

Observability platform vs. observability tools
Dynatrace
DECEMBER 22, 2021
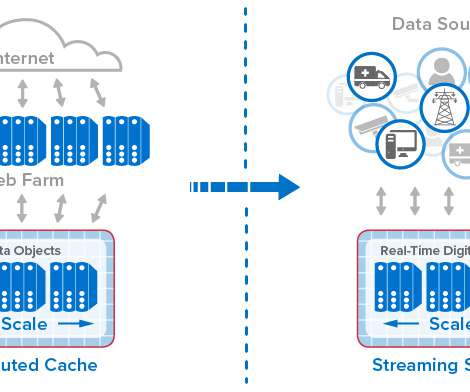
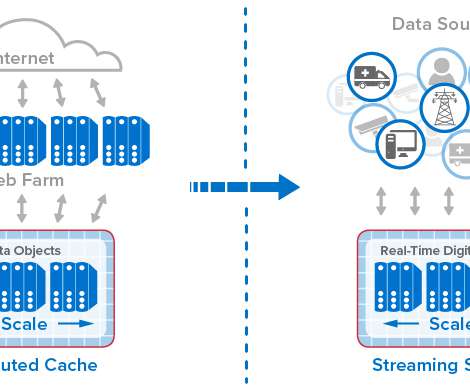
For example, in 2005, Dynatrace introduced a distributed tracing tool that allowed developers to implement local tracing and debugging. A database could start executing a storage management process that consumes database server resources. The case for an integrated observability platform.












Let's personalize your content