This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
During the recession of 2008, they experienced firsthand how fast money and assets can vanish. Below, we outline some proactive steps for achieving cost efficiency and maintaining performant database environments amid a turbulent economy: 1. Here we are, with an economic downturn looming globally and some countries facing a recession.
It progressed from “raw compute and storage” to “reimplementing key services in push-button fashion” to “becoming the backbone of AI work”—all under the umbrella of “renting time and storage on someone else’s computers.” ” (It will be easier to fit in the overhead storage.)
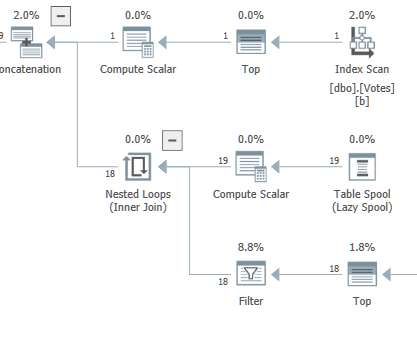
It comes set to SQL Server 2008 compatibility (level 100), but we will start with a more modern setting of SQL Server 2017 (level 140): ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 140 ; The tests were performed on my laptop using SQL Server 2019 CU 2. This will provide distinct values with great efficiency.
MariaDB is a popular SQL open source relational database management system that originated as a fork of MySQL after MySQL was acquired by Sun Microsystems in 2008 and later Oracle in 2010. Some key features and functionalities of MySQL include: Support for multiple storage engines, allowing users to choose what is suitable for their needs.
From 2008 to 2013, the Chrome project was based on WebKit, and a growing team of Chrome engineers began to contribute heavily "upstream." This arrangement is, however, maximally efficient in terms of staffing, as it means less expertise is duplicated across teams, requiring fewer engineers.
References I've reproduced the references from my SREcon22 keynote below, so you can click on links: [Gregg 08] Brendan Gregg, “ZFS L2ARC,” [link] , Jul 2008 [Gregg 10] Brendan Gregg, “Visualizations for Performance Analysis (and More),” [link] , 2010 [Greenberg 11] Marc Greenberg, “DDR4: Double the speed, double the latency?
Nowadays, there are three built-in tracers that you should know about: - **ftrace**: since 2008, this serves many tracing needs, and has been enhanced recently with hist triggers for custom histograms. Appliance manufacturers hire kernel engineers to develop custom features, including storage appliances. It's the official profiler.
Jul 4 - Leases: An efficient fault-tolerant mechanism for distributed file cache consistency , Gray, Cary, and David Cheriton, Vol. Aug 24 - The Five-Minute Rule Ten Years Later, and Other Computer Storage Rules of Thumb , Jim Gray and Goetz Graefe, ACM SIGMOD Record 26 (4): 63â??68, Goetz Graefe, ACM Queue 6(4): 40-52 (2008).
However, ClickHouse is super efficient for timeseries and provides “sharding” out of the box (scalability beyond one node). Although such databases can be very efficient with counts and averages, some queries will be slow or simply non existent. Inserts are efficient for bulk inserts only. created_utc?? ?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content