This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Throughout the web’s history, static websites have always been a popular option due to their simplicity, scalability, and security. During the 90s, we saw two content management systems for static sites — Microsoft FrontPage in 1996 and Macromedia Dreamweaver in 1997. Aug 31 & Sep 1, 2021. Jump to the workshop ?.
The term site reliability engineering first came into existence at Google in 2003 when a site reliability team was created. To think about it another way, site reliability engineering is where the traditional IT role, or system administration role, and DevOps meet. At that time, the team was made up of software engineers.
Werner Vogels weblog on building scalable and robust distributed systems. 2003: Linkin Park, Meteora. All Things Distributed. An Album for Each Year - 2012 Version. By Werner Vogels on 22 December 2012 06:00 PM. Comments (). About 5 years ago I joined a challenge to list "a favorite album for every year of your life."
Coupled with stateless application servers to execute business logic and a database-like system to provide persistent storage, they form a core component of popular data center service archictectures. Why are developers using RInK systems as part of their design? We’ve seen similar high marshalling overheads in big data systems too.)
As with the previous guides as an Intel employee (#IAMINTEL) the examples are taken from a MySQL 8 on Linux on Intel system and the approach is the same for whatever system you are testing although some of the settings you see may be different. System Setup: CPU, Memory and I/O Configuration. library file “libmysqlclient.so.20”
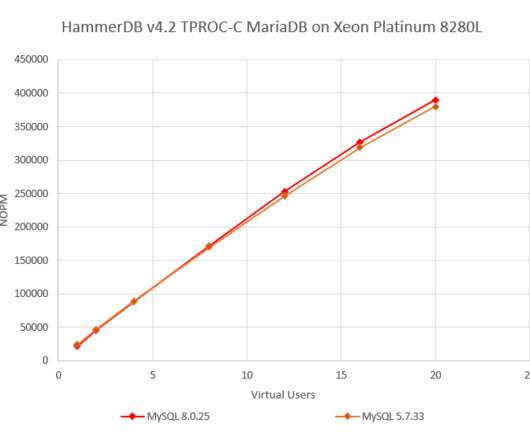
One of the most important concepts in analysing database performance is that of understanding scalability. When a system ‘scales’ it is able to deliver higher levels of performance proportional to the system resources available to it. In this example, we will compare MySQL 5.7.33 and MySQL 8.0.25 and MySQL 5.7.33.
on Myths and Legends of High Performance Computing — it’s a somewhat light-hearted look at some of the same issues by the leader of the team that built the Fugaku system I mention below. HPCG is led by Japan’s RIKEN Fugaku system at 16 petaflops, which is 3% of it’s peak capacity. Next generation architectures will use CXL3.0
This post gives a HOWTO guide on system configuration for achieving top levels of performance with the HammerDB PostgreSQL TPC-C test. Firstly for system choice a 2 socket system is optimal for PostgreSQL OLTP performance at the time of writing. lc_messages = 'en_GB.UTF-8' # locale for system error message.
Build a more scalable, composable, and functional architecture for interconnecting systems and applications. Welcome to a new world of data-driven systems. Today, data needs to be available at all times, serving its users—both humans and computer systems—across all time zones, continuously, in close to real time.
Most of this article represents an overview of the results published by retailers and researchers who built practical decision making and optimization systems combining abstract economic models with data mining methods. The most typical use cases for this problem are recommender systems, personalized search results ranking, and targeted ads.
Vuser 1:1 Active Virtual Users configured Vuser 1:TEST RESULT : System achieved 1844256 NOPM from 4232155 PostgreSQL TPM Vuser 1:FINISHED SUCCESS ALL VIRTUAL USERS COMPLETE. hammerdbcli auto pgtime.tcl HammerDB CLI v4.4 Vuser 1:Test complete, Taking end Transaction Count. Running a single process pre-test.
This article Threads Done Right… With Tcl gives an excellent overview of these capabilities and it should be clear that to build a scalable benchmarking tool this thread performance and scalability is key. The agent directory contains the agent code to be run on the system under test to gather the CPU utilisation information.
Breakaway opportunities tend also to be highly sensitive to non-functional requirements, such as performance, scalability and security. They create all these systems and processes – and then end up with a very small percentage of people who are supposed to solve complex problems, while the other 98% of people just execute.
Werner Vogels weblog on building scalable and robust distributed systems. I am pretty sure some if not all of these papers deserved to be elected to the hall of fame of best papers in distributed systems. Feb 11 - A Survey of Rollback-Recovery Protocols in Message-Passing Systems , E. All Things Distributed. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. Back-to-Basics Weekend Reading - Virtualizing Operating Systems. This weekends back-to-basics reading is on operating system virtualization. All Things Distributed. By Werner Vogels on 20 July 2012 12:00 PM. Comments (). Malo, France.
Photo by Adrian I spent six years at Cambridge Consultants, building some interesting systems, managing our Sun workstations and learning a lot, but by then Sun had opened a sales office across the street, and I wanted to find out what they were going to release next, before everyone else.
Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content