This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Back then, Amazon was ~2% of its size today, and was growing faster than traditional IT systems could support. We had to rethink everything previously known about building scalable systems. Storage was one of our biggest pain points, and the traditional systems we used just weren’t fitting the needs of the Amazon.com retail business.
Complex information systems fail in unexpected ways. Observability gives developers and system operators real-time awareness of a highly distributed system’s current state based on the data it generates. With observability, teams can understand what part of a system is performing poorly and how to correct the problem.
Understanding sustained memory bandwidth in these systems starts with assuming 100% utilization and then reviewing the factors that get in the way (e.g., This requires a completely different approach to modeling the memory system — one based on Little’s Law from queueing theory.
Around 2005 or 2006, it wasn’t so bad. From Udi Dahan's free Distributed Systems Design Fundamentals video course Semantic interoperability The true challenge of non-homogenous networks lies in semantic interoperability. Consider for a moment a software system for a hospital emergency room. How do we integrate these two systems?
It was 2005, and I felt like I was in the eye of a hurricane. However, I was doing training and consulting for Sun, helping their customers with system administration and performance. Another difference was that there were few roles in Australia for engineers in 2005, unlike the US. You can't make this stuff up. tools (2006).
Werner Vogels weblog on building scalable and robust distributed systems. Amazon S3 is much more than just storage; the network and distributed systems infrastructure to ensure that content can be served fast and at high rates without customers impacting each other, is amazing. All Things Distributed. Comments ().
Combined with the rise of data warehouse workloads, where there is often significant redundancy in the values stored in columns, and database models based on column oriented storage took off. The first practical modern implementation is probably C-Store by Stonebraker, et al.
Werner Vogels weblog on building scalable and robust distributed systems. 2005: Fiona Apple , Extraordinary Machine. I might have picked Fiona Apple again, but she already has a 2005 spot. All Things Distributed. An Album for Each Year - 2012 Version. By Werner Vogels on 22 December 2012 06:00 PM. Comments (). Same for Eminem.
The queues component of our methodology comes from Performance Monitor counters, which provide a view of system performance from a resource standpoint.". However, some seem to have missed Davidson's point regarding the importance of resources and rely almost entirely on waits to present a picture of query performance and system health.
In 2005 Stonebraker et al. Although, this article dates before systems such as Apache Kafka, Amazon Kinesis, Apache Spark, Apache Storm, etc. published a paper that outlined 8 key requirements for stream processing architecture. These key requirements can be easily translated into building blocks of stream processing architecture.
It's amazing to recall that it was even possible to virtualize x86 before processors had hardware-assisted virtualization (Intel VT-x and AMD-V), which were added in 2005 and 2006. They were being launched piecemeal, improving performance of pre-Nitro systems. AWS has a name for their Bare Metal platform: it's the "Nitro system".
On design systems, CSS/JS and UX. It looked realistic in 2004 but the rule was already irrelevant by 2005. The last subject I chose (ecodesign) is also critical from a systemic point of view with major potential consequences on our personal and professional lives. With Carie Fisher, Stefan Baumgartner and so many others.
Since SQL Server 2005, the trick of using FOR XML PATH to denormalize strings and combine them into a single (usually comma-separated) list has been very popular. In the SQL Server 2005 days, I would have offered this solution: SELECT DISTINCT UserID , Bands =. ( On my system, this adds a little over 11,000 rows: INSERT dbo.
The British Standards Institution (2005) defines inclusive design as : “The design of mainstream products and/or services that are accessible to, and usable by, as many people as reasonably possible. Design systems should be used not only to ensure branding and consistency, but accessibility, inclusivity, and understanding of code better.
From 1975 to 2005, our industry accomplished a phenomenal mission: In 30 years, we put a personal computer on every desk, in every home, and in every pocket. In 2005, however, mainstream computing hit a wall. The free lunch is over. Now welcome to the hardware jungle. iPad 2, Playbook, Kindle Fire, Nook Tablet) and smartphones (e.g.,
In “ How Photos of Your Kids Are Powering Surveillance Technology ,” The New York Times reported that One day in 2005, a mother in Evanston, Ill., joined Flickr. She uploaded some pictures of her children, Chloe and Jasper.
Most of this article represents an overview of the results published by retailers and researchers who built practical decision making and optimization systems combining abstract economic models with data mining methods. The most typical use cases for this problem are recommender systems, personalized search results ranking, and targeted ads.
With the goals of sharing, openness and mentoring, you’re in for some great articles about systems administration topics written by fellow sysadmins. Tune in each day for an article that explores the wide range of topics in system administration. It launched in 2005 and still has all of the calendars available online.
The fundamentals of row mode parallel execution haven’t changed since SQL Server 2005, so the following discussion is broadly applicable. A parallel query might start out requesting DOP 8, but be progressively downgraded to DOP 4, DOP 2, and finally DOP 1 due to a lack of system resources at that moment. MonthlyPosts AS. (
They are responsible for the implementation of database systems, ensuring proper communication between various web services, generating backend functionality, and more. Laravel also offers its own database migration system and has a robust ecosystem. Backend developers work with a wide range of libraries, APIs, web services, etc.
The problem is that this system has a default libc that has been compiled without frame pointers, so any stack walking stops at the libc layer, producing a partial stack that's missing the application frames. This is pretty common and usually goes unnoticed as the flame graph looks ok at first glance.
The system table sys.sysprocesses was replaced way back in SQL Server 2005 by a set of dynamic management views (DMVs), most notably sys.dm_exec_requests , sys.dm_exec_sessions , and sys.dm_exec_connections. We recommend that you use the current SQL Server system views instead. Why this is a problem.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
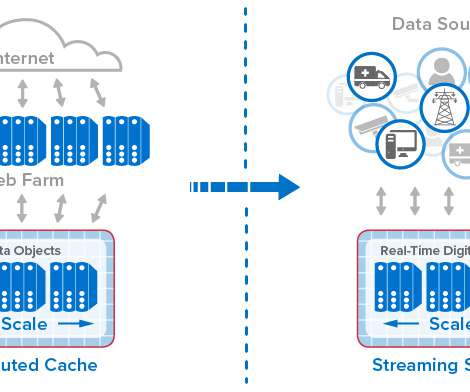
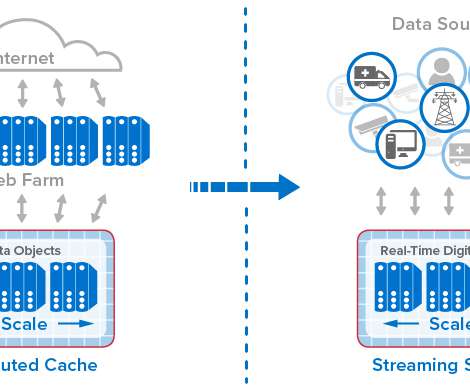
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. From Distributed Caches to Real-Time Digital Twins.
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. From Distributed Caches to Real-Time Digital Twins.
When I first joined ThoughtWorks in 2005, one of our core messages was to solve an “outer quadrant” problem first - something in the problem space that is difficult and complex. They went on to acknowledge that some of my colleagues had counseled them to do this some months before I started working with them. Quick wins” attack the margins.
Keep in mind that the vast majority of CMemThread objects (SQL 2005, 2008, 2008 R2, 2012, 2014, Azure DB and 2016) are not partitioned. Recommendation Unchanged: Prior to SQL Server 2016 enable –T8048 on larger systems. The three types of CMemThread partitioning and associated details are described in my previous post: [link].
The system needs to be highly reliable because even just a little downtime can alienate loyal customers. Google Maps started life in 2005 as a desktop application for getting from point A to point B. Two particularly relevant patterns are Efficiency Enables Evolution and Higher Order Systems Create New Sources of Worth.
How many different booking systems have your frequent flier numbers, know that you prefer an aisle to a window, and know that you prefer a vegetarian meal on long-haul flights? And how much of that has changed since you last edited your profile in each of those systems? We have a lot of redundant data. We lug this data around with us.
Understanding sustained memory bandwidth in these systems starts with assuming 100% utilization and then reviewing the factors that get in the way (e.g., This requires a completely different approach to modeling the memory system — one based on Little’s Law from queueing theory.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
The ecosystem strategy takes this even further, combining unrelated capabilities under one roof (eBay buying Skype in 2005, SAP developing HANA in 2010, Facebook buying Oculus in 2014), often justifiable if only because digital commerce is still in its infancy and nobody is really sure what's going to work and what's not.
It was 2005, and I felt like I was in the eye of a hurricane. However, I was doing training and consulting for Sun, helping their customers with system administration and performance. Another difference was that there were few roles in Australia for engineers in 2005, unlike the US. You can't make this stuff up.
It's amazing to recall that it was even possible to virtualize x86 before processors had hardware-assisted virtualization (Intel VT-x and AMD-V), which were added in 2005 and 2006. They were being launched piecemeal, improving performance of pre-Nitro systems. AWS has a name for their Bare Metal platform: it's the "Nitro system".
Therefore, there might be cases where your system could experience a downtime during the migration process. For example, Akamai introduced ASI in 2005, which became the standard for building new websites. How does vendor lock-in occur? Akamai tried to convince many users to use this new framework.
Therefore, there might be cases where your system could experience a downtime during the migration process. Not only that, but there can be cases where a piece of your application could break during the migration process that could take a long time to get back running.How does vendor lock-in occur?
Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation.
Consumer operating systems were also a big part of the story. That job was effectively encapsulated in the operating system. Big data, web services, and cloud computing established a kind of internet operating system. Large language models (LLMs) and other AI systems are attempting to automate thought, he wrote.
Durability: “In database systems , durability is the ACID property which guarantees transactions that have committed will survive permanently. For example, if a flight booking reports that a seat has successfully been booked, then the seat will remain booked even if the system crashes.” – [link]. The Back Story.
By 2005, the tech economy had bounced back on its own. The decision is simply whether to cut (based on sales forecasts) and when to cut (systemically or opportunistically to boost FCF for the coming quarter). In the years immediately following the dot-com meltdown, there was more tech labor than there were tech jobs.
Linux load averages are "system load averages" that show the running thread (task) demand on the system as an average number of running plus waiting threads. This measures demand, which can be greater than what the system is currently processing. then your system is idle. - cat /proc/loadavg. 42/3411 43603. 42/3411 43603.
In 2005, in “ What is Web 2.0? ,” I made the case that the companies that had survived the dotcom bust had all in one way or another become experts at “harnessing collective intelligence.” Yet many of the most pressing risks are economic , embedded in the financial aims of the companies that control and manage AI systems and services.
Big companies] create all these systems and processes - and then end up with a very small percentage of people who are supposed to solve complex problems, while the other 98% of people just execute." Wall Street Journal, 24 December 2007. They are anathema to businesses with financing that demands precise control.
Back in 2005, the W3C pointed out that third party services had demonstrated that most captcha services could be defeated with 88%-100% accuracy by using some simple OCR. In particular, visitors who suffer from blindness, dyslexia or low vision will struggle greatly with a captcha system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content