This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Storage was one of our biggest pain points, and the traditional systems we used just weren’t fitting the needs of the Amazon.com retail business. When we took a hard look at our storage for the Amazon ecommerce web site in 2005, we realized that the majority of our data needed an object (or key-value) store.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. For example, in 2005, Dynatrace introduced a distributed tracing tool that allowed developers to implement local tracing and debugging. Observability is made up of three key pillars: metrics, logs, and traces.
Not everybody agreed that the "N-ary Storage Model" (NSM) was the best approach for all workloads but it stayed dominant until hardware constraints, especially on caches, forced the community to revisit some of the alternatives. A Decomposition Storage Model , George P. Copeland and Setrag N.
As some of you may remember I was pretty excited when Amazon Simple Storage Service (S3) released its website feature such that I could serve this weblog completely from S3. I have regenerated all pages since 2005, the pages before that can be found in the "/historical" section. Driving Storage Costs Down for AWS Customers.
It's amazing to recall that it was even possible to virtualize x86 before processors had hardware-assisted virtualization (Intel VT-x and AMD-V), which were added in 2005 and 2006. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. . --> Remember the original VMware x86 hypervisor from 1998?
I founded Instant Domain Search in 2005 and kept it as a side-hustle while I worked on a Y Combinator company (Snipshot, W06), before working as a software engineer at Facebook. Since we don’t need to run real-time queries on the data, we stream it into Google BigQuery’s streaming API for storage. We still have a lot of work to do!
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers.
In the not too distant past, storage was limited and expensive. As recently as 1980, 1 megabyte of disk storage cost $200. Storage capacity is now so abundant and compact that you can record every voice conversation you’ll ever have in a device that can fit into the palm of your hand. But this is no longer the case.
It's amazing to recall that it was even possible to virtualize x86 before processors had hardware-assisted virtualization (Intel VT-x and AMD-V), which were added in 2005 and 2006. But not all workloads: some are network bound (proxies) and storage bound (databases). ## 5. . --> Remember the original VMware x86 hypervisor from 1998?
As the administrator of a SQL Server 2005 installation, you will find that visibility into the SQL Server I/O subsystem has been significantly increased.
Device level flushing may have an impact on your I/O caching, read ahead or other behaviors of the storage system. Neal, Matt, and others from Windows Storage, Windows Azure Storage, Windows Hyper-V, … validating Windows behaviors. · Any storage device that can survive a power outage. Starting with the Linux 4.18
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






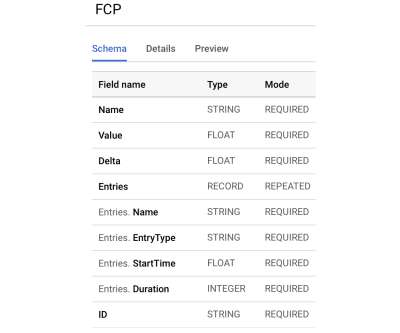
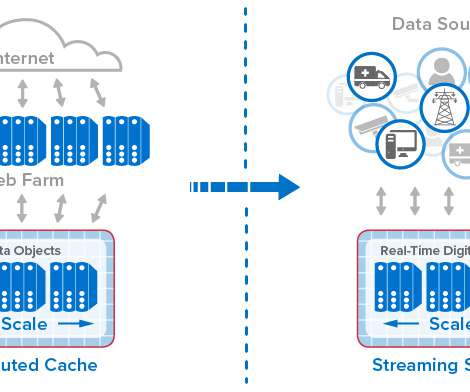
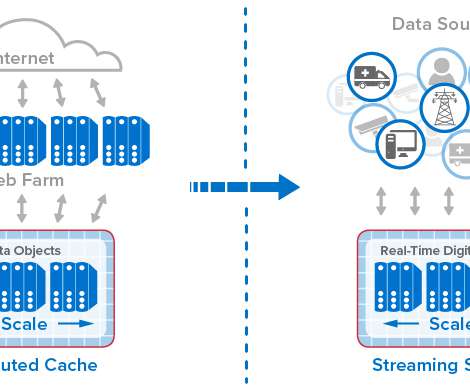










Let's personalize your content