This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ready to transition from a commercial database to open source, and want to know which databases are most popular in 2019? Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy?
PostgreSQL is an open source object-relational database system that has soared in popularity over the past 30 years from its active, loyal, and growing community. For the 2nd year in a row, PostgreSQL has kept the title of #1 fastest growing database in the world according to the DBMS of the Year report by the experts at DB-Engines.
During the recession of 2008, they experienced firsthand how fast money and assets can vanish. Below, we outline some proactive steps for achieving cost efficiency and maintaining performant database environments amid a turbulent economy: 1. With proper database management, it’s possible to cut your bills in half.
But my original version was slow, because I queried the database for every page load. Then in 2008, Google issued a code yellow for application speed, and I was the code yellow lead for Google Docs. Of course writes were much less common than reads, so I added a caching layer for reads, and that did the trick.
Introduction to policy-based management Policy-Based Management feature allows database professional in defining the best practices, standards for SQL Server and database related configurations. It is available from SQL Server 2008 onwards. Here, you can use […].
MongoDB is a schemaless database that is extremely flexible. MongoDB does not require any ALTER statement to modify the schema of a collection, like in a relational database. When you create a collection, you don’t have to specify a structure in advance, providing field names and data types.
s announcement of Amazon RDS for Microsoft SQL Server and.NET support for AWS Elastic Beanstalk marks another important step in our commitment to increase the flexibility for AWS customers to use the choice of operating system, programming language, development tools and database software that meet their application requirements.
In 2008, AWS opened a point of presence (PoP) in Hong Kong to enable customers to serve content to their end users with low latency. Beyond running their web properties and applications, Next Digital also uses Amazon RDS (database), Amazon ElastiCache (caching), and Amazon Redshift (data warehousing).
One of the services that is very successful in driving innovation at our customers in this context is Amazon RDS , the Relational Database Service. Amazon RDS removes the headaches of running a relational database service reliably at scale, allowing Amazon RDS customers to focus on innovation for their customers. hands freeÃ?
When Netflix went from less than a million subscribers to over 9 million in 2008, it had a critical decision to sustain that gold rush of new subscriptions without affecting the existing users. While still dealing with database corruption, the company had to rapidly scale the platform to accommodate more users.
The images from the 2008 TNW Conference have travelled around the world in my Animoto demo: This year TNW is showing that it is not just a conference for talkers but also for builders by organizing a massive Hackaton in the two days running up to the conference. Job Openings in AWS - Senior Leader in Database Services.
Many database administrators find themselves having to support instances of SQL Server Reporting Services (SSRS), or at least the backend databases that are required for SSRS. SSRS 2008 brought that component into the reporting service module. Unlike the system database tempdb, ReportServerTempDB is not recreated at startup.
If so, you may have heard about the Azure SQL Database DTU calculator , and you may have also read about how it has been reverse engineered by Andy Mallon. Database – Log Bytes Flushed/sec. When I looked through the SentryOne database, I found that 3 of the 4 counters were already being captured by default.
I will be using the 50GB Stack Overflow 2013 database , but any large table with a low number of distinct values would do. The Stack Overflow 2013 database comes without nonclustered indexes to minimize download time. This follow-up post revisits the question for SQL Server 2019, using a larger number of rows. Test Environment.
Here are the laurels given by the editors: Debuting in November 2008, Amazons entry into the CDN market quickly became a major player. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Job Openings in AWS - Senior Leader in Database Services. Amazon DynamoDB â?? Expanding the Cloud â??
Still, if you stack a bunch of high-transaction databases on there, checkpoint processing can get pretty sluggish. Change the Target Recovery Time of a Database. STATE = START ; I marked the time that I changed each database, and then analyzed the results from the Extended Events data using a query published in the original tip.
Let’s look at some examples using a fresh database. I happen to be using SQL Server 2019 CU16 but the details I’ll describe haven’t materially changed since partition level lock escalation was added to SQL Server 2008. USE master ; -- Create a new test database. -- COLLATE clause only to remind people it exists.
In order to use Query Store and Extended Events, you have to configure them in advance – either enabling Query Store for your database(s), or setting up an XE session and starting it. [ dbid ] ) AS [ Database Name ] , REPLACE ( REPLACE ( LEFT ( t. [ SELECT TOP ( 50 ) DB_NAME ( t. [
For SQL Server 2008, 2012 and 2014 the trace flag behavior remains the same. Trace flag 2549 is used to change how DBCC sees the volume layout of the database. Trace flags 2562 and 2549 are documented in knowledgebase article: [link] and the blog post [link] highlights the SQL 2016 DBCC performance improvements.
“SQL Server 2016 running on the same hardware as SQL Server 2014, 2012, 2008, 2008 R2 or 2005 uses fewer resources and executes a wide range of workloads faster. SQL 2016 – It Just Runs Faster: -T1117 and -T1118 changes for TEMPDB and user databases. SQL 2016 – It Just Runs Faster: In-Memory Optimized Database Worker Pool.
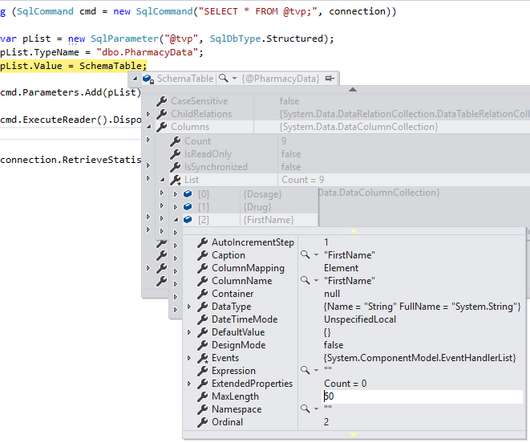
Table-valued parameters have been around since SQL Server 2008 and provide a useful mechanism for sending multiple rows of data to SQL Server, brought together as a single parameterized call. Where this really can make a difference is in cloud implementations where you are paying for more than just compute and storage resources.
And if I switch tabs to view a paper from 2008, then a song from 2008 could start up. To provide some coherence to the music, I decided to use Taylor Swift songs since her discography covers the time span of most papers that I typically read: Her main albums were released in 2006, 2008, 2010, 2012, 2014, 2017, 2019, 2020, and 2022.
Before we dive into the differences between MariaDB and MySQL, we will provide a thorough examination of each relational database management system (RDBMS). While originally designed to be a drop-in replacement for MySQL, it evolved into its own distinct database management system and is now maintained and supported by the MariaDB Foundation.
This article will expand on my previous article and point out how these apply to SQL Server , Azure SQL Database , and Azure SQL Managed Instance. When looking at backups, I check for recovery model and the current history of backups for each database. Azure SQL Database and Azure Managed Instance have managed backups.
Single-Socket Database Servers. AMD's biggest challenge is going to be convincing customers to actually buy AMD-platform servers, since Intel has been so dominant in the server market since the Nehalem architecture era back in 2008. AMD is not going to stand still and wait for Intel to catch up. Figure 4: AMD EPYC Roadmap.
Schütze, 2008. PS08] Optimal Targeting through Uplift Modeling, Portrait Software, 2008 [[link]. VL02] The True Lift Model – A Novel Data Mining Approach to Response Modeling in Database Marketing, V. Koren, 2008. [MA08] Introduction to Information Retrieval, C. Manning, P. Raghavan, H. Provost, T. Fawcett, 2013.
Transparent Data Encryption (TDE) is a feature that was introduced in SQL Server 2008 (and is also available for Azure SQL Database, Azure SQL Data Warehouse, and Parallel Data Warehouse) with the purpose of encrypting your data at rest. That is to ensure your database is encrypted at the file level.
The following script should be run on a development SQL Server instance in a new test database set to use the SIMPLE or BULK_LOGGED recovery model. These correspond directly to the new facilities added under trace flag 610 to SQL Server 2008, then changed to be on by default from SQL Server 2016 onward.
This made it easier for database professionals to make the case for a hardware upgrade, and made the typical upgrade more worthwhile. You might be asking why you should care about all of this as a SQL Server Database professional? Figure 2: AMD EPYC Rome Processor. How is This Relevant for SQL Server? There are many reasons!
In 2008 or so, when data scientist emerged as a job title, it was widely ridiculed as a nonjob: the thought that people who just worked with data could be scientists, or employ the rigors of their time-honored methods, was literally laughable in many circles. To do so, we borrow metaphors from roles in other industries.
It can be activated from SQL Server 2008 to 2014 inclusive using documented trace flag 610. The test table schema is such that 130 rows can fit on a single 8KB page when row versioning is off for the database. The internal facility that enables these cases is called FastLoadContext.
It took a lot of challenging the "why" on those specific portions of the value stream before they understood how a simple shared database would eliminate lots of no-value-added inventory control steps.
What if we use ClickHouse (which is a columnar analytical database) as our main datastore? Well, typically, an analytical database is not a replacement for a transactional or key/value datastore. Although such databases can be very efficient with counts and averages, some queries will be slow or simply non existent. Processed 4.15
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content