This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. It shouldn't be 10%, unless it's cache effects. Back-end servers. Don't blame the straw, in this case, don't blame the frame pointers.
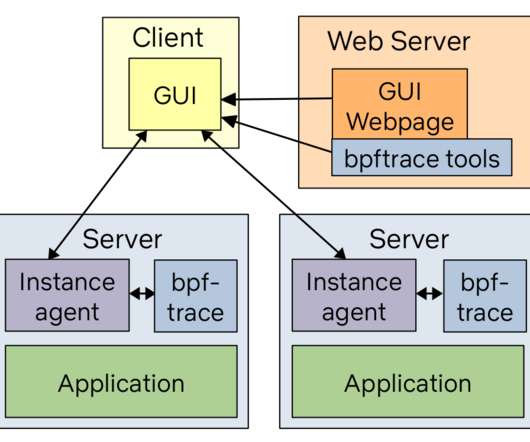
cachestat File system cache statistics line charts. The architecture is: While the bpftrace binary is installed on all the target systems, the bpftrace tools (text files) live on a web server and are pushed out when needed. execsnoop New processes (via exec(2)) table. opensnoop Files opened table. ext4slower Slow filesystem I/O table.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
In traditional row-mode execution plans, SQL Server may introduce a Bitmap operator as part of performing early semi join reduction before a parallel hash or merge join. There have been major improvements since the first appearance of the batch mode execution engine in SQL Server 2012. Background. The Query Optimizer. Bitmap Choice.
I've been teaching and writing about common SQL Server mistakes for many years. This article will expand on my previous article and point out how these apply to SQL Server , Azure SQL Database , and Azure SQL Managed Instance. SQL Server Agent alerts. This situation applies to on-premises SQL Server and IaaS. Statistics.
Without this guarantee, SQL Server might add index rows that are not sorted correctly, which would not be good. For INSERT.SELECT , SQL Server makes its own determination whether to ensure rows are presented to the Clustered Index Insert operator in key order or not. DMLRequestSort Conditions.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. mid-priced Androids were slightly faster than 2014's iPhone 6. The Moto G4 , for example. The cheapest (high volume) Androids perform like 2012/2013 iPhones, respectively.
If you put your whole website on CDN, technically you don’t need a large number of server infrastructure and CMS licenses. They often get blindsided by vendor’s pitch and end-up making decision based on some fancy demos (see my post from 2014 on Adobe AEM ). Circa 2014, I was working with a big Japanese automotive brand in Australia.
A close monitoring of the hardware enthusiast community, including many of the most respected hardware analysts and reviewers paints an even more dire picture about Intel in the server processor space. Despite all of this, Intel is not going to lose their entire server processor business any time soon. So, what has changed my mind?
SQL Server 2016 ‘It Just Runs Faster’ A bold statement that any SQL Server professional can stand behind with confidence. Try SQL Server 2016 Today. The SQL Server Development team tasked several individuals with scalability improvements and real world testing patterns. – [link]. Auto-soft NUMA. . ….
SQL Server 2016 changes the internal design to (CheckScanner), applying no lock semantics and a design similar to those used with In-Memory Optimized (Hekaton) objects, allowing DBCC operations to scale far better than previous releases. Ryan Stonecipher – Principle SQL Server Software Engineer. SQL Server. set nocount on.
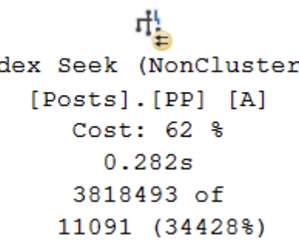
SQL Server2014 SP2 and later produce runtime (“actual”) execution plans that can include elapsed time and CPU usage for each execution plan operator (see KB3170113 and this blog post by Pedro Lopes). SQL Server makes some timing adjustments in parallel plans to promote consistency, but they are not perfectly implemented.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory.
These AMD EPYC processors have a number of advantages for SQL Server workloads, as I will explain in this article. This 14nm first-generation AMD EPYC 7551 processor has 32 cores and 64 threads, and it works in one or two-socket servers. The L3 cache size is 64MB. The L3 cache size is 64MB. AMD EPYC 7551 Details.
It can be activated from SQL Server 2008 to 2014 inclusive using documented trace flag 610. From SQL Server 2016 onward, FastLoadContext is enabled by default ; the trace flag is not required. For more background, see the Data Performance Loading Guide and the Tiger Team notes on the behaviour changes for SQL Server 2016.
Figure 1 depicts a simple queue where tasks arrive, are optionally queued in the buffers to the left if the server is already busy, are then serviced one at a time in the circular server, and depart to the right. For the previous cache miss buffer example, the 32-buffer answer is minimal for 100-ns average miss latency.
In this blog, we’ll provide a comparison between MariaDB vs. MySQL (including Percona Server for MySQL ). Introduction: MariaDB vs. MySQL The goal of this blog post is to evaluate, at a higher level, MariaDB vs. MySQL vs. Percona Server for MySQL side-by-side to better inform the decision making process.
To this end, having a solid caching strategy can make all the difference for your visitors. ?? How is your knowledge of caching and Cache-Control headers? That being said, more and more often in my work I see lots of opportunities being left on the table through unconsidered or even completely overlooked caching practices.
cachestat File system cache statistics line charts 7. The architecture is: While the bpftrace binary is installed on all the target systems, the bpftrace tools (text files) live on a web server and are pushed out when needed. execsnoop New processes (via exec(2)) table 2. opensnoop Files opened table 3. It depends on the tool.
How It Works: XEvent Output and Visualization SQL Server Management Studio Provides–“XE Profiler” Use the SSMS XEvent Profiler. Using SQL Server Management Studio (SSMS) and storing the events in a table requires reading the events, streaming to table storage followed by an order by event sequence query. TSQL Sample Session.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content