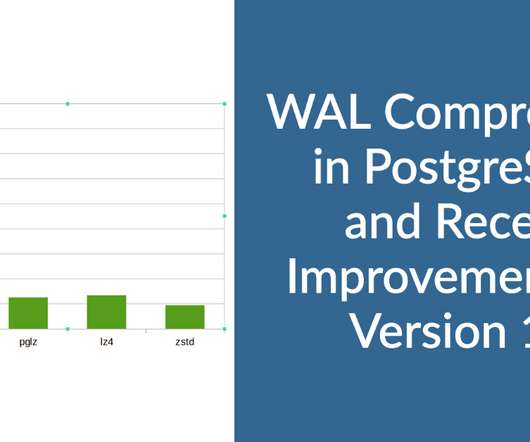
Some of the built-in features ( wal_compression ) have been there since 2016, and almost all backup tools do the WAL compression before taking it to the backup repository. Such “torn pages” are corruptions from the database point of view. This is generally referred to as “ partial page writes ” or “ torn pages.”
SQL Server 2016 changes the internal design to (CheckScanner), applying no lock semantics and a design similar to those used with In-Memory Optimized (Hekaton) objects, allowing DBCC operations to scale far better than previous releases. The following chart shows the same 1TB database testing. SQL Server 2016. or newer release.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). Direct seeding of new database replicas. . Direct seeding of new database replicas.
In this configuration, the AMI and boot is paravirt (PV), the kernel is making hypercalls instead of privileged instructions, and the system is using paravirt network and storage drivers. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. The AMI and boot are now HVM.
This type of backup is suitable for large, important databases that need to be recovered quickly when problems occur. Physical backups are the backups that consist of raw copies of the directories and files that store database contents. Copyright (c) 2016, 2023, Oracle and/or its affiliates. Type 'help' or '?'
Data-bearing members face a higher risk of encountering issues caused by rollbacks, compared to others who utilize different storage methods. For example, memory-resident databases without persistent disks, such as Redis cluster setups or Apache Spark installations, rely on stand-alone machines.
Why not just create another database on the same instance? We split databases by function/team to give each team full autonomy over their schema, And if someone screws up, it breaks their cluster, not all databases. So you put multiple MySQL servers on a single machine instead of multiple databases inside one MySQL instance.
Back in 2016, I gave a talk outlining the causes and effects of the terrible performance of web apps built using popular tools on the fastest-growing device segment: low-end to mid-range Android phones. A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage.
In a recent tip , I described a scenario where a SQL Server 2016 instance seemed to be struggling with checkpoint times. I was a bit perplexed by this issue, since the system was certainly no slouch — plenty of cores, 3TB of memory, and XtremIO storage. Change the Target Recovery Time of a Database.
now has a version which will support parallelism for SELECT queries (utilizing the read capacity of storage nodes underneath the Aurora cluster). I’m using the “Airlines On-Time Performance” database from [link] (You can find the scripts I used here: [link] ). SSD) we can’t utilize the full potential of IOPS with just one thread.
SQL Server 2016 Service Pack 1 (all SKUs) , in combination with Windows Server 2016 (All SKUs) or Windows 10 Client introduces non-volatile memory support for the tail of the log file (LDF) which can significantly increase transaction throughput. Block storage is what you think of today as disk access. Tail Of Log Caching.
Volt Active Data (Volt) is a sophisticated real-time data platform intricately designed with multiple critical components, including high-speed data processing, in-memory storage, and ACID-compliant transactions. These exported records will be written to an external system (such as another database, CSV files, or another streaming platform).
From SQL Server 2016 onward, FastLoadContext is enabled by default ; the trace flag is not required. For more background, see the Data Performance Loading Guide and the Tiger Team notes on the behaviour changes for SQL Server 2016. FastLoadContext can be disabled on SQL Server 2016 using documented trace flag 692. I >= 100.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. Both of these Intel processors are special bespoke models that are not in the Intel ARK database. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0
Before we dive into the differences between MariaDB and MySQL, we will provide a thorough examination of each relational database management system (RDBMS). While originally designed to be a drop-in replacement for MySQL, it evolved into its own distinct database management system and is now maintained and supported by the MariaDB Foundation.
The summary rows for heap tables without indexes are the same in both documents (no changes for SQL Server 2016): An explicit TABLOCK hint is not the only way to meet the requirement for table-level locking. The following demo script should be run on a development instance in a new test database set to use the SIMPLE recovery model.
SQL Server 2016 introduced serial batch mode processing and aggregate pushdown. Columnstore storage. To understand this, it is necessary to first review how columnstore storage works at a high level: A compressed row group contains a column segment for each column. to give {11, 12, 13}, then rebasing at 11 to give {0, 1, 2}.
The following script should be run on a development SQL Server instance in a new test database set to use the SIMPLE or BULK_LOGGED recovery model. The calculated row size (61 bytes) differs from the true row storage size (60 bytes) by the extra one byte of internal metadata present in the insert stream.
This article was originally published on the NDC 2016 Blog. It turned out that an RPC call to a legacy service, whose response value was stored in the 72nd column in the database table, wasn't even necessary. Because you're on the outside of the monolith, your database technology constraints also disappear.
In this configuration, the AMI and boot is paravirt (PV), the kernel is making hypercalls instead of privileged instructions, and the system is using paravirt network and storage drivers. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. The AMI and boot are now HVM.
The Green Web Foundation maintains an ever-growing database of web hosts who are either wholly powered by renewable energy or are at least committed to being carbon neutral. An obvious metric here is CPU usage, but memory usage and other forms of data storage also play their part. These include data transfer (i.e.
At the time of the last Confluence run, the gap had stretched to nearly 1000 APIs, doubling since 2016. Chrome has missed several APIs for 3+ years: Storage Access API. The data captured by MDN Browser Compatibility Data Respository and the caniuse database is often partial and sometimes incorrect. Where Chrome Has Lagged.
Durability: “In database systems , durability is the ACID property which guarantees transactions that have committed will survive permanently. Microsoft SQL Server Database Engine Input/Output Requirements. Device level flushing may have an impact on your I/O caching, read ahead or other behaviors of the storage system.
What if we use ClickHouse (which is a columnar analytical database) as our main datastore? Well, typically, an analytical database is not a replacement for a transactional or key/value datastore. Although such databases can be very efficient with counts and averages, some queries will be slow or simply non existent. Processed 4.15
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content