This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Expanding the AWS Cloud—An AWS Region is coming to South Africa! The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. In 2015, we expanded our presence in the country, opening an AWS office in Johannesburg.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. Observability platforms are becoming essential as the complexity of cloud-native architectures increases. But by 2015, it was more common to split up monolithic applications into distributed systems.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
A brief history of IPC at Netflix Netflix was early to the cloud, particularly for large-scale companies: we began the migration in 2008, and by 2010, Netflix streaming was fully run on AWS. Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments.
A region in South Korea has been highly requested by companies around the world who want to take full advantage of Korea’s world-leading Internet connectivity and provide their customers with quick, low-latency access to websites, mobile applications, games, SaaS applications, and more.
Know anyone who needs cloud? I wrote Explain the Cloud Like I'm 10 just for them. skamille : I worry that the cloud is just moving us back to a world of proprietary software. BrentToderian : What city went from 14% of all trips by bike in 2001, to 22% by 2012, then leaped to 30% in 3 years by 2015, & 35% by 2018?
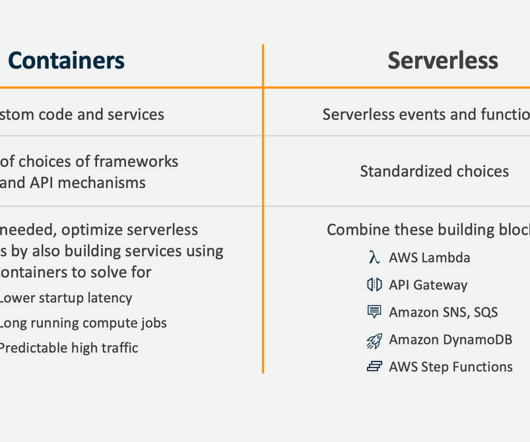
I don’t advocate “Serverless Only”, and I recommended that if you need sustained high traffic, low latency and higher efficiency, then you should re-implement your rapid prototype as a continuously running autoscaled container, as part of a larger serverless event driven architecture, which is what they did. Finally, what were they building?
It's an exciting time for developments in computer performance, not just for the BPF technology (which I often [write about]) but also for processors with 3D stacking and cloud vendor CPUs (e.g., Ford, et al., “TCP on Upcoming Sapphire Rapids CPUs,” [link] Oct 2020 - [Liu 20] Linda Liu, “Samsung QVO vs EVO vs PRO: What’s the Difference?
This enables customers to serve content to their end users with low latency, giving them the best application experience. In 2011, AWS opened a Point of Presence (PoP) in Stockholm to enable customers to serve content to their end users with low latency. In 2014 and 2015 respectively, AWS opened offices in Stockholm and Espoo, Finland.
biolatency Disk I/O latency histogram heat map. runqlat CPU scheduler latency heat map. This is currently part of our FlameCommander UI, which also runs flame graphs across the cloud. For a more recent example, I wrote cachestat(8) while on vacation in 2014 for use on the Netflix cloud, which was a mix of Linux 3.2
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. released in December 2015. Overall, it performs better for random writes and operational databases with low latency and transactional workloads due to its B-tree structure and well-ordered data structure.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. That chance encounter, coupled with the Netflix's fault-tolerant cloud, gave me enough confidence to suggest trying tsc in production as a workaround for the issue. We ended up setting it in the BaseAMI for all cloud services.
Expanding the Cloud - The AWS GovCloud (US) Region. This new region, which is located on the West Coast of the US, helps US government agencies and contractors move more of their workloads to the cloud by implementing a number of US government-specific regulatory requirements. Cloud First. Cloud Firstâ?? Comments ().
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Proceedings of the Third ACM Symposium on Cloud Computing. Beresford, and Boerge Svingen. Online event processing. Communications of the ACM 62.5
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Proceedings of the Third ACM Symposium on Cloud Computing. Beresford, and Boerge Svingen. Online event processing. Communications of the ACM 62.5
I previously wrote about Netflix in [2015] and [2016], and if you are interested in what it's like to work here, I already covered much in those posts. We're on the EC2 cloud, which has great scalability, and our own cloud architecture of microservices is also designed for scalability. Time flies! Little to no bureaucracy.
photo by Adrian I gave a talk at Monitorama in Portland Oregon in June, which set out the idea that carbon is just another metric to monitor, and that in a few years most of the monitoring and performance tuning tools are going to be reporting and optimizing for carbon alongside latency, throughput, availability and cost.
It's an exciting time for developments in computer performance, not just for the BPF technology (which I often [write about]) but also for processors with 3D stacking and cloud vendor CPUs (e.g., Ford, et al., “TCP on Upcoming Sapphire Rapids CPUs,” [link] Oct 2020 - [Liu 20] Linda Liu, “Samsung QVO vs EVO vs PRO: What’s the Difference?
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. That chance encounter, coupled with the Netflix's fault-tolerant cloud, gave me enough confidence to suggest trying tsc in production as a workaround for the issue. We ended up setting it in the BaseAMI for all cloud services.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. That chance encounter, coupled with the Netflix's fault-tolerant cloud, gave me enough confidence to suggest trying tsc in production as a workaround for the issue. We ended up setting it in the BaseAMI for all cloud services.
biolatency Disk I/O latency histogram heat map 5. runqlat CPU scheduler latency heat map 10. This is currently part of our FlameCommander UI, which also runs flame graphs across the cloud. As an extreme example, I wrote cachestat(8) while on vacation in 2014 for use on the Netflix cloud, which was a mix of Linux 3.2
Released just four years ago in 2015, Scylla has averaged over 220% year-over-year growth in popularity according to DB-Engines. ScyllaDB Cloud vs. ScyllaDB On-Premises. Most Popular Cloud Providers for ScyllaDB. ScyllaDB offers significantly lower latency which allows you to process a high volume of data with minimal delay.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. They can be also useful when a single value of demand is desired, such as for a cloud auto scaling rule. I've never seen an explanation.
Devices and networks have evolved too: Alex Russell @slightlylate An update on mobile CPUs and the Performance Inequality Gap: Mid-tier Android devices (~$300) now get the single-core performance of a 2014 iPhone and the multi-core perf of a 2015 iPhone. The cheapest (high volume) Androids perform like 2012/2013 iPhones, respectively.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. In real-life world, most products aren’t even close: an average bundle size today is around 400KB , which is up 35% compared to late 2015. On a middle-class mobile device, that accounts for 30-35 seconds for Time-To-Interactive.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content